数据处理是将数据从给定格式转换为更有用和更理想的格式(即使其更有意义和更有意义)的任务。使用机器学习算法,数学建模和统计知识,可以使整个过程自动化。根据我们正在执行的任务和机器的要求,此完整过程的输出可以采用任何所需的形式,例如图形,视频,图表,表格,图像等。这似乎很简单,但是当涉及到像Twitter,Facebook,Paliament,UNESCO和卫生部门组织这样的大型组织时,整个过程需要以结构化的方式进行。因此,要执行的步骤如下:
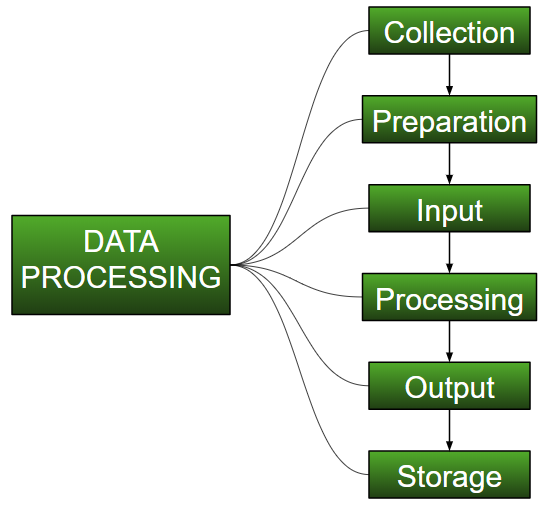
- 收藏 :
开始使用ML时,最关键的步骤是拥有高质量和准确性的数据。可以从任何经过身份验证的来源收集数据,例如data.gov.in,Kaggle或UCI数据集存储库。例如,在准备竞争性考试时,学生将从可以访问的最佳学习材料中学习,从而学习到最好的学习方法最好的结果。同样,高质量,准确的数据将使模型的学习过程变得更加轻松,更好,并且在测试时,该模型将产生最先进的结果。
收集数据会消耗大量的资金,时间和资源。组织或研究人员必须决定执行任务或研究所需的数据类型。
示例:使用面部表情识别器,需要大量具有多种人类表情的图像。良好的数据可确保模型的结果有效并值得信赖。 - 准备 :
收集的数据可以是原始格式,不能直接输入到计算机中。因此,这是一个从不同来源收集数据集,分析这些数据集,然后构建新的数据集以进行进一步处理和探索的过程。可以手动或从自动方法进行此准备。数据也可以以数字形式准备,这也可以加快模型的学习速度。
示例:可以将图像转换为NXN尺寸的矩阵,每个像元的值将指示图像像素。 - 输入 :
现在,准备的数据可以采用机器无法读取的形式,因此要将这些数据转换为可读形式,需要一些转换算法。为了执行该任务,需要高计算量和准确性。示例:可以通过诸如MNIST Digit数据(图像),twitter注释,音频文件,视频剪辑之类的来源来收集数据。 - 加工 :
在这一阶段,需要算法和ML技术来以准确和最佳计算的方式执行大量数据上提供的指令。 - 输出 :
在此阶段,结果由机器以有意义的方式获得,用户可以轻松推断出结果。输出可以是报告,图形,视频等形式 - 贮存 :
这是最后一步,其中将获取的输出和数据模型数据以及所有有用的信息保存起来,以备将来使用。