从多索引 Pandas Dataframe 中删除特定行
在本文中,我们将学习如何从多索引 DataFrame 中删除特定行。
首先,让我们创建多索引 DataFrame。步骤如下:
Python3
import numpy as np
import pandas as pd
mldx_arrays = [np.array(['lion', 'lion', 'lion', 'bison',
'bison', 'bison', 'hawk', 'hawk',
'hawk']),
np.array(['height', 'weight', 'speed',
'height', 'weight', 'speed',
'height', 'weight', 'speed'])]
# creating a multi-index dataframe
# with random data
multiindex_df = pd.DataFrame(
np.random.randn(9, 4), index=mldx_arrays,
columns=['Type A', 'Type B', 'Type C', 'Type D'])
multiindex_df.index.names = ['level 0', 'level 1']
multiindex_dfPython3
multiindex_df.drop('lion', level=0, axis=0, inplace=True)
multiindex_dfPython3
multiindex_df.drop('weight', level=1, axis=0, inplace=True)
multiindex_dfPython3
multiindex_df.drop(('bison', 'weight'), axis=0, inplace=True)
multiindex_dfPython3
multiindex_df.drop(['bison', 'hawk'], axis=0, inplace=True)
multiindex_df输出:
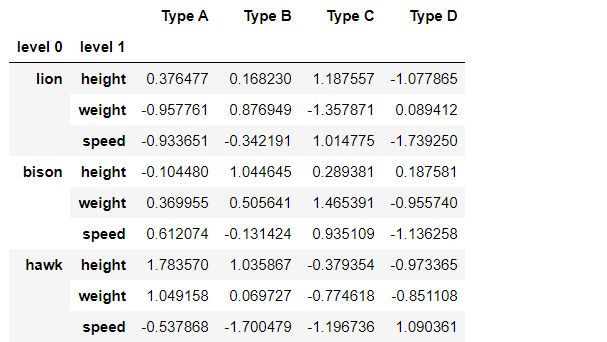
现在,我们必须从多索引数据框中删除一些行。所以,我们使用的是 pandas 模块提供的 drop() 方法。此函数在 Pandas 数据框中删除行或列。
Syntax: df.drop(‘labels’, level=0, axis=0, inplace=True)
Parameters:
- labels: the parameter mentioned in quotes is the index or column labels to drop
- axis : parameter to drop labels from the rows(when axis=0 or ‘index’) / columns (when axis=1 or ‘columns’).
- level: parameter indicates the level number like 0,1 etc to help identify and manipulate a particular level of data in a multi-index dataframe. For example, there are two levels in the given examples i.e level 1 and level 2.
- inplace: parameter to do operation inplace and return nothing if its value is given True. Here in all the examples, the value of inplace is given True so that it does the operation and then return nothing.
示例 1:删除级别 0 中包含“lion”的行。
这里的“lion”是我们要删除的标签名称,
- level=0,axis=0 表示行将作为删除目标,
- inplace=True 在 df.drop()函数,以便它执行任务并且不返回任何内容。
蟒蛇3
multiindex_df.drop('lion', level=0, axis=0, inplace=True)
multiindex_df
输出:
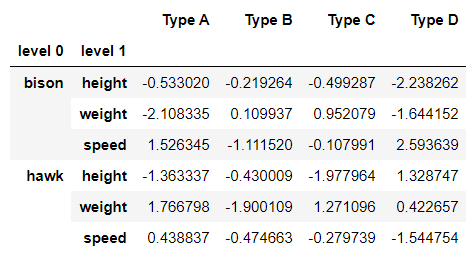
示例 2:删除级别 1 中包含“权重”的行。
这里的“权重”是我们想要从级别 0 中的每一行在级别 1 中删除的标签名称,
- level=1,axis=0 表示行将作为删除目标,
- inplace=True 在 df.drop()函数,以便它执行任务并且不返回任何内容。
蟒蛇3
multiindex_df.drop('weight', level=1, axis=0, inplace=True)
multiindex_df
输出:
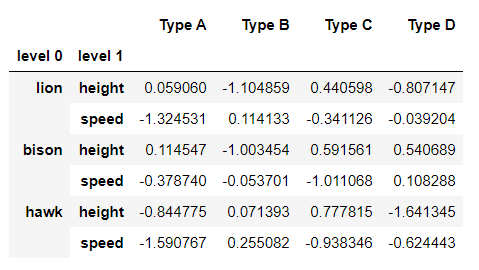
示例 3:将级别 1 中标签为“重量”的单行删除到级别 0 中的“野牛”内。
这里的 ('bison', 'weight') 是我们想要分别从级别 0 和级别 1 删除的标签名称。它只是意味着只有级别 0 中标签 'bison' 的行,级别 1 中的标签 'weight' 将被删除。无需提及级别,因为它涉及两个级别,因此只有引号内的标签名称才能正常工作,
- axis=0 因为它描述了行将作为删除的目标
- inplace=True 在 df.drop()函数,以便它执行任务并且不返回任何内容。
蟒蛇3
multiindex_df.drop(('bison', 'weight'), axis=0, inplace=True)
multiindex_df
输出:
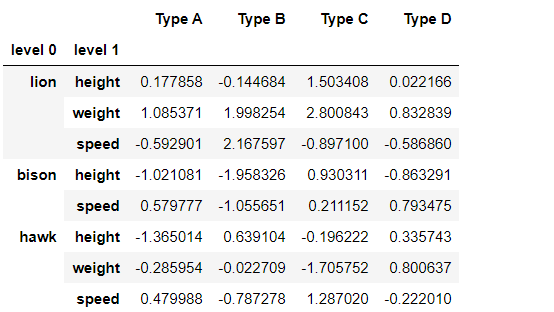
示例 4:从级别 0 删除两行。
这里 ('bison', 'hawk') 是我们想要从第 0 级删除的标签名称,其中包含来自第 1 级的多行。因此删除第 0 级的行将导致删除第 1 级的相应行.
- axis=0 因为它描述了行将作为删除的目标,
- inplace=True 在 df.drop()函数,以便它执行任务并且不返回任何内容。
蟒蛇3
multiindex_df.drop(['bison', 'hawk'], axis=0, inplace=True)
multiindex_df
输出 4:
