以给定的比例随机划分 Pandas DataFrame
在机器学习、人工智能等领域将给定的数据集拆分为训练和测试数据以用于训练和测试目的的情况下,划分 Pandas Dataframe 任务非常有用。让我们看看如何将 Pandas 数据帧随机划分为给定的比率。对于这个任务,我们将使用Dataframe.sample()和 熊猫数据帧的Dataframe.drop()方法一起。
这些函数的语法如下——
- 数据框.sample()
Syntax: DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
Return Type: A new object of same type as caller containing n items randomly sampled from the caller object.
- 数据框.drop()
Syntax: DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors=’raise’)
Return: Dataframe with dropped values.
示例:现在,让我们创建一个数据框:
Python3
# Importing required libraries
import pandas as pd
record = {
'course_name': ['Data Structures', 'Python',
'Machine Learning', 'Web Development'],
'student_name': ['Ankit', 'Shivangi',
'Priya', 'Shaurya'],
'student_city': ['Chennai', 'Pune',
'Delhi', 'Mumbai'],
'student_gender': ['M', 'F',
'F', 'M'] }
# Creating a dataframe
df = pd.DataFrame(record)
# show the dataframe
dfPython3
# Importing required libraries
import pandas as pd
record = {
'course_name': ['Data Structures', 'Python',
'Machine Learning', 'Web Development'],
'student_name': ['Ankit', 'Shivangi',
'Priya', 'Shaurya'],
'student_city': ['Chennai', 'Pune',
'Delhi', 'Mumbai'],
'student_gender': ['M', 'F',
'F', 'M'] }
# Creating a dataframe
df = pd.DataFrame(record)
# Creating a dataframe with 50%
# values of original dataframe
part_50 = df.sample(frac = 0.5)
# Creating dataframe with
# rest of the 50% values
rest_part_50 = df.drop(part_50.index)
print("\n50% of the given DataFrame:")
print(part_50)
print("\nrest 50% of the given DataFrame:")
print(rest_part_50)Python3
# Importing required libraries
import pandas as pd
record = {
'course_name': ['Data Structures', 'Python',
'Machine Learning', 'Web Development'],
'student_name': ['Ankit', 'Shivangi',
'Priya', 'Shaurya'],
'student_city': ['Chennai', 'Pune',
'Delhi', 'Mumbai'],
'student_gender': ['M', 'F',
'F', 'M'] }
# Creating a dataframe
df = pd.DataFrame(record)
# Creating a dataframe with 75%
# values of original dataframe
part_75 = df.sample(frac = 0.75)
# Creating dataframe with
# rest of the 25% values
rest_part_25 = df.drop(part_75.index)
print("\n75% of the given DataFrame:")
print(part_75)
print("\nrest 25% of the given DataFrame:")
print(rest_part_25)输出:
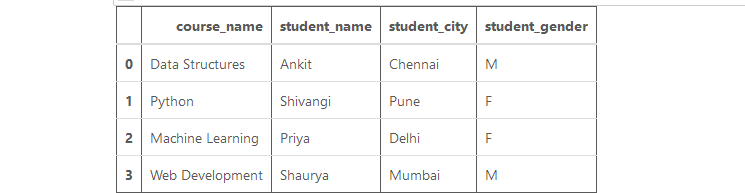
数据框
示例 1:将 Dataframe 随机分成 1:1 的比例。
Python3
# Importing required libraries
import pandas as pd
record = {
'course_name': ['Data Structures', 'Python',
'Machine Learning', 'Web Development'],
'student_name': ['Ankit', 'Shivangi',
'Priya', 'Shaurya'],
'student_city': ['Chennai', 'Pune',
'Delhi', 'Mumbai'],
'student_gender': ['M', 'F',
'F', 'M'] }
# Creating a dataframe
df = pd.DataFrame(record)
# Creating a dataframe with 50%
# values of original dataframe
part_50 = df.sample(frac = 0.5)
# Creating dataframe with
# rest of the 50% values
rest_part_50 = df.drop(part_50.index)
print("\n50% of the given DataFrame:")
print(part_50)
print("\nrest 50% of the given DataFrame:")
print(rest_part_50)
输出:

划分数据框
示例 2:将 Dataframe 随机分成 3:1 的比例。
Python3
# Importing required libraries
import pandas as pd
record = {
'course_name': ['Data Structures', 'Python',
'Machine Learning', 'Web Development'],
'student_name': ['Ankit', 'Shivangi',
'Priya', 'Shaurya'],
'student_city': ['Chennai', 'Pune',
'Delhi', 'Mumbai'],
'student_gender': ['M', 'F',
'F', 'M'] }
# Creating a dataframe
df = pd.DataFrame(record)
# Creating a dataframe with 75%
# values of original dataframe
part_75 = df.sample(frac = 0.75)
# Creating dataframe with
# rest of the 25% values
rest_part_25 = df.drop(part_75.index)
print("\n75% of the given DataFrame:")
print(part_75)
print("\nrest 25% of the given DataFrame:")
print(rest_part_25)
输出:

划分数据框