- R调试(1)
- c++反调试——C++(1)
- 调试
- 调试 (1)
- 调试
- R调试
- TensorFlow调试中的修复问题
- 调试python(1)
- 在 python 中调试(1)
- c++反调试——C++代码示例
- JavaScript-调试
- 在 JavaScript 中调试
- JavaScript-调试(1)
- 酶调试 - Javascript (1)
- 在 javascript 中调试(1)
- JavaScript调试(1)
- JavaScript调试
- 在 JavaScript 中调试(1)
- 调试python代码示例
- 在 python 代码示例中调试
- 在 javascript 代码示例中调试
- 酶调试 - Javascript 代码示例
- 如何调试JavaScript
- 如何调试JavaScript(1)
- 调试 - 任何代码示例
- TensorFlow 2.0
- TensorFlow 2.0(1)
- TensorFlow 2.0
- TensorFlow 2.0(1)
📅 最后修改于: 2021-01-11 11:03:02 🧑 作者: Mango
TensorFlow调试
调试是一项繁琐而艰巨的任务。我们必须编写代码并通过张量流调试来识别问题。通常,有很多指南,并且调试过程对于许多语言和框架都有很好的文档说明。
TensorFlow有一个名为tfdbg TensorFlow Debugging的调试器,它使我们能够观察基本的工作和运行图的状态。使用Python的pdb之类的调试器很难调试这些。
本教程将教我们如何使用tfdbg CLI调试nan和图标的外观,它们是在张量流中发现的最常见的错误类型。下面给出了一个低级API示例。
Python-m张量流Python.debug.examples.debug_mnist
上面给出的代码是用于MNIST数字图像识别的神经网络,在经过几步饱和之后,精度会提高。
这个错误可能是infs和nans,它们具有最常见的错误。现在,使用tfdbg调试问题并知道问题从何开始。
用tfdbg包装TensorFlow会话
添加以下代码行以使用tfdbg,并使用调试器包装器包含会话对象。
From tensorflow.python import debug as tf_debug
sess= tf_debug.LocalCLIDebugWrapperSession (sess)
包装类提供了一些附加功能,其中包括:可以在Session之前和之后调用CLI。如果我们希望控制执行并知道图的内部状态,请运行()。
可以添加过滤器以帮助诊断。在提供的示例中,有一个名为tfdbg.has_inf_or_nan的过滤器,该过滤器确定在任意张量之间的Nan或inf的存在,这些张量既不是输入也不是输出。
我们始终可以为适合我们需求的自定义过滤器编写代码,我们可以查看API文档以获取有关其的更多信息。
使用tfdbg调试TensorFlow模型培训
现在该训练包含-debug标志的模型了:
python-m
tensorflow.python.debug.examples.debug_mnist-debug
提取的数据可以显示在屏幕上,如下图所示:
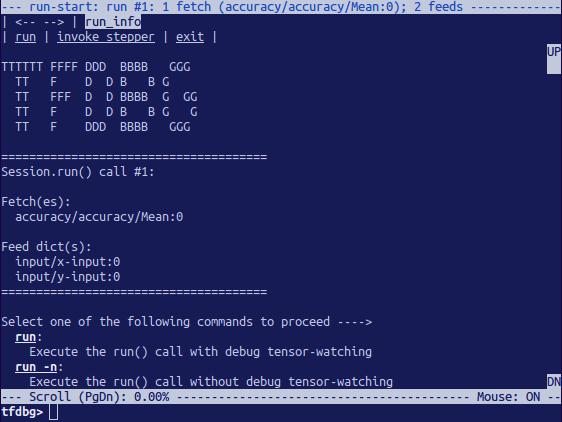
上图是运行启动界面。之后,在提示符下输入r:
tfdbg>运行
如果下一个会话调用,将使TensorFlow调试器运行,计算测试数据集的准确性。
例如:
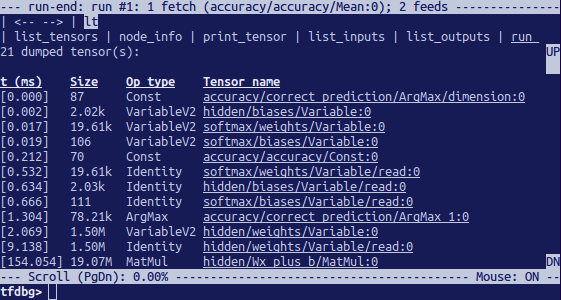
执行run之后,可以使用命令列出张量。
常用的TensorFlow调试命令
请在tfdbg>提示符下查看以下命令:请注意,每当我们输入命令时,都会看到全新的显示输出。这类似于浏览器中的互联网页面。我们可以通过单击CLI左上角附近的<-和->文本箭头在这些屏幕之间导航。
tfdbg CLI的功能
类似地,就像上面索引的TensorFlow调试命令一样,tfdbg CLI提供了以下附加功能:
浏览以字符开头的tfdbg指令。
要浏览前面的tfdbg指令,请键入一些字符,并附带向上或向下箭头键。 Tfdbg将向我们展示从一个人的态度开始的指导历史。
要浏览屏幕输出的记录,请执行以下两项操作:
单击紧贴顶峰的带下划线的<-and->超链接,该超链接位于显示屏的左上角。要将显示屏幕的输出重定向到优先于屏幕的记录,请退出命令将pt命令的输出重定向到
/tmp/xent_value_slices.txtfile:
tfdbg> pt crosses_entropy/Log:0[:, 0:10] > /tmp/xnt_value_slices.txt
查找nan和infs
在第一次咨询Run()调用中,它不会出现任何复杂的数值。我们可以通过使用命令run或它的简写r来跟随run。
我们还可以使用-t标志来传输Session之前和部分会话。一次运行()个调用,
在不停止运行启动或运行停止激活的情况下运行Run(),直到图形中的主要Nan或inf值为止。这类似于tensorflow中过程语言调试器中的条件断点:
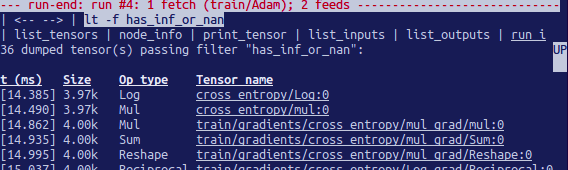
tfdbg> run -f has_inf_or_nan
前面的命令之所以有效,是因为在创建包装的咨询时会清除一个张量,称为has_inf_or_nan,已注册使用。
def my_filter_callable (datum, tensor):
return len(tensor. Shape) == 0 and tensor == 0
sess.add_tensor_filter('my_filter', my_filters_callable)
The tfdbg run-start prompt Run until our filter is precipitated:
tfdbg> run -f my_filter
请参阅API文档以获取有关预期签名的更多统计信息,并返回与add_tensor_filter()一起使用的谓词可调用的值。
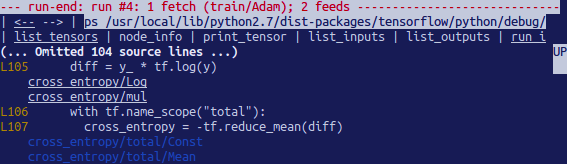
因为显示建议在第一行,所以将has_inf_or_nan过滤掉首先进行第四次咨询。
Run()调用: Adam优化器的前后教育跳过该图。在此运行中,有36个中间张量包含nan或inf值。
tfdbg>pt dross_entropy/Log:0
向下滚动一点,我们将输入一些分散的inf值。如果很难通过视觉识别inf和Nan的实例,我们可以使用以下命令执行正则表达式查找并突出显示输出:
tfdbg>/inf
或者,作为替代:
tfdbg>/(inf|nan)
我们还可以使用-s或-numeric_summary命令来获取张量内各种数值的摘要:
tfdbg>pt -s cross_entropy/Log:0
我们可以看到cross_entropy / Log的数千个元素中的几个:零张量是-infs(负无穷大)。
tfdbg> ni cross_entropy/Log
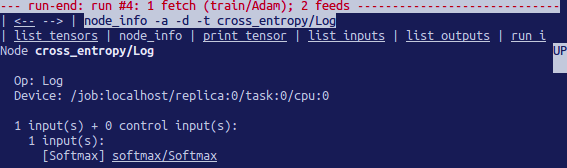
我们看到该节点的操作类型为log,其输入为节点softmax。然后运行以下命令以更深入地观察输入张量:
tfdbg> pt Softmax:0
看一下输入张量中的值,寻找零:
tfdbg>/0\.000
现在很清楚,可怕的数值的基础是零点的节点交叉熵/对数对话记录。
要在Python供应代码中找出错误的行,请使用ni命令的-t标志显示节点生产的追溯:
tfdbg> ni -t cross_entropy / Log
如果我们单击显示顶部的“ node_info”,则tfdbg会机械地建议对节点创建的回溯。
从回溯中,我们看到op是在以下行构建的:debug_minist.Py:
Diff=y_*tf.log(y)
它可以用pops或tensor顶住它们来注释Python记录的行。