- Python Pandas-索引和选择数据(1)
- Python Pandas-索引和选择数据
- 使用 Pandas 索引和选择数据
- 使用 Pandas 索引和选择数据(1)
- pandas 按索引选择行 - Python (1)
- 在MongoDB中建立索引
- 在MongoDB中建立索引(1)
- 数据框按索引值选择行 - Python(1)
- 从数据框 pandas 中选择行 - Python (1)
- pandas 按索引选择列 - Python 代码示例
- pandas 按索引选择行 - Python 代码示例
- 数据框按索引值选择行 - Python代码示例
- 从数据框 pandas 中选择行 - Python 代码示例
- 获取索引号 pandas 数据框 - Python (1)
- 从数据框 python pandas 中选择 2 列 - Python (1)
- 如何使用另一个数据帧的索引选择数据帧的行?
- 获取索引号 pandas 数据框 - Python 代码示例
- 选择自定义索引 pandas - Python (1)
- 在 Pandas 中从多索引恢复到单索引数据帧(1)
- 在 Pandas 中从多索引恢复到单索引数据帧
- 从数据框 python pandas 中选择 2 列 - Python 代码示例
- pandas 数据框选择最后 n 列 - Python (1)
- 选择自定义索引 pandas - Python 代码示例
- 选择列 pandas - Python (1)
- pandas 按索引列 - Python (1)
- Python | Pandas数据比较与选择(1)
- Python| Pandas 中的数据比较和选择
- Python | Pandas数据比较与选择
- pandas 数据框选择最后 n 列 - Python 代码示例
📅 最后修改于: 2020-04-20 00:48:19 🧑 作者: Mango
在Pandas中建立索引:在Pandas中建立索引意味着仅从DataFrame中选择特定的数据行和数据列。索引编制可能意味着选择所有行和某些列,某些行和所有列,或每个行和列中的一些。索引编制也称为子集选择。

让我们看一些在Pandas中建立索引的示例。在本文中,我们使用“ nba.csv“文件下载CSV,请单击此处。
选择一些行和一些列
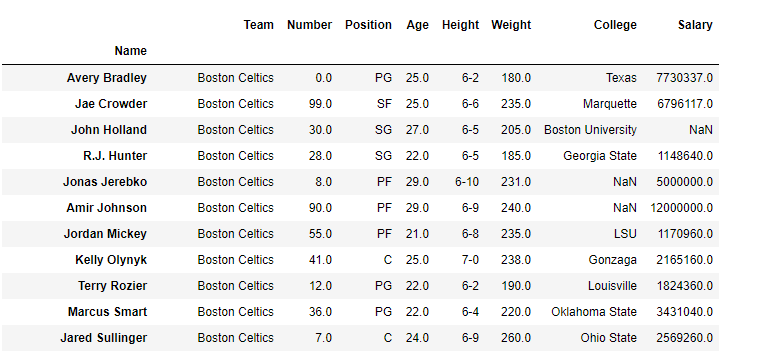
让我们以包含一些虚假数据的DataFrame为例,现在我们对该DataFrame执行索引。在此,我们从DataFrame中选择一些行和一些列。具有数据集的DataFrame:

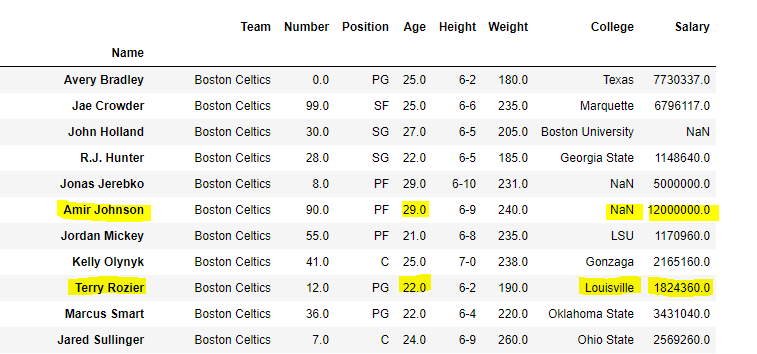
假设我们要选择列Age,College和Salary,同时满足行的值为Amir Johnson和Terry Rozier

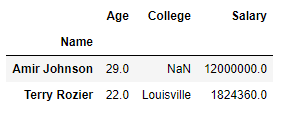
我们最后的数据帧应该是这样的:

选择一些行和所有列
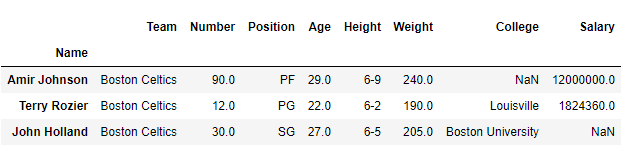
假设我们要选择行 Amir Jhonson,Terry Rozier并选择数据框中的John Holland所有列。
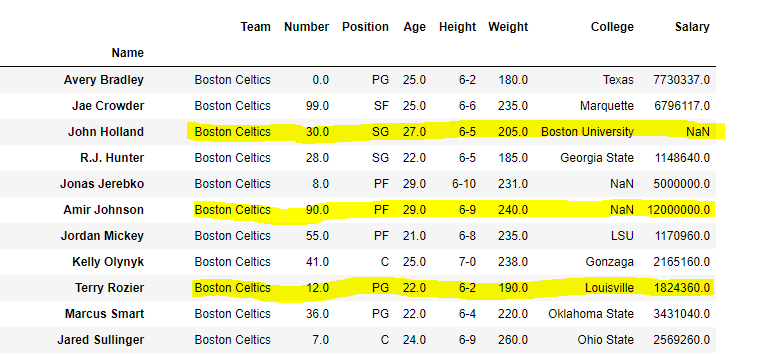

我们最终的DataFrame如下所示:

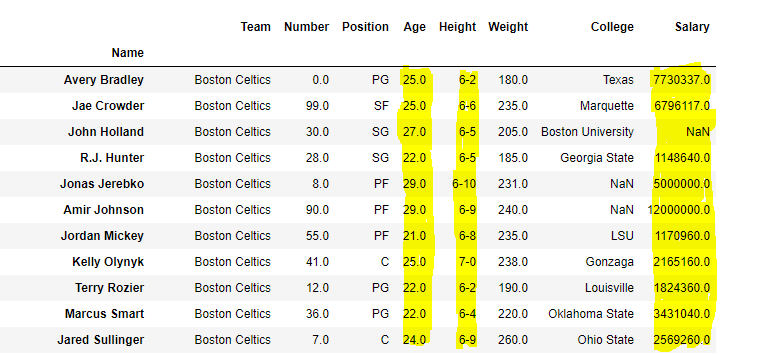
选择一些列和所有行
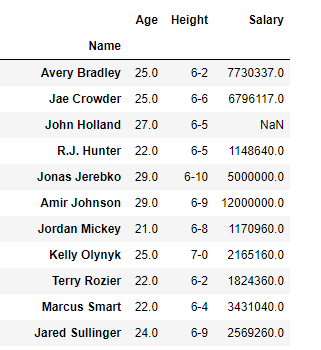
假设我们要选择“Age”,“Height”和“Salary”列以及数据框中的所有行。

我们最终的DataFrame如下所示:

pandas采用索引[ ],,, .loc[].iloc[ ].ix[ ]
有很多方法可以从DataFrame中提取元素,行和列。Pandas中有一些索引方法,可帮助从DataFrame中获取元素。这些索引方法看起来非常相似,但是行为却截然不同。Pandas支持四种类型的多轴索引:
- Dataframe.[ ],此函数也称为索引运算符
- Dataframe.loc []:此函数用于标签。
- Dataframe.iloc []:此函数用于基于位置或整数的
- Dataframe.ix []:此函数用于基于标签和整数的
它们统称为索引器。到目前为止,这些是索引数据的最常用方法。这四个功能有助于从DataFrame中获取元素,行和列。
使用索引运算[]
符为数据框建立索引:索引运算符用于引用对象后面的方括号。该.loc和.iloc索引也使用索引操作符来进行选择。在此索引运算符中引用df []。
选择单列
为了选择单个列,我们只需将列的名称放在方括号之间
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name")
# retrieving columns by indexing operator
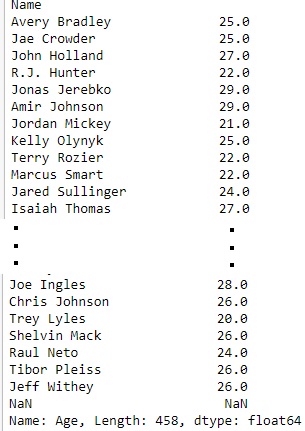
first = data["Age"]
print(first)输出:

为了选择多个列,我们必须在索引运算符中传递一个列列表。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name")
# retrieving multiple columns by indexing operator
first = data[["Age", "College", "Salary"]]
first输出:
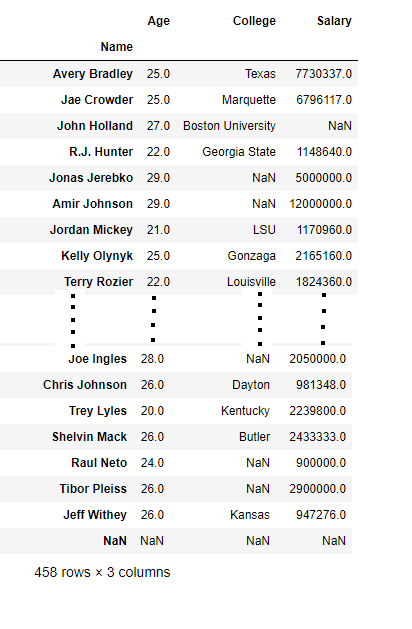

使用.loc[ ]:为DataFrame编制索引。
此函数通过行和列的标签选择数据。该df.loc索引中选择不仅仅是索引操作方式不同的数据。它可以选择行或列的子集。它还可以同时选择行和列的子集。
选择单行
为了使用来选择单行.loc[],我们在.loc函数中放置了单行标签。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name")
# retrieving row by loc method
first = data.loc["Avery Bradley"]
second = data.loc["R.J. Hunter"]
print(first, "\n\n\n", second)输出:
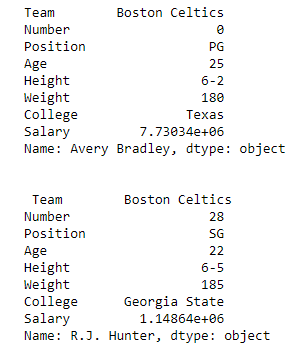
如输出图像所示,由于两次都只有一个参数,因此返回了两个系列。

选择多行
为了选择多行,我们将所有行标签放在列表中,并将其传递给.loc函数。
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name")
# retrieving multiple rows by loc method
first = data.loc[["Avery Bradley", "R.J. Hunter"]]
print(first)输出:

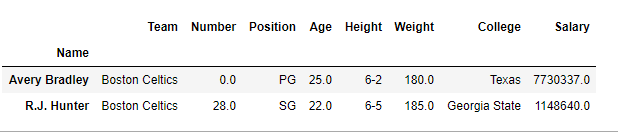
为了选择两行三列,我们选择要选择的两行和三列,然后将其放在单独的列表中,如下所示:
Dataframe.loc [[“" row1“," row2“],[" column1“," column2“," column3“]]import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name")
# retrieving two rows and three columns by loc method
first = data.loc[["Avery Bradley", "R.J. Hunter"],
["Team", "Number", "Position"]]
print(first)输出:
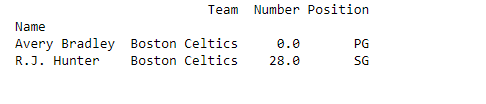

为了选择所有行和某些列,我们使用单冒号[:]选择所有行和要选择的某些列的列表,如下所示:
Dataframe.loc [[:, [“ column1",“ column2",“ column3"]]import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name")
# retrieving all rows and some columns by loc method
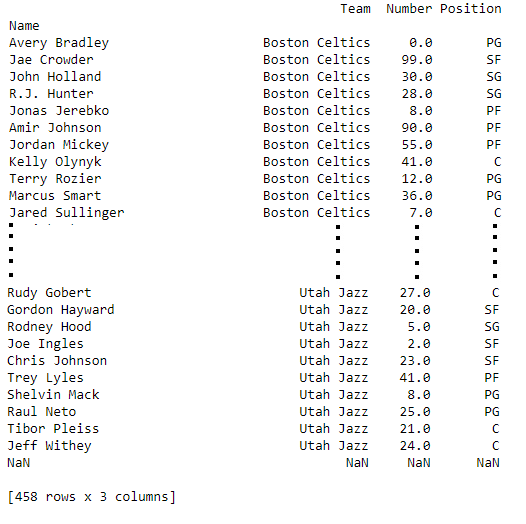
first = data.loc[:, ["Team", "Number", "Position"]]
print(first)输出:

使用.iloc[ ]以下方法为DataFrame编制索引:
此函数使我们可以按位置检索行和列。为此,我们需要指定所需行的位置以及所需列的位置。该df.iloc 索引是非常相似的df.loc ,但只使用整数位置做出选择。
选择单行
为了使用来选择单行.iloc[],我们可以将一个整数传递给.iloc[]函数。
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name")
# retrieving rows by iloc method
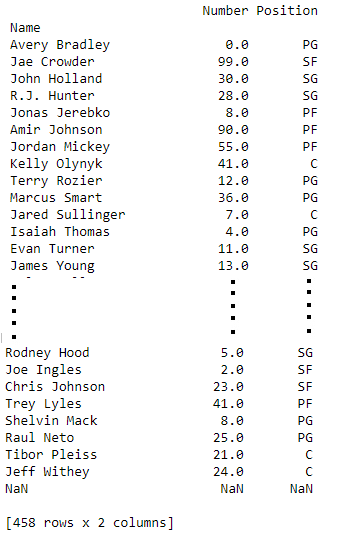
row2 = data.iloc[3]
print(row2)输出:


为了选择多行,我们可以传递一个整数列表来.iloc[]起作用。
输出:

为了选择两行两列,我们为行创建一个2整数的列表,为列创建2整数的列表,然后传递给一个.iloc[]函数。
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name")
# retrieving two rows and two columns by iloc method
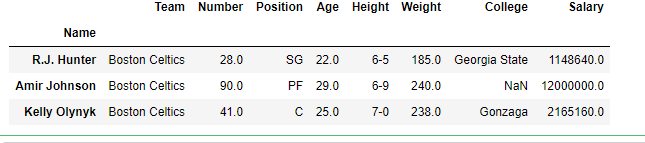
row2 = data.iloc [[3, 4], [1, 2]]
print(row2)输出:


为了选择所有行和某些列,我们使用单冒号[:]选择所有行,对于列,我们创建一个整数列表,然后传递给.iloc[]函数。
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name")
# retrieving all rows and some columns by iloc method
row2 = data.iloc [:, [1, 2]]
print(row2)输出:

使用Dataframe.ix []为 编制索引:
在开发大pandas的早期,存在另一个索引器ix。该索引器能够通过标签和整数位置进行选择。尽管它用途广泛,但由于不明确,引起了很多混乱。有时,整数也可以作为行或列的标签。因此,在某些情况下它是模棱两可的。通常,ix它基于标签,并且充当.loc索引器。但是,.ix还支持整数类型选择(如.iloc中一样),该选择中传递了整数。其中,数据帧的指数是不是整数基于这只能.ix将接受任何的输入.loc和.iloc。
注:该.IX 最近版本的Pandas不推荐使用indexer。
为了选择单行,我们在.ix函数中放置了单行标签。如果我们将行标签作为函数的参数传递,则此函数的作用类似于.loc []。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name")
# retrieving row by ix method
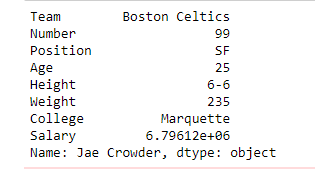
first = data.ix["Avery Bradley"]
print(first)输出:


为了选择单行,我们可以传递一个整数给.ix[]函数。如果我们在.ix[]函数中传递整数,则该函数类似于iloc [] 函数。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name")
# retrieving row by ix method
first = data.ix[1]
print(first)输出:

在DataFrame中建立索引的方法
| 函数 | 描述 |
|---|---|
| Dataframe.head() | 返回 n数据框的顶部行。 |
| Dataframe.tail() | 返回n数据框的底部行。 |
| Dataframe.at [] | 访问行/列标签对的单个值。 |
| Dataframe.iat [] | 通过整数位置访问行/列对的单个值。 |
| Dataframe.tail() | 基于位置的纯基于整数位置的索引。 |
| DataFrame.lookup() | DataFrame的基于标签的“花式索引”功能。 |
| DataFrame.pop() | 返回项目并从框架中放下。 |
| DataFrame.xs() | 从DataFrame返回横截面(行或列)。 |
| DataFrame.get() | 从对象获取给定键(DataFrame列,Panel slice等)的项目。 |
| DataFrame.isin() | 返回布尔值DataFrame,显示值中是否包含DataFrame中的每个元素。 |
| DataFrame.where() | 返回与self形状相同的对象,并且其对应的条目来自cond为True的self,否则来自其他对象。 |
| DataFrame.mask() | 返回与self形状相同的对象,其对应的条目来自cond为False的self,否则来自其他对象。 |
| DataFrame.query() | 使用布尔表达式查询框架的列。 |
| DataFrame.insert() | 将列插入到DataFrame中的指定位置。 |