- Teradata-主索引
- Teradata主索引(1)
- Teradata连接索引(1)
- Teradata连接索引
- Teradata
- Teradata-宏(1)
- Teradata
- Teradata
- Teradata-宏
- Teradata宏(1)
- Teradata表(1)
- Teradata(1)
- Teradata(1)
- Teradata表
- Teradata-表
- Teradata-表(1)
- Teradata宏
- Teradata-JOIN索引(1)
- Teradata-JOIN索引
- Teradata分区主索引
- Teradata-分区主索引(1)
- Teradata-分区主索引
- Teradata分区主索引(1)
- Teradata子字符串(1)
- Teradata子字符串
- Teradata-安装(1)
- Teradata-安装
- Teradata安装
- Teradata安装(1)
📅 最后修改于: 2021-01-11 11:25:38 🧑 作者: Mango
Teradata主索引
主索引用于指定数据在Teradata中的位置。它用于确定哪个AMP获取数据行。
在Teradata中,每个表都必须定义一个主索引。如果未定义主索引,则Teradata会自动分配主索引。
主索引提供了访问数据的最快方法。一个主数据库最多可以有64列。主索引是在创建表时定义的,不能更改或修改。
主索引是以下方面的最优选和必要的索引:
- 资料分配
- 已知访问路径
- 提高连接性能
主索引规则
以下是主索引的一些特定规则,例如:
规则1:每个表一个主索引。
规则2:主索引值可以是唯一或不唯一的。
规则3:主索引值可以为NULL。
规则4:不能修改已填充表的主索引。
规则5:主索引值可以修改。
规则6:主索引限制为64列。
主要指标类型
主索引有两种类型。
- 唯一主索引(UPI)
- 非唯一主要指数(NUPI)
1.唯一主索引(UPI)
在“唯一主索引”表中,该列不应有任何重复的值。如果插入任何重复的值,它们将被拒绝。 Unique Primary索引强制列的唯一性。
唯一主索引(UPI)始终会在AMP之间平均分配表的行。 UPI访问始终是单安培操作。
如何创建唯一主索引?
在下面的示例中,我们使用Roll_no,First_name和Last_name列创建Student表。
| Roll_no | First_name | Last_name |
|---|---|---|
| 1001 | Mike | Richard |
| 1002 | Robert | Williams |
| 1003 | Peter | Collin |
| 1004 | Alexa | Stuart |
| 1005 | Robert | Peterson |
我们选择了Roll_no作为我们的主要索引。由于我们已将Roll_no指定为唯一的主要索引,因此表中不会有重复的学生编号。
CREATE SET TABLE Student
(
Roll_no int,
First_name varchar2(10),
Last_name varchar2(10),
)
UNIQUE PRIMARY INDEX(Roll_no);
2.非唯一主索引(NUPI)
非唯一主索引(NUPI)表示所选列的值可以是非唯一的。
非唯一主索引永远不会均匀分布表行。如果数据分布不均,则All-AMP操作将花费更长的时间。
我们可能会选择UPI而不是UPI,因为NUPI列对于查询访问和联接可能更有用。
如何创建非唯一主索引?
在下面的示例中,我们创建带有雇员名,名称,部门和城市列的雇员表。
| Employee_Id | Name | Department | City |
|---|---|---|---|
| 202001 | Max | Sales | London |
| 202002 | Erika | Finance | Washington |
| 202003 | Nancy | Management | Paris |
| 202004 | Bella | Human Recourse | London |
| 202005 | Sam | Marketing | London |
每个员工都有不同的员工ID,姓名和部门,但是此表中有许多员工属于同一城市。因此,我们选择了城市作为我们的非唯一主要指数。
CREATE SET TABLE Employee
(
Employee_Id int,
Name varchar2 (10),
Department varchar2 (10),
)
PRIMARY INDEX(City);
多列主索引
Teradata允许将多个列指定为主索引。它仍然只是一个主索引,但仅由多个列的组合组成。
Teradata多列主索引最多允许64个组合列构成一个表所需的一个主索引。
例
在下面的示例中,我们指定了First_Name和Last_Name进行组合以组成主索引。
这是非常有用和有益的,有两个原因:
- 为了更好地在AMP之间分配数据。
- 对于经常使用多个键进行查询的用户。
使用主索引进行数据分发
当用户使用主索引向表提交SQL请求时,该请求将成为单AMP操作,这是系统查找行的最直接,最有效的方法。下面说明该过程。
下图说明了完整的过程:
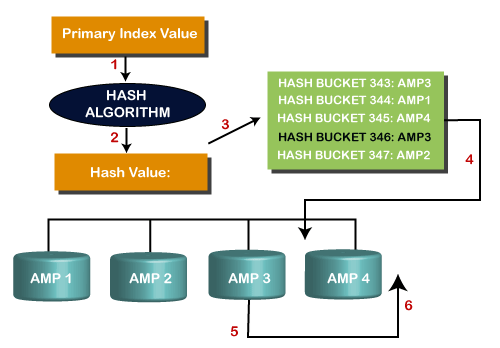
散列过程
哈希的过程在以下步骤中定义,例如:
步骤1:第一步,主要索引值进入哈希算法。
步骤2:哈希算法的输出是行哈希值。
步骤3:哈希映射指向该行所在的特定AMP。
步骤4: PE将请求直接发送到已识别的AMP。
步骤5: AMP在其虚拟磁盘上找到该行。
步骤6:数据通过BYNET发送到PE,PE将答案集发送到客户端应用程序。
行哈希值重复
对于两个不同的行,哈希算法可以以相同的行哈希值结束。
我们可以通过两种方式做到这一点,例如:
- 重复的NUPI值:如果使用非唯一主索引,则重复的NUPI值将产生相同的行哈希值。
- 哈希同义词:也称为哈希冲突。当哈希算法为两个不同的主索引值计算相同的行哈希值时,就会发生这种情况。
为了区分表中的每一行,为每一行分配了唯一的行ID。行ID是行哈希值和唯一值的组合。
唯一性值用于区分主索引值生成相同行哈希值的行。在大多数情况下,仅需要使用行ID的行哈希值部分来定位行。

插入每行时,AMP会添加行ID,并存储为行的前缀。
为插入了特定行哈希值的第一行分配一个唯一值,对于任何插入有相同行哈希值的其他行,该唯一值将增加1。