使用 CatBoost 编码器进行分类编码
许多机器学习算法要求数据是数字的。因此,在训练模型之前,我们需要将分类数据转换为数字形式。有多种分类编码方法可用。 Catboost 就是其中之一。 Catboost 是一个基于目标的分类编码器。它是一种监督编码器,根据目标值对分类列进行编码。它支持二项式和连续目标。
目标编码是一种用于分类编码的流行技术。它用与训练数据集中该类别相对应的目标的平均值与整个数据集的目标概率相结合来替换分类特征。但这会引入目标泄漏,因为目标用于预测目标。这样的模型往往会过度拟合,并且在看不见的情况下不能很好地概括。
CatBoost 编码器类似于目标编码,但还涉及排序原则以克服目标泄漏问题。它使用类似于时间序列数据验证的原理。目标统计的值依赖于观察到的历史,即当前特征的目标概率仅从它之前的行(观察)计算。
分类特征值使用以下公式进行编码:
TargetCount :该特定分类特征的目标值的总和(直到当前)。
先前:它是由(整个数据集中目标值的总和)/(数据集中的观察(即行)总数)确定的常数值
FeatureCount :观察到的分类特征的总数,直到当前特征与当前特征具有相同的值。
使用这种方法,数据集中的前几个观测值总是具有比连续观测值更高方差的目标统计量。为了减少这种影响,使用相同数据的许多随机排列来计算目标统计数据,并通过对这些排列进行平均来计算最终编码。因此,如果排列数量足够大,则最终编码值遵循以下等式:
TargetCount :整个数据集中该特定分类特征的目标值的总和。
先前:它是由(整个数据集中目标值的总和)/(数据集中的观察(即行)总数)确定的常数值
FeatureCount :在整个数据集中观察到的与当前值相同的分类特征总数。
例如,如果我们有带有值的分类特征列
color=[“red”, “blue”, “blue”, “green”, “red”, “red”, “black”, “black”, “blue”, “green”] 和带有值的目标列,目标=[1, 2, 3, 2, 3, 1, 4, 4, 2, 3]
那么,先验将是25/10 = 2.5
对于“红色”类别,TargetCount 将为 1+3+1 = 5 且 FeatureCount = 3
因此,“红色”的编码值将是 (5+2.5) /(3+1)=1.875
句法:
category_encoders.cat_boost.CatBoostEncoder(verbose=0,
cols=None, drop_invariant=False, return_df=True,
handle_unknown='value', handle_missing='value',
random_state=None, sigma=None, a=1)参数:
- verbose : 输出的详细程度,即是否在屏幕上打印处理输出。 0 表示不打印,正值表示打印中间处理输出。
- cols :要编码的特征(列)列表。默认情况下,它是None表示所有具有对象数据类型的列都将被编码。
- drop_invariant : True表示删除方差为零的列(每行的值相同)。错误,默认情况下。
- return_df : True 从转换返回一个 Pandas 数据帧,False 将返回 numpy 数组。没错,默认情况下。
- handle_missing :处理缺失(未填充)值的方式。 error生成缺失值错误, return_nan返回 NaN, value返回目标均值。默认值为值。
- handle_unknown :处理未知(未定义)值的方式。选项与handle_missing参数相同。
- sigma :用于减少过拟合。训练数据添加了正态分布噪声,而测试数据保持不变。 sigma 是该正态分布的标准差。
- a :用于附加平滑的浮点值。当属性或数据点不存在于训练数据集中但可能存在于测试数据集中时,需要它。默认设置为1,如果不为1,则包含该平滑参数后的编码方程为以下形式:

编码器可用作categorical-encodings库中的 CatBoostEncoder。这个编码器的工作原理类似于 scikit-learn 转换器,带有.fit_transform() 、 .fit()和.transform()方法。
例子:
Python3
# import libraries
import category_encoders as ce
import pandas as pd
# Make dataset
train = pd.DataFrame({
'color': ["red", "blue", "blue", "green", "red",
"red", "black", "black", "blue", "green"],
'interests': ["sketching", "painting", "instruments",
"sketching", "painting", "video games",
"painting", "instruments", "sketching",
"sketching"],
'height': [68, 64, 87, 45, 54, 64, 67, 98, 90, 87],
'grade': [1, 2, 3, 2, 3, 1, 4, 4, 2, 3], })
# Define train and target
target = train[['grade']]
train = train.drop('grade', axis = 1)
# Define catboost encoder
cbe_encoder = ce.cat_boost.CatBoostEncoder()
# Fit encoder and transform the features
cbe_encoder.fit(train, target)
train_cbe = cbe_encoder.transform(train)
# We can use fit_transform() instead of fit()
# and transform() separately as follows:
# train_cbe = cbe_encoder.fit_transform(train,target)输出:
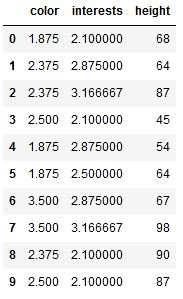
Catboost 编码后的数据集 (train_cbe)