- 机器学习中的线性回归(1)
- 机器学习中的线性回归
- 使用R的简单线性回归
- 机器学习-多元线性回归
- 机器学习-多元线性回归(1)
- 机器学习中的回归分析(1)
- 机器学习中的回归分析
- R线性回归
- R-线性回归(1)
- 线性回归 (1)
- R线性回归(1)
- R-线性回归
- 机器学习中的逻辑回归
- 机器学习中的逻辑回归(1)
- 机器学习中的回归与分类
- Python线性回归(1)
- python中的线性回归(1)
- Python线性回归
- 机器学习-多项式回归
- 机器学习-多项式回归(1)
- scikit 学习线性回归 - Python (1)
- scikit 学习线性回归 - Python 代码示例
- python代码示例中的线性回归
- 线性回归 - Javascript 代码示例
- C++中的机器学习(1)
- 机器学习 (1)
- 机器学习中的 P 值(1)
- C++中的机器学习
- 机器学习中的 P 值
📅 最后修改于: 2020-09-27 02:02:48 🧑 作者: Mango
机器学习中的简单线性回归
简单线性回归是一种回归算法,可以对因变量和单个自变量之间的关系进行建模。简单线性回归模型显示的关系是线性或倾斜的直线,因此称为简单线性回归。
简单线性回归的关键点在于因变量必须是连续/实数值。但是,可以根据连续值或分类值来测量自变量。
简单线性回归算法主要有两个目标:
- 对两个变量之间的关系进行建模。例如收入与支出,经验和薪水之间的关系等。
- 预测新观察。如根据温度进行天气预报,根据一年中的投资获得公司收入等。
简单线性回归模型:
可以使用以下方程式表示简单线性回归模型:
哪里,
a0 =它是回归线的截距(可以通过放x = 0来获得)a1 =它是回归线的斜率,它表明该线是增加还是减少。 ε=误差项。 (对于一个好的模型,可以忽略不计)
简单线性回归算法的Python
简单线性回归的问题陈述示例:
在这里,我们获取一个具有两个变量的数据集:薪水(因变量)和经验(因变量)。此问题的目标是:
- 我们想找出这两个变量之间是否有任何相关性
- 我们将为数据集找到最佳拟合线。
- 通过更改因变量来更改因变量的方式。
在本节中,我们将创建一个简单线性回归模型,以找出最佳的拟合线来表示这两个变量之间的关系。
要使用Python在机器学习中实现简单线性回归模型,我们需要执行以下步骤:
步骤1:数据预处理
创建简单线性回归模型的第一步是数据预处理。在本教程的前面,我们已经做到了。但是会有一些更改,这些更改在以下步骤中进行:
- 首先,我们将导入三个重要的库,这将有助于我们加载数据集,绘制图形并创建简单线性回归模型。
import numpy as nm
import matplotlib.pyplot as mtp
import pandas as pd
- 接下来,我们将数据集加载到我们的代码中:
data_set= pd.read_csv('Salary_Data.csv')
通过执行上面的代码行(ctrl + ENTER),我们可以通过单击变量资源管理器选项在Spyder IDE屏幕上读取数据集。

上面的输出显示了数据集,该数据集具有两个变量:薪金和经验。
注意:在Spyder IDE中,包含代码文件的文件夹必须保存为工作目录,并且数据集或csv文件应位于同一文件夹中。
- 之后,我们需要从给定的数据集中提取因变量和自变量。自变量是经验的年限,因变量是薪水。下面是它的代码:
x= data_set.iloc[:, :-1].values
y= data_set.iloc[:, 1].values
在上面的代码行中,对于x变量,由于我们要从数据集中删除最后一列,因此我们采用-1值。对于y变量,我们将1值作为参数,因为我们要提取第二列并且索引从零开始。
通过执行上面的代码行,我们将获得X和Y变量的输出,如下所示:
在上面的输出图像中,我们可以看到X(独立)变量和Y(独立)变量已从给定的数据集中提取。
- 接下来,我们将两个变量均分为测试集和训练集。我们有30个观测值,因此对于训练集,我们将采取20个观测值,对于测试集,我们将采取10个观测值。我们正在拆分数据集,以便我们可以使用训练数据集训练模型,然后使用测试数据集测试模型。下面给出了此代码:
# Splitting the dataset into training and test set.
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 1/3, random_state=0)
通过执行以上代码,我们将获得x检验,x训练和y检验,y训练数据集。考虑以下图像:
测试数据集:
训练数据集:
- 对于简单的线性回归,我们将不使用特征缩放。因为Python库在某些情况下会处理它,所以我们不需要在这里执行它。现在,我们的数据集已经为处理它做好了充分的准备,并且我们将开始为给定问题构建简单的线性回归模型。
步骤2:将简单线性回归拟合到训练集:
现在第二步是将我们的模型拟合到训练数据集。为此,我们将从scikit Learn导入linear_model库的LinearRegression类。导入该类后,我们将创建该类的一个对象,称为回归器。下面给出了此代码:
#Fitting the Simple Linear Regression model to the training dataset
from sklearn.linear_model import LinearRegression
regressor= LinearRegression()
regressor.fit(x_train, y_train)
在上面的代码中,我们使用fit()方法将简单线性回归对象拟合到训练集。在fit() 函数,我们传递了x_train和y_train,这是我们的因变量和自变量的训练数据集。我们已经将回归对象拟合到训练集,以便模型可以轻松地学习预测变量和目标变量之间的相关性。执行以上代码行后,我们将获得以下输出。
输出:
Out[7]: LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
步骤:3.测试集结果的预测:
因变量(薪水)和自变量(经验)。因此,现在,我们的模型已准备好预测新观测值的输出。在这一步中,我们将向模型提供测试数据集(新观察值),以检查其是否可以预测正确的输出。
我们将创建一个预测向量y_pred和x_pred,分别包含测试数据集的预测和训练集的预测。
#Prediction of Test and Training set result
y_pred= regressor.predict(x_test)
x_pred= regressor.predict(x_train)
执行上述代码行后,将在变量资源管理器中生成两个名为y_pred和x_pred的变量,这些选项包含针对训练集和测试集的薪水预测。
输出:
您可以通过在IDE中单击变量资源管理器选项来检查变量,也可以通过比较y_pred和y_test中的值来比较结果。通过比较这些值,我们可以检查模型的性能如何。
步骤:4.可视化训练集结果:
现在,在此步骤中,我们将可视化训练集结果。为此,我们将使用pyplot库的scatter() 函数 ,该函数已在预处理步骤中导入。 scatter() 函数将创建观测值的散点图。
在x轴上,我们将绘制员工的工作年限,在y轴上,我们将绘制员工的薪水。在函数,我们将传递训练集的实际值,这表示经验x_train的一年,薪水y_train的训练集和观察值的颜色。在这里,我们采用绿色进行观察,但是根据选择,它可以是任何颜色。
现在,我们需要绘制回归线,为此,我们将使用pyplot库的plot() 函数 。在此函数,我们将传递训练集的年限,训练集x_pred的预计薪水以及线条的颜色。
接下来,我们将给出该图的标题。因此,在这里,我们将使用pyplot库的title() 函数并传递名称(“薪金与经验(培训数据集)”)。
之后,我们将使用xlabel()和ylabel() 函数为x轴和y轴分配标签。
最后,我们将使用show()在图中表示以上所有内容。代码如下:
mtp.scatter(x_train, y_train, color="green")
mtp.plot(x_train, x_pred, color="red")
mtp.title("Salary vs Experience (Training Dataset)")
mtp.xlabel("Years of Experience")
mtp.ylabel("Salary(In Rupees)")
mtp.show()
输出:
通过执行以上代码行,我们将获得以下图形图作为输出。
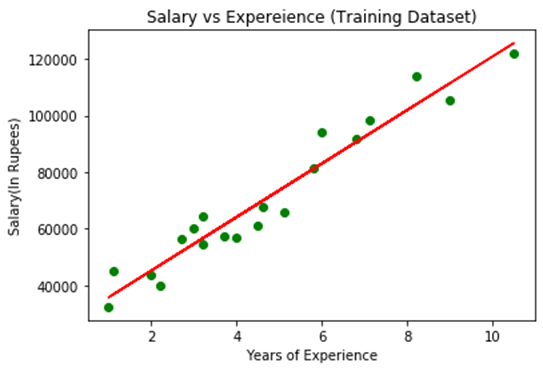
在上面的图中,我们可以看到绿色点的实际值观察结果,而预测值被红色回归线覆盖。回归线显示因变量和自变量之间的相关性。
通过计算实际值和预测值之间的差异,可以观察到直线的良好拟合。但是,正如我们在上图中所看到的那样,大多数观察值都接近回归线,因此我们的模型对于训练集非常有用。
步骤:5.可视化测试集结果:
在上一步中,我们已经可视化了模型在训练集上的表现。现在,我们将对测试集执行相同的操作。完整的代码将与上面的代码相同,不同的是,我们将使用x_test和y_test代替x_train和y_train。
在这里,我们还更改了观察值和回归线的颜色以区分两个图,但这是可选的。
#visualizing the Test set results
mtp.scatter(x_test, y_test, color="blue")
mtp.plot(x_train, x_pred, color="red")
mtp.title("Salary vs Experience (Test Dataset)")
mtp.xlabel("Years of Experience")
mtp.ylabel("Salary(In Rupees)")
mtp.show()
输出:
通过执行上面的代码行,我们将获得如下输出:

在上面的图中,蓝色给出了观察结果,红色回归线给出了预测结果。如我们所见,大多数观察值都接近回归线,因此我们可以说我们的简单线性回归是一个很好的模型,能够做出很好的预测。