Python – 使用 Sunbird 进行分类编码
Sunbird库是用于特征工程目的的最佳选择。在这个库中,您将获得处理缺失值、异常值、分类编码、归一化和标准化、特征选择技术等的各种技术。它可以使用以下命令进行安装:
pip install sunbird分类编码
分类数据是一种常见的非数字数据类型,它包含标签值而不是数字。一些例子包括:
颜色:白色、黑色、绿色。城市:孟买、浦那、德里。性别:男,女。
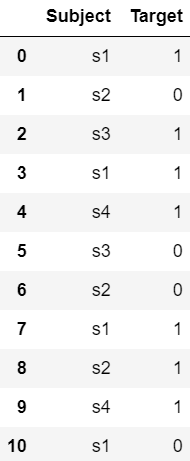
为了各种编码技术,我们将使用以下数据集:
Python3
# importing libraries
import pandas as pd
# creating dataset
data = {'Subject': ['s1', 's2', 's3', 's1', 's4',
's3', 's2', 's1', 's2', 's4', 's1'],
'Target': [1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0]}
# convert to dataframe
df = pd.DataFrame(data)
# display the dataset
dfPython3
# importing libraries
from sunbird.categorical_encoding import frequency_encoding
import pandas as pd
# creating dataset
data = {'Subject': ['s1', 's2', 's3', 's1', 's4',
's3', 's2', 's1', 's2', 's4', 's1'],
'Target': [1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0]}
df = pd.DataFrame(data)
# applying frequency encoding
frequency_encoding(df, 'Subject')
# display the dataset
dfPython3
# importing libraries
from sunbird.categorical_encoding import target_guided_encoding
import pandas as pd
# creating dataset
data = {'Subject': ['s1', 's2', 's3', 's1', 's4',
's3', 's2', 's1', 's2', 's4', 's1'],
'Target': [1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0]}
df = pd.DataFrame(data)
# applying target guided encoding
target_guided_encoding(df, 'Subject', 'Target')
# display the dataset
dfPython3
# importing libraries
from sunbird.categorical_encoding import probability_ratio_encoding
import pandas as pd
# creating dataset
data = {'Subject': ['s1', 's2', 's3', 's1', 's4',
's3', 's2', 's1', 's2', 's4', 's1'],
'Target': [1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0]}
df = pd.DataFrame(data)
# applying probability ratio encoding
probability_ratio_encoding(df, 'Subject', 'Target')
# display the dataset
dfPython3
# importing libraries
from sunbird.categorical_encoding import mean_encoding
import pandas as pd
# creating dataset
data = {'Subject': ['s1', 's2', 's3', 's1', 's4', 's3',
's2', 's1', 's2', 's4', 's1'],
'Target': [1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0]}
df = pd.DataFrame(data)
# applying mean encoding
mean_encoding(df, 'Subject', 'Target')
# display the dataset
dfPython3
# importing libraries
import pandas as pd
from sunbird.categorical_encoding import one_hot
# creating dataset
data = {'Water': ['A', 'B', 'C', 'D', 'E', 'F', 'G'],
'Temperature': ['Hot', 'Cold', 'Warm', 'Cold',
'Hot', 'Hot', 'Warm']}
df = pd.DataFrame(data)
# applying one hot encoding
one_hot(df, 'Temperature')
# display the dataset
dfPython3
# importing libraries
import pandas as pd
from sunbird.categorical_encoding import one_hot
# creating dataset
data = {'Subject': ['s1', 's2', 's3', 's1', 's4', 's3',
's2', 's1', 's2', 's4', 's1'],
'Target': [1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0]}
df = pd.DataFrame(data)
# applying one hot encoding
one_hot(df, 'Subject')
# display the dataset
dfPython3
# importing libraries
import pandas as pd
from sunbird.categorical_encoding import kdd_cup
# creating dataset
data = {'Water': ['A', 'B', 'C', 'D', 'E', 'F', 'G'],
'Temperature': ['Hot', 'Cold', 'Warm', 'Cold',
'Hot', 'Hot', 'Warm']}
df = pd.DataFrame(data)
# applying one hot encoding
kdd_cup(df, 'Temperature', k=10)
# display the dataset
dfPython3
# importing libraries
import pandas as pd
from sunbird.categorical_encoding import kdd_cup
# creating dataset
data = {'Subject': ['s1', 's2', 's3', 's1', 's4', 's3',
's2', 's1', 's2', 's4', 's1'],
'Target': [1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0]}
df = pd.DataFrame(data)
# applying one hot encoding
kdd_cup(df, 'Subject', k=10)
# display the dataset
df输出:
分类编码中可用的各种编码算法有:
1) 频率编码:
频率编码使用数据中类别的频率。在这种方法中,我们用它们的频率对类别进行编码。
如果我们以印度频率为 40 的国家/地区为例,那么我们将其编码为 40。
这种方法的缺点是假设两个类别具有相同的频率数,那么这两个类别的编码值是相同的。
句法:
from sunbird.categorical_encoding import frequency_encoding
frequency_encoding(dataframe, 'categorical-column')例子:
蟒蛇3
# importing libraries
from sunbird.categorical_encoding import frequency_encoding
import pandas as pd
# creating dataset
data = {'Subject': ['s1', 's2', 's3', 's1', 's4',
's3', 's2', 's1', 's2', 's4', 's1'],
'Target': [1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0]}
df = pd.DataFrame(data)
# applying frequency encoding
frequency_encoding(df, 'Subject')
# display the dataset
df
输出:

2)目标引导编码:
在这种编码中,特征被替换为给定特定分类值的目标后验概率和目标在所有训练数据上的先验概率的混合。此方法根据标签对标签进行排序。
句法:
from sunbird.categorical_encoding import target_guided_encoding
target_guided_encoding(dataframe, 'categorical-column', 'target-column')例子:
蟒蛇3
# importing libraries
from sunbird.categorical_encoding import target_guided_encoding
import pandas as pd
# creating dataset
data = {'Subject': ['s1', 's2', 's3', 's1', 's4',
's3', 's2', 's1', 's2', 's4', 's1'],
'Target': [1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0]}
df = pd.DataFrame(data)
# applying target guided encoding
target_guided_encoding(df, 'Subject', 'Target')
# display the dataset
df
输出:

3) 概率比编码:
概率比编码基于自变量相对于因变量的预测能力,关于使用好坏概率的比率。
句法:
from sunbird.categorical_encoding import probability_ratio_encoding
probability_ratio_encoding(dataframe, 'categorical-column', 'target-column')例子:
蟒蛇3
# importing libraries
from sunbird.categorical_encoding import probability_ratio_encoding
import pandas as pd
# creating dataset
data = {'Subject': ['s1', 's2', 's3', 's1', 's4',
's3', 's2', 's1', 's2', 's4', 's1'],
'Target': [1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0]}
df = pd.DataFrame(data)
# applying probability ratio encoding
probability_ratio_encoding(df, 'Subject', 'Target')
# display the dataset
df
输出:

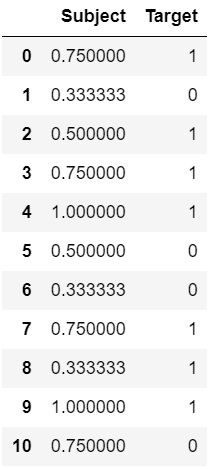
4) 均值编码:
这种类型的编码捕获标签内的信息,因此呈现更多预测特征,它在变量和目标之间创建单调关系。但是,它可能会导致模型过度拟合。
句法:
from sunbird.categorical_encoding import mean_encoding
mean_encoding(dataframe, 'categorical-column', 'target-column')例子:
蟒蛇3
# importing libraries
from sunbird.categorical_encoding import mean_encoding
import pandas as pd
# creating dataset
data = {'Subject': ['s1', 's2', 's3', 's1', 's4', 's3',
's2', 's1', 's2', 's4', 's1'],
'Target': [1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0]}
df = pd.DataFrame(data)
# applying mean encoding
mean_encoding(df, 'Subject', 'Target')
# display the dataset
df
输出:
5) 一次热编码:
在这种编码方法中,我们根据该类别的存在与否将值编码为 0 或 1。特征或虚拟变量的数量取决于编码特征中存在的类别数量。
例如,水的温度可以分为暖、热、冷三类,因此生成的虚拟变量或特征的数量将为 3。

句法:
from sunbird.categorical_encoding import one_hot
one_hot(dataframe, 'categorical-column')示例 1:
蟒蛇3
# importing libraries
import pandas as pd
from sunbird.categorical_encoding import one_hot
# creating dataset
data = {'Water': ['A', 'B', 'C', 'D', 'E', 'F', 'G'],
'Temperature': ['Hot', 'Cold', 'Warm', 'Cold',
'Hot', 'Hot', 'Warm']}
df = pd.DataFrame(data)
# applying one hot encoding
one_hot(df, 'Temperature')
# display the dataset
df
输出:

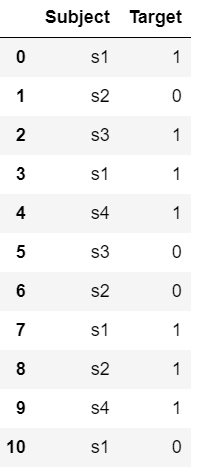
示例 2:
蟒蛇3
# importing libraries
import pandas as pd
from sunbird.categorical_encoding import one_hot
# creating dataset
data = {'Subject': ['s1', 's2', 's3', 's1', 's4', 's3',
's2', 's1', 's2', 's4', 's1'],
'Target': [1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0]}
df = pd.DataFrame(data)
# applying one hot encoding
one_hot(df, 'Subject')
# display the dataset
df
输出:
6) 一种多类别的热编码:
当我们在特定分类特征中有更多类别时,在对该特征应用单热编码后,由此生成的列数也会更多。在这种情况下,我们在这种编码方法中使用具有多类别的单热编码,我们采用更频繁的类别。
这里 k 定义了你想要采用的频繁特征的数量。 k 的默认值为 10。
句法:
from sunbird.categorical_encoding import kdd_cup
kdd_cup(dataframe, 'categorical-column', k=10)示例 1:
蟒蛇3
# importing libraries
import pandas as pd
from sunbird.categorical_encoding import kdd_cup
# creating dataset
data = {'Water': ['A', 'B', 'C', 'D', 'E', 'F', 'G'],
'Temperature': ['Hot', 'Cold', 'Warm', 'Cold',
'Hot', 'Hot', 'Warm']}
df = pd.DataFrame(data)
# applying one hot encoding
kdd_cup(df, 'Temperature', k=10)
# display the dataset
df
输出:

示例 2:
蟒蛇3
# importing libraries
import pandas as pd
from sunbird.categorical_encoding import kdd_cup
# creating dataset
data = {'Subject': ['s1', 's2', 's3', 's1', 's4', 's3',
's2', 's1', 's2', 's4', 's1'],
'Target': [1, 0, 1, 1, 1, 0, 0, 1, 1, 1, 0]}
df = pd.DataFrame(data)
# applying one hot encoding
kdd_cup(df, 'Subject', k=10)
# display the dataset
df
输出:
