通过 Seaborn Plots 和 Matplotlib 可视化 ML 数据集
处理数据有时会有点无聊。将原始数据转换为可理解的格式是整个过程中最重要的部分之一,那么为什么要坚持使用数字,当我们可以将我们的数据可视化为令人兴奋的图表时,这些图表可以在Python中获取。本文将重点探索可以使您的预处理之旅变得有趣的情节。
Seaborn和Matplotlib为我们提供了许多诱人的图表,通过这些图表,人们可以轻松分析薄弱环节,深入了解数据,并最终通过不同的算法训练数据并获得最高精度的数据。
让我们看一下我们的数据集:数据集(36 行)包含 6 个特征和 2 个类(Survived = 1,Not Survived = 0)我们将在此基础上绘制某些图表。数据集的链接 - 单击此处获取完整的数据集
1. KDE PLOT:好的所以在浏览了数据集之后,我们可以有一个问题。哪个年龄组的人数最多?为了回答这个问题,我们需要我们的 KDE 图出现的视觉效果,它只是一个密度图。所以让我们从导入所需的库开始,并使用它的函数来绘制图形。
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# KDE plot
sns.kdeplot(dataset["Age"], color = "green",
shade = True)
plt.show()
plt.figure()Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Checking the count of Age Group 20-40
dataset.Age[(dataset["Age"] >= 20) & (dataset["Age"] <= 40)].count()Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
sns.kdeplot(dataset["Age"], dataset["Fare"], shade = True)
plt.show()
plt.figure()Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Checking The Variation Between Fare And Age
dataset.Age[((dataset["Fare"] >= 100) &
(dataset["Fare"]<=200)) &
((dataset["Age"]>=20) &
dataset["Age"]<=40)].count()Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Histogram+Density Plot
sns.distplot(dataset["Age"], color = "green")
plt.show()
plt.figure()Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Adding Two Plots In One
sns.kdeplot(dataset[dataset.Gender == 'Female']['Age'],
color = "blue")
sns.kdeplot(dataset[dataset.Gender == 'Male']['Age'],
color = "orange", shade = True)
plt.show()
plt.figure()Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# showing that there are more Male's Between Age Of 12-40
dataset.Gender[((dataset["Age"] >= 12) &
(dataset["Age"] <= 40)) &
(dataset["Gender"] == "Male")].count()
dataset.Gender[((dataset["Age"] >= 12) &
(dataset["Age"] <= 40)) &
(dataset["Gender"] == "Female")].count()Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
sns.violinplot(x = 'Survived', y = 'Age', data = dataset,
palette = {0 : "yellow", 1 : "orange"});
plt.show()
plt.figure()Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
sns.violinplot(x = "Gender", y = "Age", hue = "Survived",
data = dataset,
palette = {0 : "yellow", 1 : "orange"})
plt.show()
plt.figure()Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Plot a nested barplot to show survival for Siblings and Gender
g = sns.catplot(x = "Siblings", y = "Survived", hue = "Gender", data = dataset,
height = 6, kind = "bar", palette = "muted")
g.despine(lef t= True)
g.set_ylabels("Survival Probability")
plt.show()Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Based On Fare There Are 3 Types Of Tickets
sns.catplot(x = "PassType", y = "Fare", data = dataset)
plt.show()
plt.figure()Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
sns.catplot(x="PassType", y="Fare", hue="Survived",kind="swarm",data=dataset)
plt.show()
plt.figure()输出 :
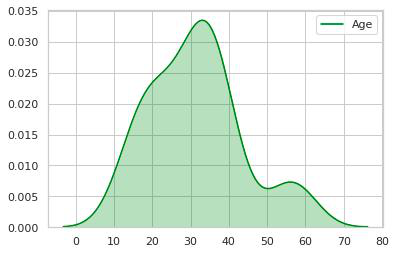
2.现在我们清楚地了解了 Count Of People vs Age-Group 的分布情况,在这里我们可以看到 20-40 岁的年龄组有最大的人数,所以让我们检查一下。
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Checking the count of Age Group 20-40
dataset.Age[(dataset["Age"] >= 20) & (dataset["Age"] <= 40)].count()
输出 :
263.深入研究视觉效果,了解 Fair Vs Age 的变化,它们之间的关系是什么,让我们用另一种 kdeplot 来看看现在会有双变量密度,我们只需添加 Y 变量(公平的)。
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
sns.kdeplot(dataset["Age"], dataset["Fare"], shade = True)
plt.show()
plt.figure()
输出 :

4.稍微研究一下这张图,我们发现颜色的强度在 20-30 岁之间最大,而恰恰是在 100-200 之间,让我们检查一下
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Checking The Variation Between Fare And Age
dataset.Age[((dataset["Fare"] >= 100) &
(dataset["Fare"]<=200)) &
((dataset["Age"]>=20) &
dataset["Age"]<=40)].count()
输出 :
165.我们也可以使用 seaborn 的 distplot() 模块在 kdeplot 中添加直方图:
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Histogram+Density Plot
sns.distplot(dataset["Age"], color = "green")
plt.show()
plt.figure()
输出 :
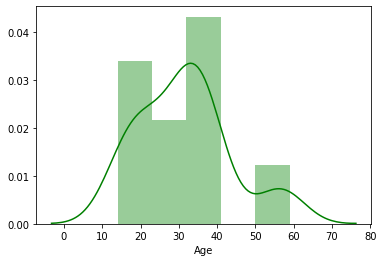
6.嗯。如果想知道男性与女性的比例,我们可以在 KDE 本身中绘制相同的图:
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Adding Two Plots In One
sns.kdeplot(dataset[dataset.Gender == 'Female']['Age'],
color = "blue")
sns.kdeplot(dataset[dataset.Gender == 'Male']['Age'],
color = "orange", shade = True)
plt.show()
plt.figure()
输出 :
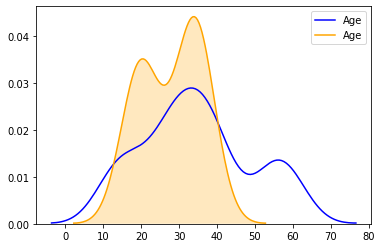
7.从图中我们可以看出,从 12 岁到 40 岁之后计数有所增加,让我们检查一下
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# showing that there are more Male's Between Age Of 12-40
dataset.Gender[((dataset["Age"] >= 12) &
(dataset["Age"] <= 40)) &
(dataset["Gender"] == "Male")].count()
dataset.Gender[((dataset["Age"] >= 12) &
(dataset["Age"] <= 40)) &
(dataset["Gender"] == "Female")].count()
输出 :
17
158. VIOLIN PLOT:我们已经讨论了很多特征,现在让我们谈谈生存率对特征的依赖。为此,我们将使用经典的小提琴情节,顾名思义,它描绘了与小提琴音乐波浪相同的视觉效果。基本上,小提琴图用于可视化数据的分布及其概率密度。
生存率和年龄有什么关系?让我们直观地分析一下:
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
sns.violinplot(x = 'Survived', y = 'Age', data = dataset,
palette = {0 : "yellow", 1 : "orange"});
plt.show()
plt.figure()
输出 :
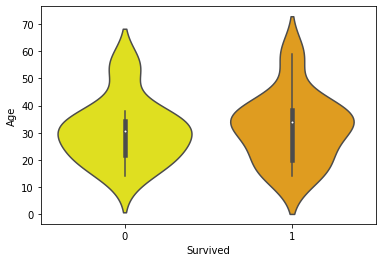
解释:我们在图中看到的白点是中位数,中间的粗黑条代表四分位数
范围。从它延伸出来的细黑线表示数据中的上(最大)和下(最小)相邻值。
快速浏览一下,我们发现年龄[10-20] 之间的存活率要高一点(Survived==1)。
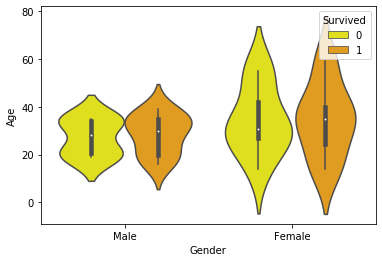
9.让我们为生存率与性别和年龄再绘制一个图
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
sns.violinplot(x = "Gender", y = "Age", hue = "Survived",
data = dataset,
palette = {0 : "yellow", 1 : "orange"})
plt.show()
plt.figure()
这里还有一个属性是 hue,它指的是 Survived 的二进制值。
输出 :
10. CATPLOT:简单来说,catplot 显示一个、两个或三个分类变量的类别的频率(或可选的分数或百分比)。
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Plot a nested barplot to show survival for Siblings and Gender
g = sns.catplot(x = "Siblings", y = "Survived", hue = "Gender", data = dataset,
height = 6, kind = "bar", palette = "muted")
g.despine(lef t= True)
g.set_ylabels("Survival Probability")
plt.show()
这里 sns.despine 是用来从 plot 中移除顶部和右侧的刺,我们来看看。
输出 :
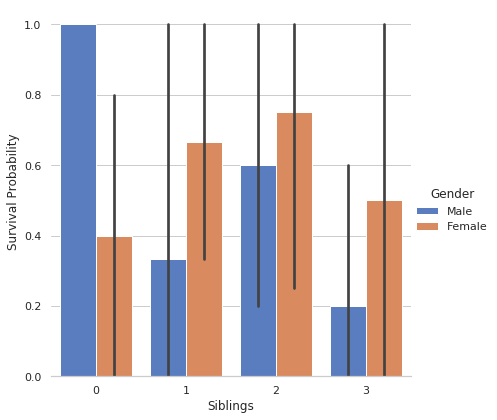
在这里,我们清楚地了解了兄弟姐妹数量的性别明智生存概率。
11 .现在,在数据集中我们看到Ticket里面有3个category,是基于Fare的,我们来找一下(参考这个图我为Ticket添加了一个Category列)
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
# Based On Fare There Are 3 Types Of Tickets
sns.catplot(x = "PassType", y = "Fare", data = dataset)
plt.show()
plt.figure()
输出 :
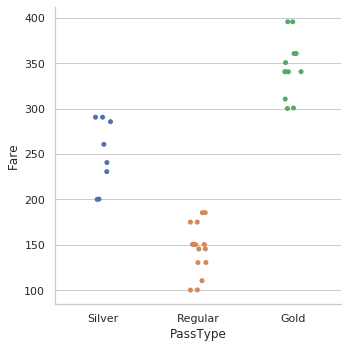
使用这个我们得出结论,应该为工单定义类别
12.与生存率的关系:
Python3
# importing the modules and dataset
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
dataset = pd.read_csv("Survival.csv")
sns.catplot(x="PassType", y="Fare", hue="Survived",kind="swarm",data=dataset)
plt.show()
plt.figure()
输出 :
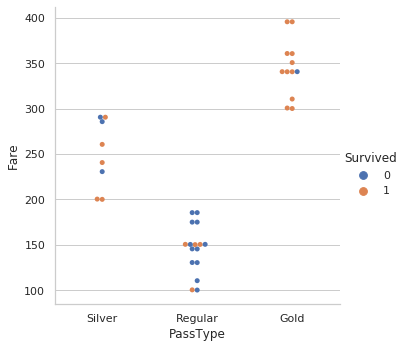
由此,我们清楚地了解了门票类别的生存率与票价。