📌 相关文章
- 广度优先遍历的应用(1)
- 广度优先遍历的应用
- 数据结构-图的广度优先搜索算法(1)
- 数据结构-图的广度优先搜索算法
- 广度优先搜索
- 二维数组上的广度优先遍历 (BFS)
- 二维数组上的广度优先遍历 (BFS)
- python广度优先搜索——Python(1)
- 数据结构-深度优先遍历
- python广度优先搜索——Python代码示例
- 2D阵列上的广度优先遍历(BFS)(1)
- 2D阵列上的广度优先遍历(BFS)
- 不使用队列的广度优先搜索(1)
- 不使用队列的广度优先搜索(1)
- 不使用队列的广度优先搜索
- 不使用队列的广度优先搜索
- 不使用队列的广度优先搜索
- 不使用队列的广度优先搜索
- 图的广度优先搜索或 BFS(1)
- 图的广度优先搜索或 BFS
- 广度优先搜索BST java代码示例
- 用于图的广度优先搜索或 BFS 的 C 程序
- 用于图的广度优先搜索或 BFS 的 C 程序(1)
- 用于图的广度优先搜索或 BFS 的Python程序
- 用于图的广度优先搜索或 BFS 的Python程序(1)
- 用于图的广度优先搜索或 BFS 的Java程序(1)
- 用于图的广度优先搜索或 BFS 的Java程序
- 广度测试
- 广度测试(1)
📜 数据结构-广度优先遍历
📅 最后修改于: 2021-01-11 10:25:26 🧑 作者: Mango
广度优先搜索(BFS)算法以广度运动遍历图形,并在任何迭代出现死角时使用队列记住要获取的下一个顶点来开始搜索。
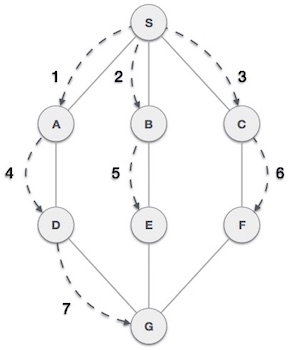
如以上示例所示,BFS算法首先从A到B遍历到E到F,然后遍历C和G,最后遍历到D。它采用以下规则。
-
规则1-访问相邻的未访问顶点。将其标记为已访问。显示它。将其插入队列。
-
规则2-如果未找到相邻的顶点,请从队列中删除第一个顶点。
-
规则3-重复规则1和规则2,直到队列为空。
| Step | Traversal | Description |
|---|---|---|
| 1 |  |
Initialize the queue. |
| 2 |  |
We start from visiting S (starting node), and mark it as visited. |
| 3 |  |
We then see an unvisited adjacent node from S. In this example, we have three nodes but alphabetically we choose A, mark it as visited and enqueue it. |
| 4 |  |
Next, the unvisited adjacent node from S is B. We mark it as visited and enqueue it. |
| 5 |  |
Next, the unvisited adjacent node from S is C. We mark it as visited and enqueue it. |
| 6 |  |
Now, S is left with no unvisited adjacent nodes. So, we dequeue and find A. |
| 7 |  |
From A we have D as unvisited adjacent node. We mark it as visited and enqueue it. |
在这一阶段,我们没有未标记(未访问)的节点。但是根据算法,我们继续进行出队以获取所有未访问的节点。清空队列后,程序结束。
在C语言中可以看到该算法的实现。