- 在Pandas DataFrame中处理行和列(1)
- 遍历 Pandas DataFrame 中的行和列
- 遍历Pandas DataFrame中的行和列(1)
- 遍历 Pandas DataFrame 中的行和列(1)
- 遍历Pandas DataFrame中的行和列
- Pandas DataFrame 的处理时间
- Pandas DataFrame 的处理时间(1)
- 如何在 Pandas 中创建一个空的 DataFrame 并将行和列附加到它?(1)
- 如何在 Pandas 中创建一个空的 DataFrame 并将行和列附加到它?
- 交换行和列 pandas - Python (1)
- 交换行和列 pandas - Python 代码示例
- 对 pandas 中的行和列进行排序 - Python (1)
- Python Pandas DataFrame(1)
- Python Pandas DataFrame
- 对 pandas 中的行和列进行排序 - Python 代码示例
- 从R中的DataFrame中选择奇数和偶数行和列(1)
- 从R中的DataFrame中选择奇数和偶数行和列
- Python中的 pandas.DataFrame.T()函数(1)
- Python中的 pandas.DataFrame.T()函数
- 计算 Pandas Dataframe 中的值(1)
- 计算 Pandas Dataframe 中的值
- python中的最大行和列(1)
- Flutter 行和列(1)
- Flutter 行和列
- 用 Pandas 中另一个 DataFrame 的值替换 DataFrame 的值
- 使用 [ ]、loc 和 iloc 在 Pandas DataFrame 中按名称或索引选择行和列
- 使用 [ ]、loc 和 iloc 在 Pandas DataFrame 中按名称或索引选择行和列(1)
- 如何从 Pandas DataFrame 创建饼图?
- 如何从 Pandas DataFrame 创建饼图?(1)
📅 最后修改于: 2020-04-19 14:57:55 🧑 作者: Mango
数据框DataFrame是二维数据结构,即,数据以表格形式在行和列中对齐。我们可以对行/列执行基本操作,例如选择,删除,添加和重命名。在本文中,我们正在使用nba.csv文件。

处理列
为了处理列,我们对列执行基本操作,例如选择,删除,添加和重命名。

列选择:
为了在Pandas DataFrame中选择列,我们可以通过按列名称调用它们来访问列。
# 导入pandas
import pandas as pd
# 定义包含员工数据的字典
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Age':[27, 24, 22, 32],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
# 将字典转换为DataFrame
df = pd.DataFrame(data)
# 选择两列
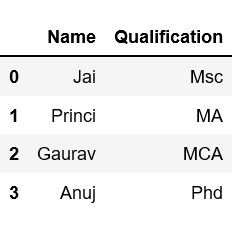
print(df[['Name', 'Qualification']])输出:

Column Addition/添加列:
为了在Pandas DataFrame中添加列,我们可以将新列表声明为一列并添加到现有Dataframe中。
# 导入pandas
import pandas as pd
# 定义包含学生数据的字典
data = {'Name': ['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Height': [5.1, 6.2, 5.1, 5.2],
'Qualification': ['Msc', 'MA', 'Msc', 'Msc']}
# 将字典转换为DataFrame
df = pd.DataFrame(data)
# 声明要转换为列的列表
address = ['Delhi', 'Bangalore', 'Chennai', 'Patna']
# 使用“Address"作为列名#并将其等同于列表
df['Address'] = address
# 观察结果
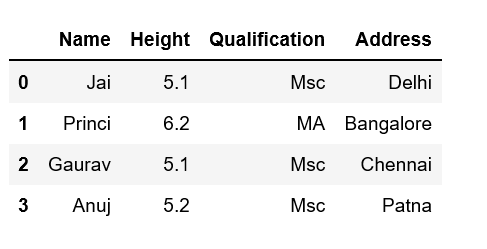
print(df)输出:

列删除现有DataFrame的列:
为了删除Pandas DataFrame中的列,我们可以使用该drop()方法。通过删除带有列名的列来删除列。
# 导入pandas
import pandas as pd
# 从csv文件制作数据帧
data = pd.read_csv("nba.csv", index_col ="Name" )
# 删除传递的列
data.drop(["Team", "Weight"], axis = 1, inplace = True)
# 打印
print(data)输出:
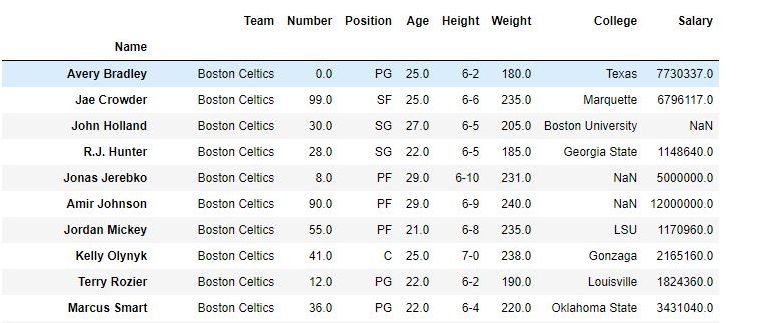
如输出图像所示,新的输出没有传递的列。由于将axis设置为1,所以这些值将被删除,并且由于inplace为True,因此在原始数据帧中进行了更改。
删除列之前的数据框:
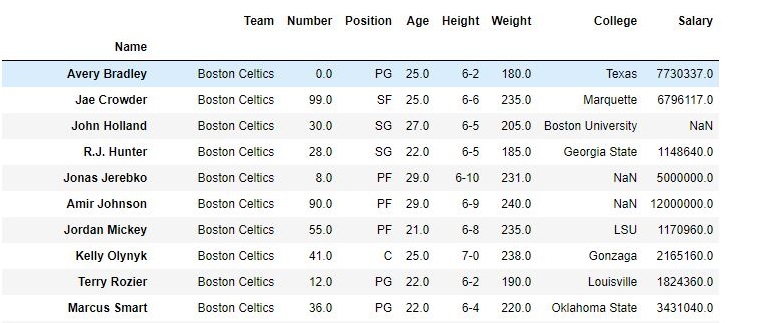


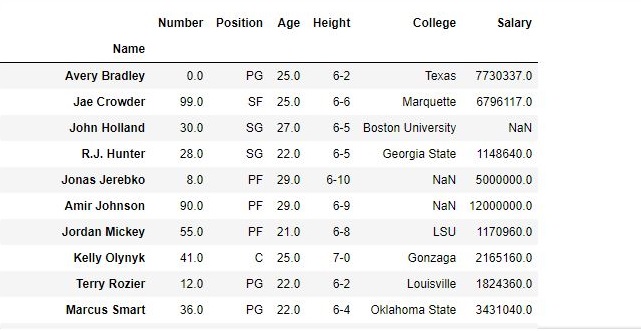
删除列之后的数据框:
处理行:
为了处理行,我们可以对行执行基本操作,例如选择,删除,添加和重新映射。
行选择:
pandas提供了一种从数据框中检索行的独特方法。DataFrame.loc[]方法用于从Pandas DataFrame检索行。也可以通过将整数位置传递给 iloc []函数来选择行。
# 导入pandas
import pandas as pd
# 从csv文件制作数据帧
data = pd.read_csv("nba.csv", index_col ="Name")
# 通过loc方法检索行
first = data.loc["Avery Bradley"]
second = data.loc["R.J. Hunter"]
print(first, "\n\n\n", second)输出:

如输出图像所示,由于两次都只有一个参数,因此返回了两个系列。

行相加:
为了增加在pandas数据帧一个新的行,我们可以Concat旧的数据帧和新的数据帧。
# 导入pandas
import pandas as pd
# 制作数据框
df = pd.read_csv("nba.csv", index_col ="Name")
df.head(10)
new_row = pd.DataFrame({'Name':'Geeks', 'Team':'Boston', 'Number':3,
'Position':'PG', 'Age':33, 'Height':'6-2',
'Weight':189, 'College':'MIT', 'Salary':99999},
index =[0])
# simply concatenate both dataframes
df = pd.concat([new_row, df]).reset_index(drop = True)
df.head(5)输出:
添加行之前的数据帧:
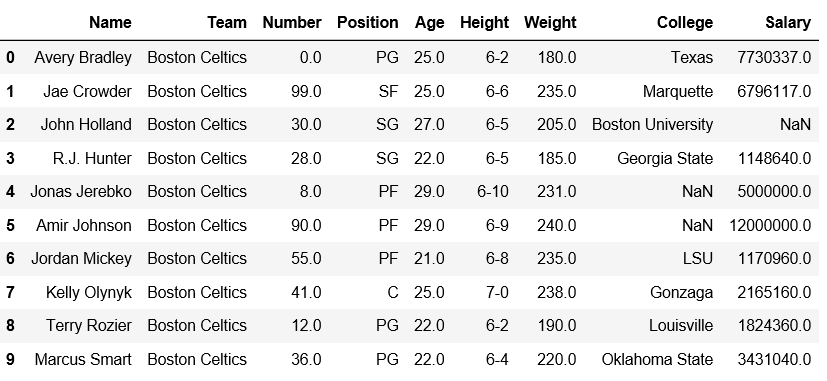
添加行之后的数据帧:


行删除
为了删除Pandas DataFrame中的行,我们可以使用drop()方法。通过删除按索引的行标签来删除行。
# 导入pandas
import pandas as pd
# 从csv文件制作数据帧
data = pd.read_csv("nba.csv", index_col ="Name" )
# 删除传递的值
data.drop(["Avery Bradley", "John Holland", "R.J. Hunter",
"R.J. Hunter"], inplace = True)
# 打印
data输出:
如输出图像所示,新输出没有传递的值。由于inplace为True,因此删除了这些值,并在原始数据框中进行了更改。
删除值之前的数据帧:
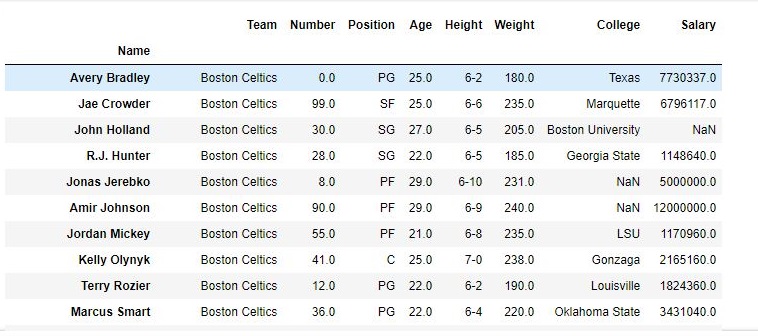
删除值之后的数据帧: