数据分析是一个过程,使用该过程以有用的方式对原始数据进行清理、转换和建模,以利用它来制定业务决策或发现某些信息。原始数据不能原样使用。数据集中会有很多缺陷,比如缺失值。此外,必须以某种方式处理数据才能找到信息。这种将原始数据转换和映射为其他形式以便有效地用于分析的过程称为数据加工。它也被称为数据整理。它是数据科学中最重要的组成部分之一。一些用于使数据对分析有用的过程是 Split-Apply-Combine 函数。
需要的包裹
数据集可以从RDataset包中加载。 R 语言中可用的标准数据集可通过此包在 Julia 中使用。可以通过在 Julia 终端中编写以下命令来安装它。
julia > Pkg.add(‘RDatasets’)
需要加载数据集并处理多维数组,例如Python的 Pandas 数据框。这里这样的功能是由两个包DataFrames和DataFramesMeta 提供的。这些也可以使用 Julia 终端安装并导入到程序中。要添加这些包,请在终端中键入以下命令。
julia > Pkg.add(‘DataFrames’)
julia > Pkg.add(‘DataFramesMeta’)
需要数据集
为了说明数据处理的概念,本文使用了数据集mtcars 。它包含 1973-74 型号的 32 辆汽车的信息。考虑的特征是燃料消耗和下面列出的一些更多属性。
- mpg – 英里/加仑(美国)。
- cyl – 气缸数。
- disp – 位移 (cu.in)。
- hp –总马力。
- drat – 后轴比。
- wt – 重量
- qsec – 1/4 英里时间
- vs – 发动机形状,其中0 表示 V 型, 1 表示直型。
- am——传输。 0表示自动, 1表示手动。
- 齿轮– 前进档数
- carb – 化油器的数量。
加载数据集
Julia
using RDatasets
cars = dataset("datasets", "mtcars")
head(cars)Julia
using RDatasets
# loading the dataset
cars = dataset("datasets", "mtcars")
# split based on engine type alone
groupby(cars, :VS)Julia
using RDatasets
cars = dataset("datasets", "mtcars")
# split based on engine type
# and number of cylinders
res = groupby(cars, [:Cyl, :VS])
# Show the first group
res[1]Julia
using RDatasets
cars = dataset("datasets", "mtcars")
# splitting based on size
# and displaying eah group's size
by(cars, :Cyl, size)Julia
using RDatasets
using Statistics
cars = dataset("datasets", "mtcars")
# splitting based on no.of.cylinders
# Mean of the miles/gallon is calculated
by(cars, :Cyl, cars->mean(cars[:MPG]))Julia
using RDatasets
using Statistics
cars = dataset("datasets", "mtcars")
# splitting based on transmission and
# no.of.forward gears mean and
# variance of MPG calculation
by(cars, [:AM, :Gear]) do a
DataFrame(Mean_of_MPG = mean(a[:MPG]),
Variance_of_MPG = var(a[:MPG]))
endJulia
using RDatasets
cars = dataset("datasets", "mtcars")
# Splitting based on no.of.cylinders
# display size of each column
println(aggregate(cars, :Cyl, size))输出:
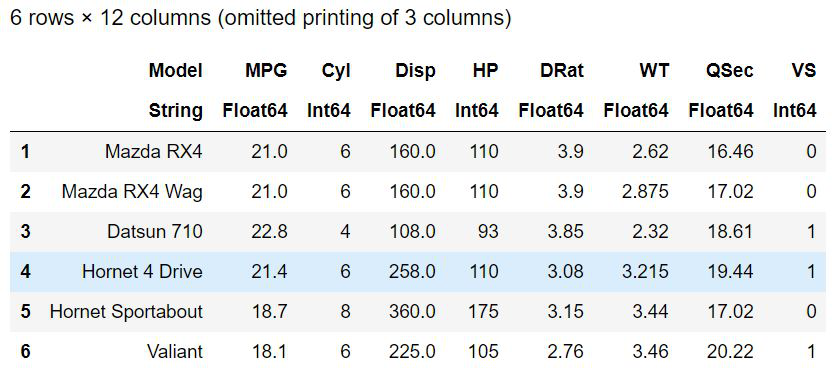
使用 groupby()函数
这里的 groupby()函数根据指定的列对数据进行分组。它是一个仅用于拆分数据帧的函数。如果使用此函数,数据集将被拆分为子集。它返回子集的分组视图。可以使用从1开始的索引访问分组的数据帧。
语法是:
groupby (d, :col_names, sort=false, skipmissing=false)
传递的参数是:
- d – 数据框。
- :col_names – 必须根据其拆分数据集的列。列名应该有一个前面的冒号符号。
- sort – 默认情况下,该值为false并决定返回的数据帧是否应以排序方式进行。
- skipmissing – 决定是否跳过数据集中的缺失值。默认值为false
查看示例以更好地理解。
朱莉娅
using RDatasets
# loading the dataset
cars = dataset("datasets", "mtcars")
# split based on engine type alone
groupby(cars, :VS)
输出:
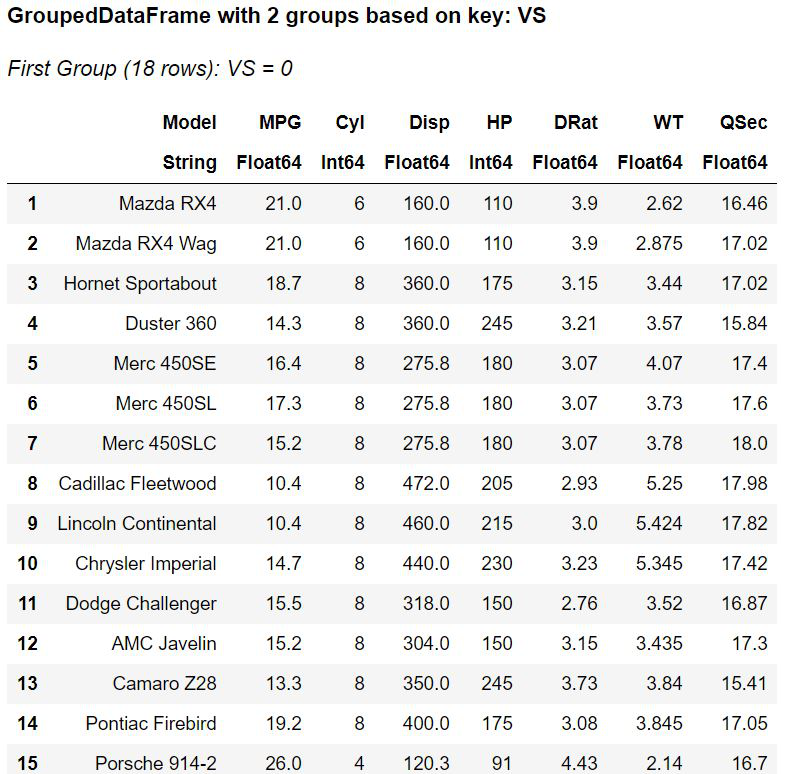

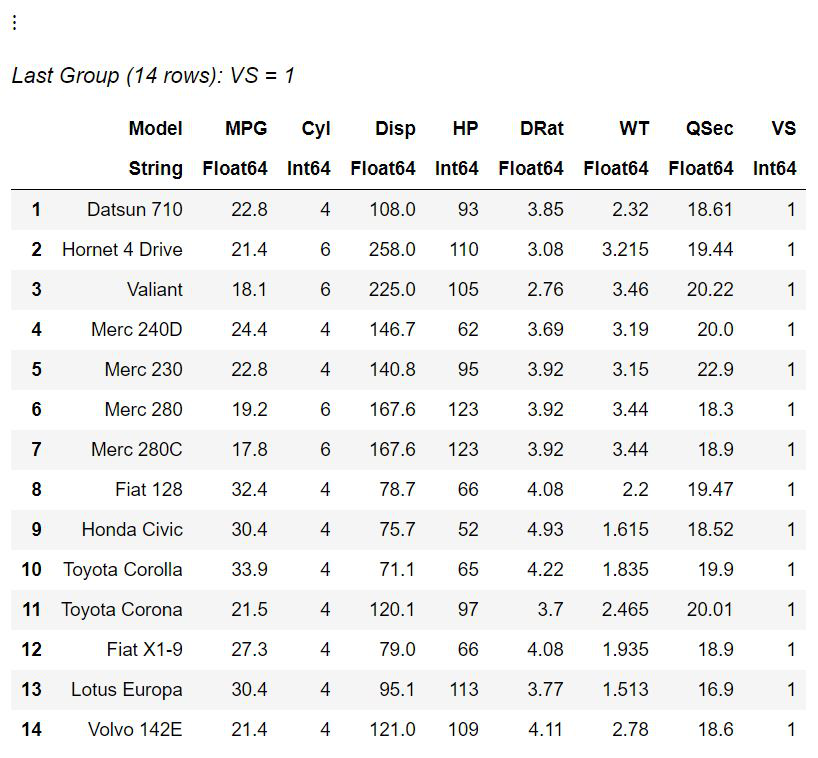
现在根据发动机类型(V 型或直型),数据集分为两部分。所有V型发动机(记为“0” )的车型为第一组,直发发动机的车型为最后一组。如果结果数据帧被分配给一个变量,它也成为一个数据帧,可以使用索引号访问。数据集可以基于多于一列进行拆分。对于基于两个或多个键的拆分,它们必须用方括号括起来。看看下面的代码片段:
朱莉娅
using RDatasets
cars = dataset("datasets", "mtcars")
# split based on engine type
# and number of cylinders
res = groupby(cars, [:Cyl, :VS])
# Show the first group
res[1]
输出:
│ Row │ Model │ MPG │ Cyl │ Disp │ HP │ DRat │ WT │ QSec │ VS │ AM │ Gear │ Carb │
│ │ String │ Float64 │ Int64 │ Float64 │ Int64 │ Float64 │ Float64 │ Float64 │ Int64 │ Int64 │ Int64 │ Int64 │
|——-|———————|———–|——–|———-|——–|———–|———-|———–|——-|———|——–|———|
│ 1 │ Mazda RX4 │ 21.0 │ 6 │ 160.0 │ 110 │ 3.9 │ 2.62 │ 16.46 │ 0 │ 1 │ 4 │ 4 │
│ 2 │ Mazda RX4 Wag │ 21.0 │ 6 │ 160.0 │ 110 │ 3.9 │ 2.875 │ 17.02 │ 0 │ 1 │ 4 │ 4 │
│ 3 │ Ferrari Dino │ 19.7 │ 6 │ 145.0 │ 175 │ 3.62 │ 2.77 │ 15.5 │ 0 │ 1 │ 5 │ 6 │
Models in group 1:[“Mazda RX4”, “Mazda RX4 Wag”, “Ferrari Dino”]
使用 by()函数
它执行拆分应用功能。数据集将在指定的列处拆分,并且提到的函数将应用于每个组。语法如下:
by(d, :col_names, function, sort=false)
参数是:
- d – 数据框
- :col_names – 数据应该被拆分的列。
- 函数– 要应用于每个组的内置或用户定义的函数。
- sort – 决定是否对结果数据帧进行排序。默认值为false 。
示例 1:根据圆柱体数量拆分数据集并显示每组的大小。
朱莉娅
using RDatasets
cars = dataset("datasets", "mtcars")
# splitting based on size
# and displaying eah group's size
by(cars, :Cyl, size)
输出:

数据集分为三组,因为数据集中的任何汽车都包含 6 缸或 4 缸或 8 缸。传递给by()函数的dataframe是cars ,每组的大小,即每组的行数和列数作为元组返回。例如,此处 group-1 包含 7 行和 12 列。
示例 2:根据气缸数拆分数据集并计算每组 Miles/Gallon 的平均值
lambda 类型的函数也可以作为参数传递。用于查找均值、方差、标准差的统计函数可以应用于适当的列。该函数将应用于拆分后产生的组。看看下面的例子。这里的数据集是根据圆柱体的数量分割的。每个组的英里/加仑的平均值是使用 mean()函数计算的,必须为其导入统计包。
朱莉娅
using RDatasets
using Statistics
cars = dataset("datasets", "mtcars")
# splitting based on no.of.cylinders
# Mean of the miles/gallon is calculated
by(cars, :Cyl, cars->mean(cars[:MPG]))
输出:
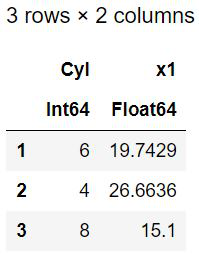
数据集已分为三组, X1列表示每组中英里/加仑的平均值。执行指定的函数并将结果向量添加为单独的列。可以执行多个函数,并且do-block 语法也可以与这个 by()函数结合使用。 do-block作为它前面的函数的参数。对于 by()函数,第一个参数是数据框,下一个是列名,第三个是要执行的函数, do-block充当函数的角色。
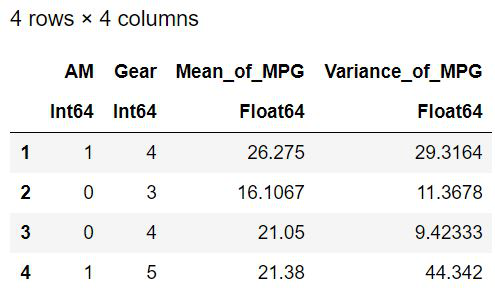
示例 3:根据传输模式和前进档数拆分数据集。计算英里/加仑的均值和方差
朱莉娅
using RDatasets
using Statistics
cars = dataset("datasets", "mtcars")
# splitting based on transmission and
# no.of.forward gears mean and
# variance of MPG calculation
by(cars, [:AM, :Gear]) do a
DataFrame(Mean_of_MPG = mean(a[:MPG]),
Variance_of_MPG = var(a[:MPG]))
end
输出:
使用聚合()函数
该aggregate()函数是一个split-apply-combine函数。它根据指定的列拆分数据帧,将给出的函数应用于拆分数据的所有列,并将它们组合为一个数据帧并返回它。语法如下:
aggregate ( df, :col_names, function)
- df –数据框。
- :col_names – 数据集应该基于哪些列进行拆分。
- 函数 – 要应用于每行的所有列的函数。它可以是单个函数或函数向量。这些函数接受向量作为参数。这些函数应该返回一个相同长度的值或向量。
看看下面的例子。数据集根据柱面数进行拆分,每列的大小作为单个向量返回并组合以形成数据帧。
朱莉娅
using RDatasets
cars = dataset("datasets", "mtcars")
# Splitting based on no.of.cylinders
# display size of each column
println(aggregate(cars, :Cyl, size))
输出:
│ Row │ Cyl │ Model_size │ MPG_size │ Disp_size │ HP_size │ DRat_size │ WT_size │ QSec_size │ VS_size │ AM_size │ Gear_size │ Carb_size │
│ │ Int64 │ Tuple… │ Tuple… │ Tuple… │ Tuple… │ Tuple… │ Tuple… │ Tuple… │ Tuple… │ Tuple… │ Tuple… │ Tuple… │
|——-|———|————-|————–|————|———–|————-|———–|————–|———-|———–|————-|————-|
│ 1 │ 6 │ (7,) │ (7,) │ (7,) │ (7,) │ (7,) │ (7,) │ (7,) │ (7,) │ (7,) │ (7,) │ (7,) │
│ 2 │ 4 │ (11,) │ (11,) │ (11,) │ (11,) │ (11,) │ (11,) │ (11,) │ (11,) │ (11,) │ (11,) │ (11,) │
│ 3 │ 8 │ (14,) │ (14,) │ (14,) │ (14,) │ (14,) │ (14,) │ (14,) │ (14,) │ (14,) │ (14,) │ (14,) │