尽管本文中讨论的最小编辑距离提供了可能正确的单词的很好的列表,但英语词典中的单词太多了,无法考虑寻找所有对之间的编辑距离。为了简化候选单词的列表,在典型的IR和NLP系统中使用了k-gram重叠。
K-克
K-gram是一个字符串的k个长度的子序列。在这里,k可以是1、2、3,依此类推。对于k = 1,每个结果子序列称为“字母组合”;当k = 2时,是一个“二元图”;对于k = 3,为“ trigram”。这些是最广泛用于拼写校正的k-gram,但是k的值实际上取决于情况和上下文。
例如,考虑字符串“灾难性”。在这种情况下,
- 会标: [“ c”,“ a”,“ t”,“ a”,“ s”,“ t”,“ r”,“ o”,“ p”,“ h”,“ i”,“ c” ]
- 二元组: [“ ca”,“ at”,“ ta”,“ as”,“ st”,“ tr”,“ ro”,“ op”,“ ph”,“ hi”,“ ic”)
- 卦: [“ cat”,“ ata”,“ tas”,“ ast”,“ str”,“ tro”,“ rop”,“ oph”,“ phi”,“ hic”]
克拉姆指数
k-gram索引将k-gram映射到包含该词的所有可能词汇的发布列表。下图显示了与二元组“ ur”相对应的k-gram发布列表。

值得注意的是,发布列表按字母顺序排序。
拼写校正
在创建可能的更正单词的候选列表时,我们可以使用“ k-gram重叠”来找到最可能的更正。
考虑拼写错误的单词:“ appe”。下面显示了其中包含的二元组的发布清单。请注意,这些只是过帐列表的样本子集;当然,实际的帖子列表中将包含数千个单词。
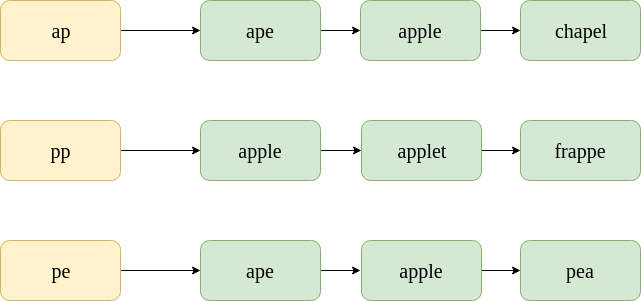
为了找到两个发布清单之间的k-gram重叠,我们使用Jaccard系数。这里,A和B是两个集合(发布列表),A代表拼写错误的单词,B代表更正单词。

现在,考虑一些用于拼写更正的候选术语,即“猿”和“苹果”。
“猿”
要查找Jaccard系数,只需浏览“ appe”的所有双字母组的发布列表,并计算出现“ ape”的实例。
在第一个发布列表中,“猿”出现1次。在第二个发布列表中,“猿”出现0次。在第三个发布列表中,“猿”出现1次。所以, ![]() 。现在,没有。 “ appe”中的二元组的数量为3,否。 “猿”中的二元组的数量是2。因此,
。现在,没有。 “ appe”中的二元组的数量为3,否。 “猿”中的二元组的数量是2。因此, ![]() 。
。
J(A,B)= 2/3 = 0.67。
“苹果” ![]() 。现在,没有。 “ appe”中的二元组的数量为3,否。 “苹果”中的二元组的数量是4。因此,
。现在,没有。 “ appe”中的二元组的数量为3,否。 “苹果”中的二元组的数量是4。因此, ![]() 。
。
J(A,B)= 3/4 = 0.75。
这表明“苹果”是更合理的更正。实际上,此方法用于滤除不太可能的校正。
拼写更正的步骤包括:
- 找到拼写错误的单词的k-gram。
- 对于每个k-gram,线性扫描k-gram索引中的发布列表。
- 线性扫描列表后,找到k-gram重叠(没有额外的时间复杂度,因为我们正在找到Jaccard系数)。
- 返回最大k-gram重叠的项。