TensorFlow 中的人工神经网络
在本文中,我们将看到 ANN 的一些基础知识和人工神经网络的简单实现。 Tensorflow 是一个强大的机器学习库,用于创建模型和神经网络。
那么,在我们开始之前,什么是人工神经网络?这是人工神经网络的一个简单而清晰的定义。长话短说,人工神经网络是一种模仿人脑从一些关键特征中学习并在现实世界中进行分类或预测的技术。人工神经网络由许多神经元组成,与人脑中的神经元相比。
它旨在使计算机从小的洞察力和特征中学习,并使其自主地从现实世界中学习,并比人类更快地实时提供解决方案。
A neuron in an artificial neural network, will perform two operations inside it
- Sum of all weights
- Activation function
因此,一个基本的人工神经网络将采用以下形式,
- 输入层——从用户或客户端或服务器获取数据进行分析并给出结果。
- 隐藏层——该层可以有任意数量,这些层将分析输入,并以不同的偏差、权重和激活函数通过它们以提供输出
- 输出层——这是我们可以从神经网络获得结果的地方。

既然我们知道了神经网络的轮廓,现在我们将转向帮助神经网络从数据中正确学习的重要功能和方法。
Note: Any neural network can learn from the data but without good parameter values a neural network might not able to learn from the data correctly and will not give you the correct result.
决定我们的神经网络质量的一些特征是:
- 图层
- 激活函数
- 损失函数
- 优化器
现在我们将详细讨论它们中的每一个,
我们模型构建的第一阶段是:
Python3
# Defining the model
model = keras.Sequential([
keras.layers.Dense(32, input_shape=(2,), activation='relu'),
keras.layers.Dense(16, activation = 'relu'),
keras.layers.Dense(2, activation = 'sigmoid')
])Python
# Compilation of model
model.compile(optimizer='adam'
loss=a_loss_function
metrics=['metrics'])Python
# fitting the model
model.fit(train_data, train_label,
epochs=5, batch_size=32)Python
# Importing the libraries
import pandas as pd
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
from sklearn.model_selection import train_test_splitPython
# Importing the data
df = pd.read_csv('data.txt')Python
# split the data into train and test set
train, test = train_test_split(
df, test_size=0.2, random_state=42, shuffle=True)Python
# Constructing the input
x = np.column_stack((train.x.values, train.y.values))
y = train.color.valuesPython
# Defining the model
model = keras.Sequential([
keras.layers.Dense(4, input_shape=(2,), activation='relu'),
keras.layers.Dense(2, activation='sigmoid')
])
# Compiling the model
model.compile(optimizer='adam',
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
# fitting the model
model.fit(x, y, epochs=10, batch_size=8)Python
# Evaluating the model
x = np.column_stack((test.x.values, test.y.values))
y = test.color.values
model.evaluate(x, y, batch_size=8)Python
# Defining the model
model_better = keras.Sequential([
keras.layers.Dense(16, input_shape=(2,), activation='relu'),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dense(2, activation='softmax')
])
# Compiling the model
model_better.compile(optimizer='adam',
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
# Constructing the input
x = np.column_stack((train.x.values, train.y.values))
y = train.color.values
# fitting the model
model_better.fit(x, y, epochs=10, batch_size=8)图层
神经网络中的层非常重要,正如我们之前看到的,人工神经网络由 3 层组成:输入层、隐藏层、输出层。输入层由需要在神经网络内部分析的特征和值组成。基本上,这是一个将我们的输入特征读取到人工神经网络上的层。
隐藏层是这样一个层,当所有输入神经元将特征传递给具有权重和偏差的隐藏层时,隐藏层中的每个神经元都将汇总来自所有输入层的所有加权特征,并且应用激活函数将值保持在 0 和 1 之间,以便于学习。这里我们需要手动选择每一层的神经元数量,它必须是网络的最佳值。
这里真正的决策者是每一层之间的权重,最终将 0 到 1 的值传递给输出层。至此,我们已经看到了人工神经网络中每一层的重要性。 TensorFlow 中有很多类型的层,但我们会经常使用的一种是 Dense
syntax: tf.keras.layers.Dense()
这是一个全连接层,其中每个特征输入都将以某种方式与结果连接。
激活函数
激活函数是简单的数学方法,它使所有值都在 0 到 1 的范围内,以便机器在分析数据的过程中更容易学习数据。张量流支持多种激活函数。一些常用的功能是,
- 乙状结肠
- 热路
- 软最大
- 嗖嗖
- 线性
每个激活函数都有其特定的用例和缺点。但是在隐藏层和输入层中使用的激活函数是“Relu”,另一个对结果影响更大的是损失。
在这之后,我们可以看到TensorFlow中模型编译中的params,
Python
# Compilation of model
model.compile(optimizer='adam'
loss=a_loss_function
metrics=['metrics'])
损失
损失函数是创建神经网络时需要注意的非常重要的事情,因为神经网络中的损失函数将计算预测输出与实际结果之间的差异,并极大地帮助神经网络中的优化器更新其反向传播的权重。
TensorFlow 库支持的损失函数有很多,但常用的还有几个,
- 平均绝对值
- 均方误差
- 二元交叉熵
- 分类交叉熵
- 稀疏分类交叉熵
注意:同样,损失的选择完全取决于问题的类型和我们期望从神经网络得到的结果。
优化器
优化器是一个非常重要的东西,因为这是帮助神经网络改变反向传播权重的函数,这样实际结果和预测结果之间的差异将逐渐减小,并获得损失最小的点,并且该模型能够预测更准确的结果。
同样,TensorFlow 支持许多优化器,仅举几例,
- 梯度下降
- SDG——随机梯度下降
- 阿达格勒
- 亚当
编译模型后,我们需要将模型与数据集拟合以进行训练,
Python
# fitting the model
model.fit(train_data, train_label,
epochs=5, batch_size=32)
时代
时期只是整个数据集通过更新神经网络上的权重向前和反向传播的次数。通过这样做,我们可以在每个 epoch 中找到看不见的模式和信息,从而提高模型的准确性。
并且要处理神经网络的一些限制,例如过度拟合训练数据并且无法在看不见的数据上表现良好。这可以通过一些 dropout 层来解决,这意味着使层中的一些节点处于非活动状态,这会迫使神经网络中的每个节点更多地了解输入的特征,从而可以解决问题。
在 TensorFlow 中,在层中添加 dropout 实际上就是一行代码,
syntax: tf.keras.layers.Dropout(rate, noise_shape=None, seed=None, **kwargs )
如何使用 TensorFlow 训练神经网络:
第 1 步:导入库
我们将导入所需的库。
Python
# Importing the libraries
import pandas as pd
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
from sklearn.model_selection import train_test_split
第 2 步:导入数据
我们用于此示例的数据是使用 Numpy 随机生成的。您可以在此处下载数据。在该数据中,x 和 y 是坐标点,颜色特征是随机生成的目标值,它以二进制表示 Red – 1 , Blue – 0。
Python
# Importing the data
df = pd.read_csv('data.txt')

数据将如下所示:

第 3 步:拆分数据
现在我们要将数据集拆分为训练和测试拆分,以使用看不见的数据评估模型并检查其准确性。
Python
# split the data into train and test set
train, test = train_test_split(
df, test_size=0.2, random_state=42, shuffle=True)
第 4 步:构建输入
在这一步中,我们将构建我们需要输入网络的输入。为简单起见和模型的缘故,我们将把数据的两个特征堆叠到 x 中,将目标变量堆叠为 y。我们使用 numpy.column_stack() 来堆叠
Python
# Constructing the input
x = np.column_stack((train.x.values, train.y.values))
y = train.color.values
第 5 步:构建模型
现在我们要建立一个简单的神经网络来分类点的颜色,它有两个输入节点和一个隐藏层和一个输出层,带有 relu 和 sigmoid 激活函数,以及稀疏分类交叉熵损失函数,这将是一个全连接的前馈网络。
Python
# Defining the model
model = keras.Sequential([
keras.layers.Dense(4, input_shape=(2,), activation='relu'),
keras.layers.Dense(2, activation='sigmoid')
])
# Compiling the model
model.compile(optimizer='adam',
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
# fitting the model
model.fit(x, y, epochs=10, batch_size=8)
输出:

如果我们用看不见的数据评估模型,它会给出非常低的准确度,
Python
# Evaluating the model
x = np.column_stack((test.x.values, test.y.values))
y = test.color.values
model.evaluate(x, y, batch_size=8)
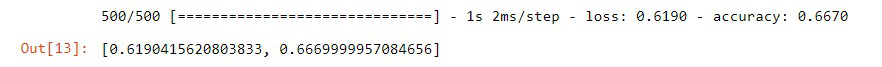
第 6 步:构建更好的模型
现在我们将通过一些额外的隐藏层和输出层中更好的激活函数“softmax”来改进模型,并构建一个更好的神经网络。
Python
# Defining the model
model_better = keras.Sequential([
keras.layers.Dense(16, input_shape=(2,), activation='relu'),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dense(2, activation='softmax')
])
# Compiling the model
model_better.compile(optimizer='adam',
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
# Constructing the input
x = np.column_stack((train.x.values, train.y.values))
y = train.color.values
# fitting the model
model_better.fit(x, y, epochs=10, batch_size=8)
输出:

第 7 步:评估模型
最后,如果我们对模型进行评估,我们可以清楚地看到模型对看不见的数据的准确率从 66 -> 85 提高了。因此我们建立了一个高效的模型。
