BK树或Burkhard Keller树是一种数据结构,用于根据“编辑距离”(Levenshtein距离)概念执行拼写检查。 BK树也用于近似字符串匹配。基于此数据结构,可以在许多软件中实现各种自动更正功能。
Pre-requisites : Edit distance Problem
Metric tree
假设我们有一个单词词典,然后还有一些其他单词要在词典中检查拼写错误。我们需要收集字典中与给定单词非常接近的所有单词。例如,如果我们检查单词“ ruk ”,我们将得到{“ truck”,“ buck”,“ duck”,……} 。因此,可以通过从单词中删除字符或在单词中添加新字符或通过用适当的字符替换单词中的字符来纠正拼写错误。因此,我们将使用编辑距离作为字典中单词与拼写错误单词的正确性和匹配性的度量。
现在,让我们看看BK树的结构。像所有其他树一样,BK树由节点和边组成。 BK树中的节点将代表字典中的各个单词,并且节点数将与字典中的单词数完全相同。边缘将包含一些整数权重,该权重将告诉我们有关从一个节点到另一个节点的编辑距离。假设我们有一个从节点u到节点v的边,其边缘权重为w ,则w是将字符串u转换为v所需的编辑距离。
考虑一下我们的字典中的单词: {“ help”,“ hell”,“ hello”} 。因此,对于这本词典,我们的BK树将如下图所示。 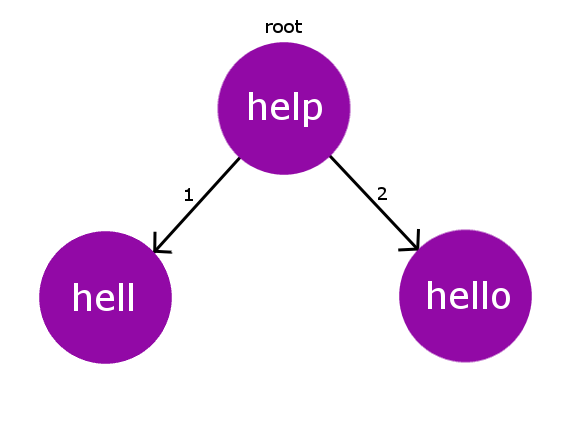
BK树中的每个节点将只有一个孩子,其编辑距离相同。如果在插入时遇到编辑距离冲突,我们将沿着子节点传播插入过程,直到为字符串节点找到合适的父节点为止。
BK树中的每个插入都将从我们的根节点开始。根节点可以是我们词典中的任何单词。
例如,让我们在上面的字典中添加另一个单词“ shell ”。现在我们的Dict [] = {“ help”,“ hell”,“ hello”,“ shell”} 。现在很明显,“ shell ”与“ hello ”与根节点“ help ”(即2)具有相同的编辑距离。因此,我们遇到了冲突。因此,我们通过在预先存在的冲突节点上递归执行此插入过程来解决此冲突。
因此,现在,我们将其插入冲突节点“ hello ”中,而不是在根节点“ help ”中插入“ shell ”。因此,现在将新节点“ shell ”添加到树中,并且将其节点“ hello ”作为其父节点,其边沿宽度为2(编辑距离)。下面的图片表示形式描述了此插入之后的BK树。
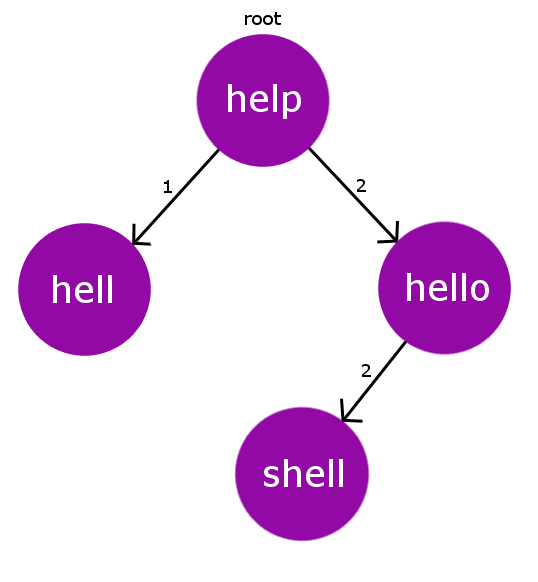
因此,到目前为止,我们已经了解了如何构建BK树。现在,出现了一个问题,即如何为拼写错误的单词找到最接近的正确单词?首先,我们需要设置一个公差值。该容差值只是从拼写错误的单词到词典中正确的单词的最大编辑距离。因此,要找到在容限范围内的合格正确单词,天真的方法将是对字典中的所有单词进行迭代,并收集在容限范围内的单词。但是这种方法具有O(n * m * n)的时间复杂度( n是dict []中的单词数, m是正确单词的平均大小, n是拼写错误的单词的长度),对于较大的字典而言会超时。
因此,现在BK树开始起作用。众所周知,BK树中的每个节点都是基于与其父节点之间的编辑距离度量构建的。因此,我们将直接从根节点转到位于容限范围内的特定节点。假设我们的公差极限为TOL ,而当前节点到拼写错误的单词的编辑距离为dist 。因此,现在不再遍历其所有子项,而是仅遍历其范围内具有编辑距离的子项。
[ dist-TOL,dist + TOL ]。这将在很大程度上降低我们的复杂性。我们将在时间复杂度分析中对此进行讨论。
考虑下面构造的BK树。
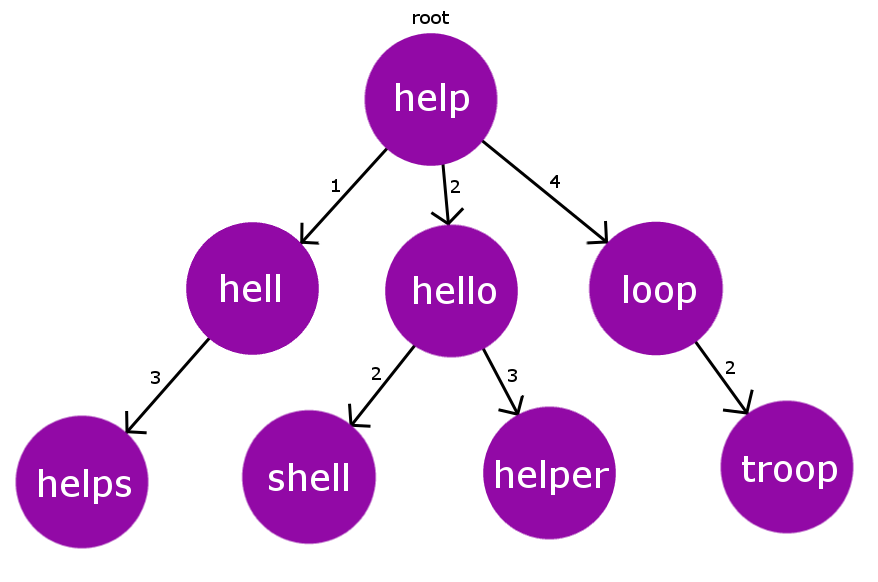
假设我们有一个拼写错误的单词“ oop ”,容限为2。现在,我们将看到如何收集给定拼写错误单词的期望正确率。
迭代1:我们将开始检查到根节点的编辑距离。 D(“ oop”->“ help”)=3。现在,我们将遍历其编辑距离范围为[D-TOL,D + TOL]即[1,5]的子级。
迭代2:让我们从可能的最大编辑距离子级开始迭代,即节点“循环”的编辑距离为4。现在,我们将再次从拼写错误的单词中找到其编辑距离。 D(“ oop”,“ loop”)= 1。
这里D = 1,即D <= TOL,因此我们将“ loop”添加到预期的正确单词列表中,并处理其编辑距离在[D-TOL,D + TOL]范围内的子节点,即[1,3]
迭代3:现在,我们在节点“ troop”处。我们将再次检查其与拼写错误的单词的编辑距离。 D(“ oop”,“ troop”)= 2。这里再次是D <= TOL,因此我们再次将“ troop”添加到预期的正确单词列表中。
从根节点到最底部的叶节点,我们将对[D-TOL,D + TOL]范围内的所有单词进行相同的处理。这类似于在树上进行DFS遍历,有选择地访问其边权重在某个给定范围内的子节点。
因此,最后我们只剩下2个预期单词,用于拼写错误的单词“ oop ”,即{“ loop”,“ troop”}
// C++ program to demonstrate working of BK-Tree
#include "bits/stdc++.h"
using namespace std;
// maximum number of words in dict[]
#define MAXN 100
// defines the tolerence value
#define TOL 2
// defines maximum length of a word
#define LEN 10
struct Node
{
// stores the word of the current Node
string word;
// links to other Node in the tree
int next[2*LEN];
// constructors
Node(string x):word(x)
{
// initializing next[i] = 0
for(int i=0; i<2*LEN; i++)
next[i] = 0;
}
Node() {}
};
// stores the root Node
Node RT;
// stores every Node of the tree
Node tree[MAXN];
// index for current Node of tree
int ptr;
int min(int a, int b, int c)
{
return min(a, min(b, c));
}
// Edit Distance
// Dynamic-Approach O(m*n)
int editDistance(string& a,string& b)
{
int m = a.length(), n = b.length();
int dp[m+1][n+1];
// filling base cases
for (int i=0; i<=m; i++)
dp[i][0] = i;
for (int j=0; j<=n; j++)
dp[0][j] = j;
// populating matrix using dp-approach
for (int i=1; i<=m; i++)
{
for (int j=1; j<=n; j++)
{
if (a[i-1] != b[j-1])
{
dp[i][j] = min( 1 + dp[i-1][j], // deletion
1 + dp[i][j-1], // insertion
1 + dp[i-1][j-1] // replacement
);
}
else
dp[i][j] = dp[i-1][j-1];
}
}
return dp[m][n];
}
// adds curr Node to the tree
void add(Node& root,Node& curr)
{
if (root.word == "" )
{
// if it is the first Node
// then make it the root Node
root = curr;
return;
}
// get its editDist from the Root Node
int dist = editDistance(curr.word,root.word);
if (tree[root.next[dist]].word == "")
{
/* if no Node exists at this dist from root
* make it child of root Node*/
// incrementing the pointer for curr Node
ptr++;
// adding curr Node to the tree
tree[ptr] = curr;
// curr as child of root Node
root.next[dist] = ptr;
}
else
{
// recursively find the parent for curr Node
add(tree[root.next[dist]],curr);
}
}
vector getSimilarWords(Node& root,string& s)
{
vector < string > ret;
if (root.word == "")
return ret;
// calculating editdistance of s from root
int dist = editDistance(root.word,s);
// if dist is less than tolerance value
// add it to similar words
if (dist <= TOL) ret.push_back(root.word);
// iterate over the string havinng tolerane
// in range (dist-TOL , dist+TOL)
int start = dist - TOL;
if (start < 0)
start = 1;
while (start < dist + TOL)
{
vector tmp =
getSimilarWords(tree[root.next[start]],s);
for (auto i : tmp)
ret.push_back(i);
start++;
}
return ret;
}
// driver program to run above functions
int main(int argc, char const *argv[])
{
// dictionary words
string dictionary[] = {"hell","help","shel","smell",
"fell","felt","oops","pop","oouch","halt"
};
ptr = 0;
int sz = sizeof(dictionary)/sizeof(string);
// adding dict[] words on to tree
for(int i=0; i match = getSimilarWords(RT,w1);
cout << "similar words in dictionary for : " << w1 << ":\n";
for (auto x : match)
cout << x << endl;
match = getSimilarWords(RT,w2);
cout << "Correct words in dictionary for " << w2 << ":\n";
for (auto x : match)
cout << x << endl;
return 0;
}
输出:
Correct words in dictionary for ops:
oops
pop
Correct words in dictionary for helt:
hell
help
fell
shel
felt
halt
时间复杂度:很明显,时间复杂度主要取决于公差极限。我们将考虑公差极限为2 。现在,粗略估计,BK树的深度将为log n,其中n是字典的大小。在每个级别上,我们都将访问树中的2个节点并执行编辑距离计算。因此,我们的时间复杂度将是O(L1 * L2 * log n) ,这里L1是字典中单词的平均长度,而L2是拼写错误的长度。通常,L1和L2将很小。
参考
- https://zh.wikipedia.org/wiki/BK-树
- https://issues.apache.org/jira/browse/LUCENE-2230