了解任何机器学习算法中的准确性时,重要的是要了解预测误差(偏差和方差)。在模型最小化偏差和方差的能力之间需要权衡,这被称为选择正则化常数值的最佳解决方案。正确理解这些错误将有助于避免训练算法时数据集的过拟合和欠拟合。
偏见
偏差称为ML模型预测值与正确值之间的差。偏见程度高会给训练和测试数据带来很大的误差。它建议算法应始终保持低偏差,以避免拟合不足的问题。
由于高偏差,预测的数据为直线格式,因此无法准确地拟合到数据集中的数据中。这种拟合称为“数据不足拟合”。当假设本质上过于简单或线性时,就会发生这种情况。有关这种情况的示例,请参见下面的图形。
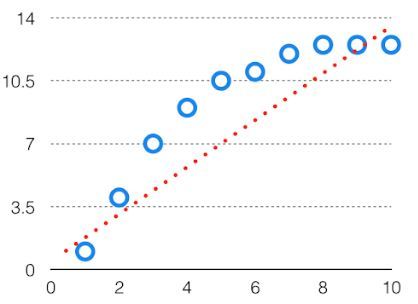
高偏见
在这样的问题中,假设如下。 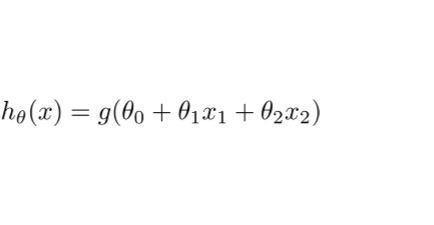
方差
给定数据点的模型预测变量会告诉我们数据的扩散,称为模型方差。具有高方差的模型对训练数据的拟合非常复杂,因此无法准确地拟合之前从未见过的数据。结果,这样的模型在训练数据上表现很好,但是在测试数据上有很高的错误率。
当模型的方差很高时,则称其为“数据过度拟合” 。过度拟合是通过复杂曲线和高阶假设准确地拟合训练集,但不是解决方案,因为带有看不见数据的误差很大。
在训练数据模型时,应保持较低的方差。
高方差数据如下所示。
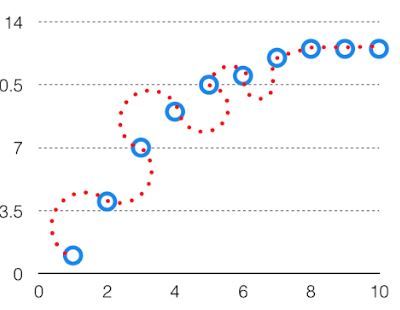
高差异
在这样的问题中,假设如下。 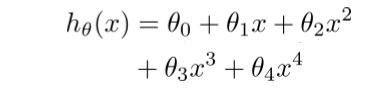
偏差方差折衷
如果该算法过于简单(关于线性方程的假设),那么它可能处于高偏差和低方差条件下,因此容易出错。如果算法拟合得太复杂(假设具有较高的等价度),那么它可能具有较高的方差和较低的偏倚。在后一种情况下,新条目将无法正常运行。好吧,这两个条件之间存在某种权衡,即“权衡”或“偏差偏差权衡”。
这种复杂性的权衡是为什么在偏差和方差之间要权衡的原因。一个算法不能同时变得更复杂和更简单。对于图形,完美的权衡将是这样。
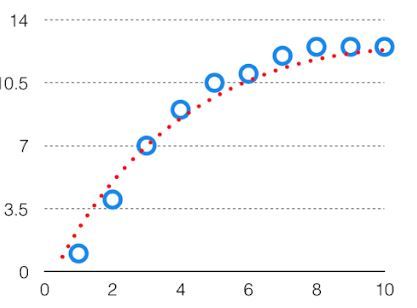
最佳拟合将通过折衷点上的假设给出。
表示权衡的复杂度图误差为– 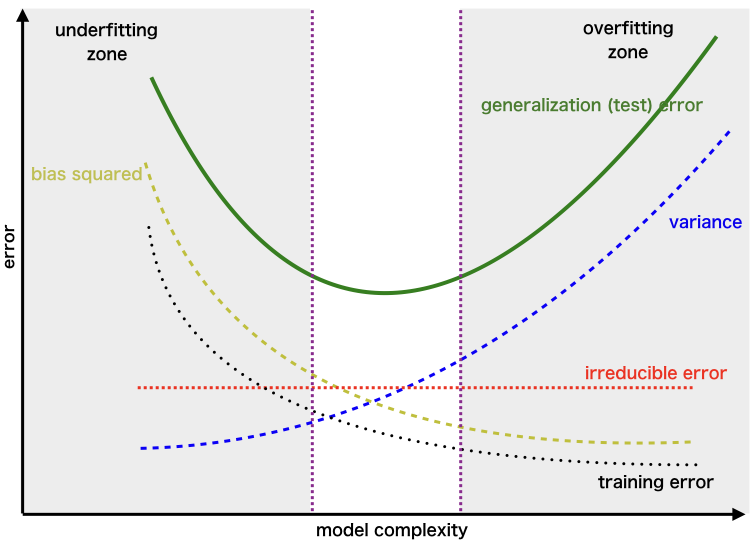
这被称为为算法训练选择的最佳点,该点在训练和测试数据中的错误率低。