查找 Pandas DataFrame 列的分位数和十分位数排名
分位数是将样本划分为大小相等、相邻的子组的位置。
中位数是分位数;中位数放置在概率分布中,以便恰好一半的数据低于中位数,而一半的数据高于中位数。中位数将分布分成两个相等的区域,因此有时称为 2 分位数。
四分位数也是分位数;他们将分布分成四个相等的部分。
百分位数是将分布划分为 100 个相等部分的分位数,而十分位数是将分布划分为 10 个相等部分的分位数。
我们可以使用以下公式来估计第 i个观测值:
ith observation = q (n + 1)其中q是分位数,低于您正在寻找的第 i个值的比例
n是数据集中的项目数。
因此,为了找到分位数等级,q 应该是 0.25,因为我们希望将我们的数据集分成 4 个相等的部分,并根据它们所在的四分位数对 0-3 的值进行排名。
同样对于十分位秩,q 应该是 0.1,因为我们希望我们的数据集被分成 10 个相等的部分。
在转向 Pandas 之前,让我们在一个示例中尝试上述概念,以了解我们的分位数和十分位数排名是如何计算的。
示例问题:在以下数据集中找出 25% 的值低于它,75% 的值高于它的数字。
数据: 32、47、55、62、74、77、86
步骤 1:将数据从小到大排序。问题中的数据已经按升序排列。
第 2 步:计算数据集中有多少观察值。这个特定的数据集有 7 个项目。
第 3 步:将“q”的任何百分比转换为小数。我们正在寻找 25% 的值低于它的数字,因此将其转换为 0.25。
第 4 步:将您的值插入公式中:
回答:
第 i个观察值 = q (n + 1)
第 i个观察值 = .25(7 + 1) = 2
第 i个观察值是 2。集合中的第二个数字是 47,这是 25% 的值低于它的数字。然后我们可以从 0-3 开始对我们的数字进行排名,因为我们正在寻找分位数排名。寻找十分位秩的类似方法,在这种情况下,它只是 q 的值将是 0.1。
现在让我们看看 Pandas 如何快速实现这一目标。
创建数据框的代码:
python3
# Import pandas
import pandas as pd
# Create a DataFrame
df1 = {'Name':['George', 'Andrea', 'John', 'Helen',
'Ravi', 'Julia', 'Justin'],
'EnglishScore':[62, 47, 55, 74, 32, 77, 86]}
df1 = pd.DataFrame(df1, columns = ['Name', ''])
# Sorting the DataFrame in Ascending Order of English Score
df1.sort_values(by =['EnglishScore'], inplace = True)python3
# code
df1['QuantileRank']= pd.qcut(df1['EnglishScore'],
q = 4, labels = False)python3
# code
df1['DecileRank']= pd.qcut(df1['EnglishScore'],
q = 10, labels = False)python3
# code
import pandas as pd
# Create a DataFrame
df1 = {'Name':['George', 'Andrea', 'John', 'Helen',
'Ravi', 'Julia', 'Justin'],
'EnglishScore':[62, 47, 55, 74, 32, 77, 86]}
df1 = pd.DataFrame(df1, columns =['Name', 'EnglishScore'])
# Sorting the DataFrame in Ascending Order of English Score
# Sorting just for the purpose of better data readability.
df1.sort_values(by =['EnglishScore'], inplace = True)
# Calculating Quantile Rank
df1['QuantileRank']= pd.qcut(df1['EnglishScore'], q = 4, labels = False)
# Calculating Decile Rank
df1['DecileRank'] = pd.qcut(df1['EnglishScore'], q = 10, labels = False)
# printing the dataframe
print(df1)如果我们打印上面的数据框,我们会得到以下结果:

数据框
现在我们可以使用 pandas函数qcut()找到分位数排名,方法是传递要考虑排名的列名,参数q的值表示分位数。 10 表示十分位数,4 表示四分位数等, labels = False将 bin 作为整数返回。
以下是分位数排名的代码
蟒蛇3
# code
df1['QuantileRank']= pd.qcut(df1['EnglishScore'],
q = 4, labels = False)
现在,如果我们打印数据框,我们可以看到新列 QauntileRank 基于 EnglishScore 列对我们的数据进行排名。
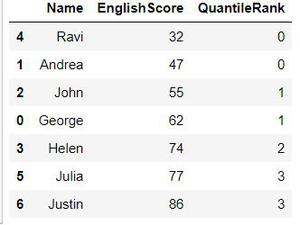
分位数等级
类似地计算 Decile Rank 我们设置q = 10
蟒蛇3
# code
df1['DecileRank']= pd.qcut(df1['EnglishScore'],
q = 10, labels = False)
现在,如果我们打印我们的 DataFrame,我们会得到以下输出。
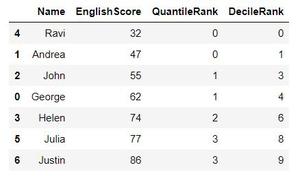
十等分等级
这就是我们如何使用 Pandas qcut()方法来计算列上的各种分位数。
上面示例的完整代码如下所示。
蟒蛇3
# code
import pandas as pd
# Create a DataFrame
df1 = {'Name':['George', 'Andrea', 'John', 'Helen',
'Ravi', 'Julia', 'Justin'],
'EnglishScore':[62, 47, 55, 74, 32, 77, 86]}
df1 = pd.DataFrame(df1, columns =['Name', 'EnglishScore'])
# Sorting the DataFrame in Ascending Order of English Score
# Sorting just for the purpose of better data readability.
df1.sort_values(by =['EnglishScore'], inplace = True)
# Calculating Quantile Rank
df1['QuantileRank']= pd.qcut(df1['EnglishScore'], q = 4, labels = False)
# Calculating Decile Rank
df1['DecileRank'] = pd.qcut(df1['EnglishScore'], q = 10, labels = False)
# printing the dataframe
print(df1)