我们会遇到各种问题,例如字符串的最大回文率,回文子串的数量以及回文子串上的更多有趣问题。大多数回文子串问题都有一些DP O(n 2 )解(n是给定字符串的长度),或者我们有一个复杂的算法,如Manacher算法,它可以在线性时间内解决回文问题。
在本文中,我们将研究一个有趣的数据结构,它将以更简单的方式解决上述所有类似问题。该数据结构是Mikhail Rubinchik发明的。
Features of Palindromic Tree : Online query and updation
Easy to implement
Very Fast回文树的结构
回文树的实际结构接近有向图。它实际上是两个Tree的合并结构,它们共享一些公共节点(请参见下图以更好地理解)。树节点通过存储其索引来存储给定字符串的回文子字符串。
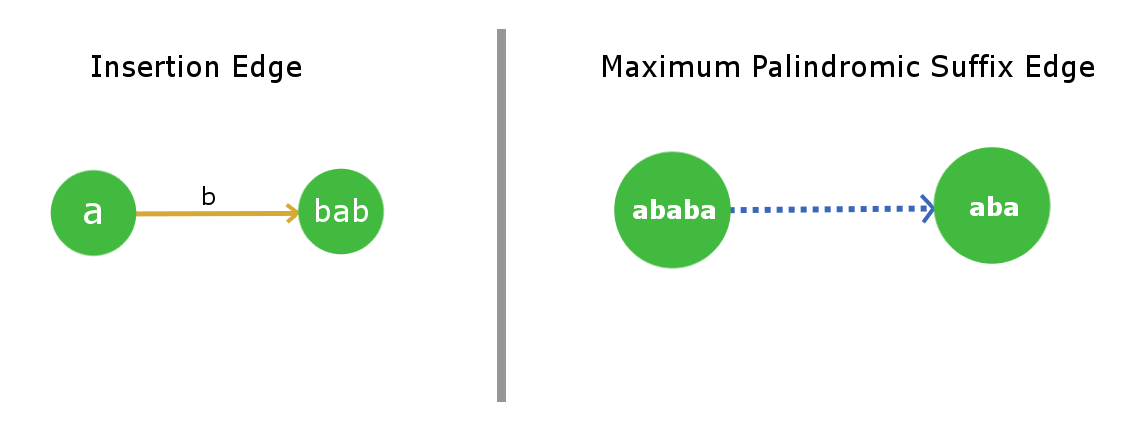
该树由两种类型的边组成:
1)插入边(加权边)
2)最大回文后缀(未加权)
插入边:
从节点u到v的权重为x的插入边意味着节点v是通过在u的字符串的开头和结尾处插入x来形成的。由于u已经是回文,因此节点v处的结果字符串也将是回文。
x将是每个边缘的单个字符。因此,一个节点最多可以有26个插入边(考虑到小写字母字符串)。在我们的图形表示中,我们将为此边缘使用橙色。
最大回文后缀边缘:
顾名思义,对于一个节点,该边将指向其“最大回文后缀字符串”节点。我们不会将完整的字符串本身视为最大回文后缀,因为这没有任何意义(自循环)。为了简单起见,我们将其称为后缀edge(这是指除完整字符串之外的最大后缀)。很明显,每个节点只有1个后缀边缘,因为我们不会在树中存储重复的字符串。我们将使用蓝色虚线边缘作为其图片表示形式。
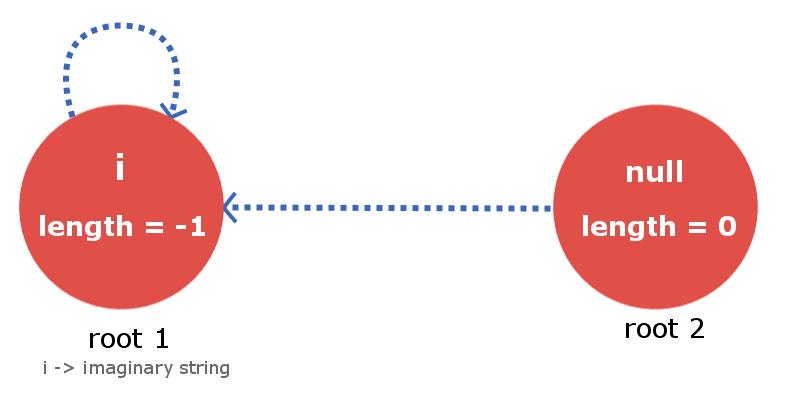
根节点及其约定:
该树/图数据结构将包含2个根虚拟节点。更准确地说,将其视为链接在一起的两棵独立树的根。
根1将是一个虚拟节点,它将描述一个长度= -1的字符串(您可以从实现的角度轻松推断出为什么使用)。根2将是一个节点,它将描述一个长度为0的空字符串。
对于任何长度为-1的假想字符串,根1都有一个连接到其自身的后缀边(自环),其最大回文后缀也将是假想的,因此这是合理的。现在,根2也将其后缀边缘连接到根1,因为对于空字符串(长度为0),没有长度小于0的实际回文后缀字符串。
建造回文树
要构建回文树,我们将简单地将字符逐一插入字符串,直到到达结尾为止。插入完成后,我们将与回文树一起使用,其中将包含给定字符串的所有不同回文子字符串。我们需要确保的是,在每次插入新字符,我们的回文树都保留上述功能。让我们看看如何实现它。
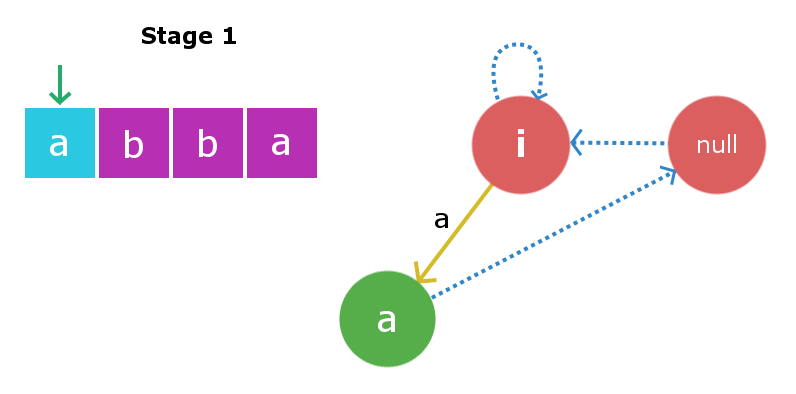
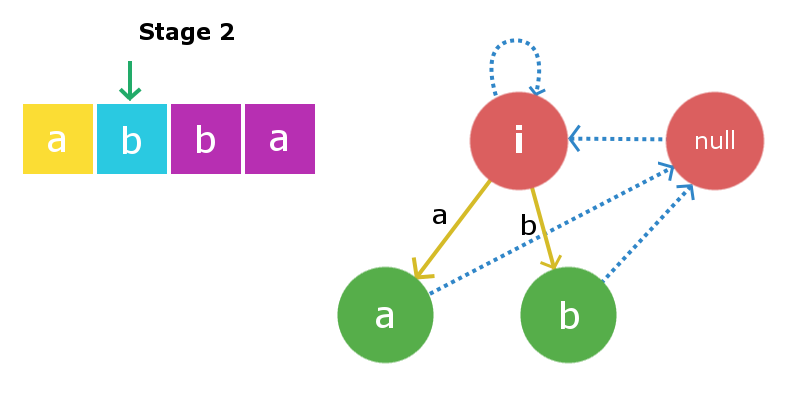
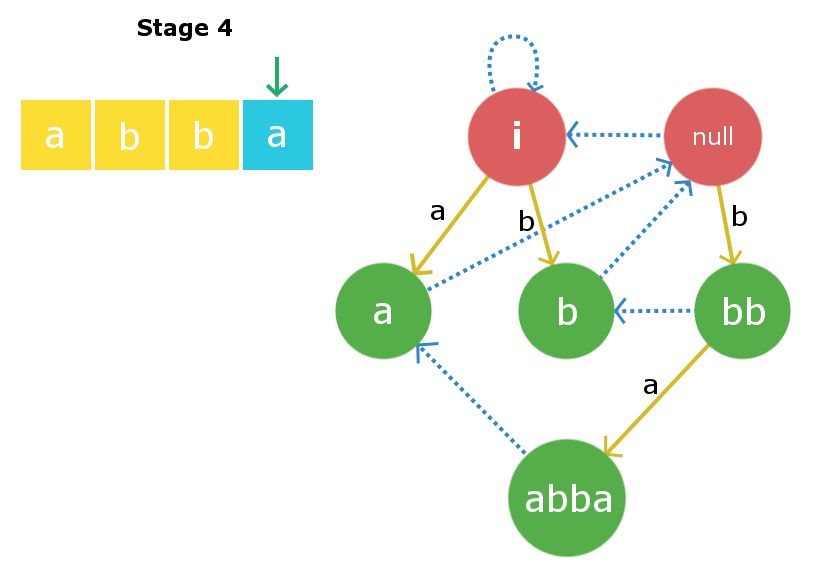
假设我们给了一个长度为l的字符串s ,并将该字符串插入直到索引k (k 因此,要插入字符s [k + 1] ,我们只需要在树中找到字符串X并将插入边从权重为s [k + 1]的X指向一个包含s [k + 1] + X + s [k + 1] 。现在的主要工作是在有效时间内找到字符串X。众所周知,我们正在存储所有节点的后缀链接。因此,要跟踪带有字符串X的节点,我们只需要向下移动当前节点的后缀链接,即包含s [k]的节点。请参阅下图以更好地了解。 下图中的当前节点告诉我们,它是在处理了从0到k的所有索引之后,最大的回文,以索引k结尾。蓝色虚线路径是后缀边缘从当前节点到树中其他已处理节点的链接。字符串X将存在于此后缀链接链上的这些节点之一中。我们需要的是通过在链上进行迭代来找到它。 为了找到包含字符串X的必需节点,我们将第k + 1个字符放在后缀链接链中每个节点的末尾,并检查相应后缀链接字符串的第一个字符是否等于第k + 1个字符字符。 一旦找到X字符串,我们将使用权重为s [k + 1]的插入边进行定向,并将其链接到包含以索引k + 1结尾的最大回文集的新节点。如下图所示,括号之间的数组元素是存储在树中的节点。 还有另一件事要做。由于我们在此s [k + 1]插入处创建了一个新节点,因此我们还必须将其与其后缀链接子级连接起来。一次又一次地这样做,我们将使用上面从节点X开始的后缀链接迭代来找到一些新的字符串Y ,以使s [k + 1] + Y + s [k + 1]是新的最大回文后缀创建的节点。一旦找到它,我们就将新创建的节点的后缀链接与节点Y连接起来。 注意:找到字符串X时有两种可能性。第一种可能性是树中不存在字符串s [k + 1] Xs [k + 1] ,第二种可能性是树中已经存在。在第一种情况下,我们将以相同的方式进行操作,但是在第二种情况下,我们将不会单独创建新节点,而只是将插入边从X链接到X中已经存在的S [k + 1] + X + S [k + 1]节点那个树。我们也不需要添加后缀链接,因为该节点将已经包含其后缀链接。 考虑一个长度为4的字符串s =“ abba ”。 在初始状态下,我们将有两个虚拟根节点,一个的长度为-1(一些虚构的字符串i ),第二个的长度为0的空字符串。这时,我们还没有在树中插入任何字符。 Root1,即长度为-1的根节点将是当前插入发生的节点。 阶段1:我们将插入s [0]即’ a ‘。我们将从当前节点(即Root1)开始检查。在长度为-1的字符串的开头和结尾插入“ a”将产生长度为1的字符串,并且该字符串将为“ a”。因此,我们创建一个新节点“ a”,并将插入边从root1定向到该新节点。现在,长度为1的字符串的最大回文后缀字符串将为空字符串,因此其后缀链接将定向到root2,即空字符串。现在,当前节点将是此新节点“ a”。 阶段2:我们将插入s [1]即’ b ‘。插入过程将从当前节点(即“ a”节点)开始。我们将从当前节点开始遍历后缀链接链,直到找到合适的X字符串。因此在这里遍历后缀链接,我们再次发现root1为X字符串。再次在长度为-1的字符串中插入“ b”将产生长度为1的字符串,即字符串“ b”。如上面插入中所述,此节点的后缀链接将转到空字符串。现在,当前节点将是这个新节点“ b”。 第三阶段:我们将插入s [2]即’ b ‘。再次从当前节点开始,我们将遍历其后缀链接以找到所需的X字符串。在这种情况下,它被发现是root2,即空字符串,因为在空字符串的前端和末尾添加“ b”会产生长度为2的回文“ bb”。因此,我们将创建一个新节点“ bb ”并定向插入边从空字符串到新创建的字符串。现在,此当前节点的最大后缀回文将是节点“ b”。因此,我们将后缀边缘从这个新创建的节点链接到节点“ b”。现在,当前节点变为节点“ bb”。 阶段4:我们将插入s [3]即’ a ‘。插入过程从当前节点开始,在这种情况下,当前节点本身是最大的X字符串,因此s [0] + X + s [3]是回文。因此,我们将创建一个新节点“ abba ”,并将插入边从当前节点“ bb”链接到边缘权重为“ a”的这个新创建的节点。现在,来自这个新创建的节点的链接的后缀将链接到节点“ a”,因为这是最大回文后缀。 下面给出了上述实现的C++实现: 输出: 时间复杂度 参考 :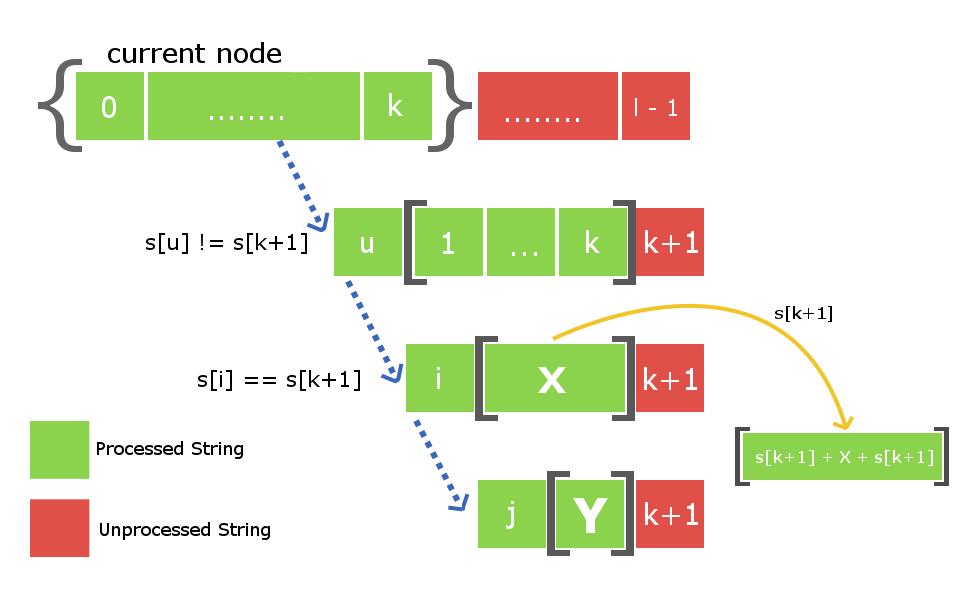


// C++ program to demonstrate working of
// palindromic tree
#include "bits/stdc++.h"
using namespace std;
#define MAXN 1000
struct Node
{
// store start and end indexes of current
// Node inclusively
int start, end;
// stores length of substring
int length;
// stores insertion Node for all characters a-z
int insertEdg[26];
// stores the Maximum Palindromic Suffix Node for
// the current Node
int suffixEdg;
};
// two special dummy Nodes as explained above
Node root1, root2;
// stores Node information for constant time access
Node tree[MAXN];
// Keeps track the current Node while insertion
int currNode;
string s;
int ptr;
void insert(int idx)
{
//STEP 1//
/* search for Node X such that s[idx] X S[idx]
is maximum palindrome ending at position idx
iterate down the suffix link of currNode to
find X */
int tmp = currNode;
while (true)
{
int curLength = tree[tmp].length;
if (idx - curLength >= 1 and s[idx] == s[idx-curLength-1])
break;
tmp = tree[tmp].suffixEdg;
}
/* Now we have found X ....
* X = string at Node tmp
* Check : if s[idx] X s[idx] already exists or not*/
if(tree[tmp].insertEdg[s[idx]-'a'] != 0)
{
// s[idx] X s[idx] already exists in the tree
currNode = tree[tmp].insertEdg[s[idx]-'a'];
return;
}
// creating new Node
ptr++;
// making new Node as child of X with
// weight as s[idx]
tree[tmp].insertEdg[s[idx]-'a'] = ptr;
// calculating length of new Node
tree[ptr].length = tree[tmp].length + 2;
// updating end point for new Node
tree[ptr].end = idx;
// updating the start for new Node
tree[ptr].start = idx - tree[ptr].length + 1;
//STEP 2//
/* Setting the suffix edge for the newly created
Node tree[ptr]. Finding some String Y such that
s[idx] + Y + s[idx] is longest possible
palindromic suffix for newly created Node.*/
tmp = tree[tmp].suffixEdg;
// making new Node as current Node
currNode = ptr;
if (tree[currNode].length == 1)
{
// if new palindrome's length is 1
// making its suffix link to be null string
tree[currNode].suffixEdg = 2;
return;
}
while (true)
{
int curLength = tree[tmp].length;
if (idx-curLength >= 1 and s[idx] == s[idx-curLength-1])
break;
tmp = tree[tmp].suffixEdg;
}
// Now we have found string Y
// linking current Nodes suffix link with s[idx]+Y+s[idx]
tree[currNode].suffixEdg = tree[tmp].insertEdg[s[idx]-'a'];
}
// driver program
int main()
{
// initializing the tree
root1.length = -1;
root1.suffixEdg = 1;
root2.length = 0;
root2.suffixEdg = 1;
tree[1] = root1;
tree[2] = root2;
ptr = 2;
currNode = 1;
// given string
s = "abcbab";
int l = s.length();
for (int i=0; iAll distinct palindromic substring for abcbab :
1)a
2)b
3)c
4)bcb
5)abcba
6)bab
构建过程的时间复杂度为O(k * n) ,这里的“ n ”是字符串的长度,“ k ”是每次我们在后缀链接中找到字符串X和字符串Y所需的额外迭代插入一个字符。让我们尝试近似常数“ k”。我们将考虑最糟糕的情况,例如s =“ aaaaaabcccccccccdeeeeeeeeeeef” 。在这种情况下,对于连续字符的类似条纹,每个索引将花费额外的2次迭代才能在后缀链接中找到字符串X和Y,但是一旦到达某个索引i ,则s [i]!= s [i- 1]最大长度后缀的最左边的指针将达到其最右边的限制。因此,对于所有当s [i]!= s [i-1]的i ,它将花费总共n次迭代(每次迭代的总和),而对于其余的i,当s [i] == s [i-1]时,它将花费进行2次迭代,将所有此类i相加,并进行2 * n次迭代。因此,在这种情况下,我们的复杂度大约为O(3 * n)〜O(n)。因此,我们可以粗略地说出常数因子“ k”将非常小。因此,我们可以认为总体复杂度为线性O( 字符串的长度) 。您可以参考参考链接以更好地理解。