使用 Beautiful Soup 抓取亚马逊产品信息
网页抓取是一种数据提取方法,用于专门从网站收集数据。它广泛用于数据挖掘或从大型网站收集有价值的见解。网页抓取对于个人使用也很方便。 Python包含一个很棒的库,叫做BeautifulSoup 允许网页抓取。我们将使用它 抓取产品信息并将详细信息保存在 CSV 文件中。
在本文中,需要以下是先决条件。
url.txt: A text file with few urls of amazon product pages to scrape
Element Id: We need Id’s of objects we wish to web scrape, Will cover it soon…
在这里,我们的文本文件看起来像。

需要的模块和安装:
BeautifulSoup:我们的主要模块包含一个通过 HTTP 访问网页的方法。
pip install bs4lxml:用Python语言处理网页的助手库。
pip install lxml请求:使发送 HTTP 请求的过程完美无缺。函数的输出
pip install requests方法:
- 首先,我们将导入所需的库。
- 然后我们将获取存储在文本文件中的 URL。
- 我们将 URL 提供给我们的 soup 对象,然后从给定的 URL 中提取相关信息
根据我们提供的元素 ID 并将其保存到我们的 CSV 文件中。
让我们看一下代码,我们将看到每个重要步骤发生了什么。
第 1 步:初始化我们的程序。
我们导入我们的 beautifulsoup 和请求,创建/打开一个 CSV 文件来保存我们收集的数据。我们声明了 Header 并添加了一个用户代理。这确保了我们要抓取的目标网站不会将来自我们程序的流量视为垃圾邮件,并最终被它们阻止。这里有很多用户代理可用。
Python3
from bs4 import BeautifulSoup
import requests
File = open("out.csv", "a")
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64)
AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
webpage = requests.get(URL, headers=HEADERS)
soup = BeautifulSoup(webpage.content, "lxml")Python3
try:
title = soup.find("span",
attrs={"id": 'productTitle'})
title_value = title.string
title_string = title_value
.strip().replace(',', '')
except AttributeError:
title_string = "NA"
print("product Title = ", title_string)Python3
File.write(f"{title_string},")Python3
File.write(f"{available},\n")
# closing the file
File.close()Python3
if __name__ == '__main__':
# opening our url file to access URLs
file = open("url.txt", "r")
# iterating over the urls
for links in file.readlines():
main(links)Python
# importing libraries
from bs4 import BeautifulSoup
import requests
def main(URL):
# opening our output file in append mode
File = open("out.csv", "a")
# specifying user agent, You can use other user agents
# available on the internet
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64)
AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
# Making the HTTP Request
webpage = requests.get(URL, headers=HEADERS)
# Creating the Soup Object containing all data
soup = BeautifulSoup(webpage.content, "lxml")
# retrieving product title
try:
# Outer Tag Object
title = soup.find("span",
attrs={"id": 'productTitle'})
# Inner NavigableString Object
title_value = title.string
# Title as a string value
title_string = title_value.strip().replace(',', '')
except AttributeError:
title_string = "NA"
print("product Title = ", title_string)
# saving the title in the file
File.write(f"{title_string},")
# retrieving price
try:
price = soup.find(
"span", attrs={'id': 'priceblock_ourprice'})
.string.strip().replace(',', '')
# we are omitting unnecessary spaces
# and commas form our string
except AttributeError:
price = "NA"
print("Products price = ", price)
# saving
File.write(f"{price},")
# retrieving product rating
try:
rating = soup.find("i", attrs={
'class': 'a-icon a-icon-star a-star-4-5'})
.string.strip().replace(',', '')
except AttributeError:
try:
rating = soup.find(
"span", attrs={'class': 'a-icon-alt'})
.string.strip().replace(',', '')
except:
rating = "NA"
print("Overall rating = ", rating)
File.write(f"{rating},")
try:
review_count = soup.find(
"span", attrs={'id': 'acrCustomerReviewText'})
.string.strip().replace(',', '')
except AttributeError:
review_count = "NA"
print("Total reviews = ", review_count)
File.write(f"{review_count},")
# print availablility status
try:
available = soup.find("div", attrs={'id': 'availability'})
available = available.find("span")
.string.strip().replace(',', '')
except AttributeError:
available = "NA"
print("Availability = ", available)
# saving the availability and closing the line
File.write(f"{available},\n")
# closing the file
File.close()
if __name__ == '__main__':
# opening our url file to access URLs
file = open("url.txt", "r")
# iterating over the urls
for links in file.readlines():
main(links)第 2 步:检索元素 ID。
我们通过查看呈现的网页来识别元素,但是对于我们的脚本却不能这样说。为了查明我们的目标元素,我们将获取它的元素 id 并将其提供给脚本。
获取元素的 id 非常简单。假设我需要产品名称的元素 id,我所要做的
- 获取 URL 并检查文本
- 在控制台中,我们获取 id= 旁边的文本
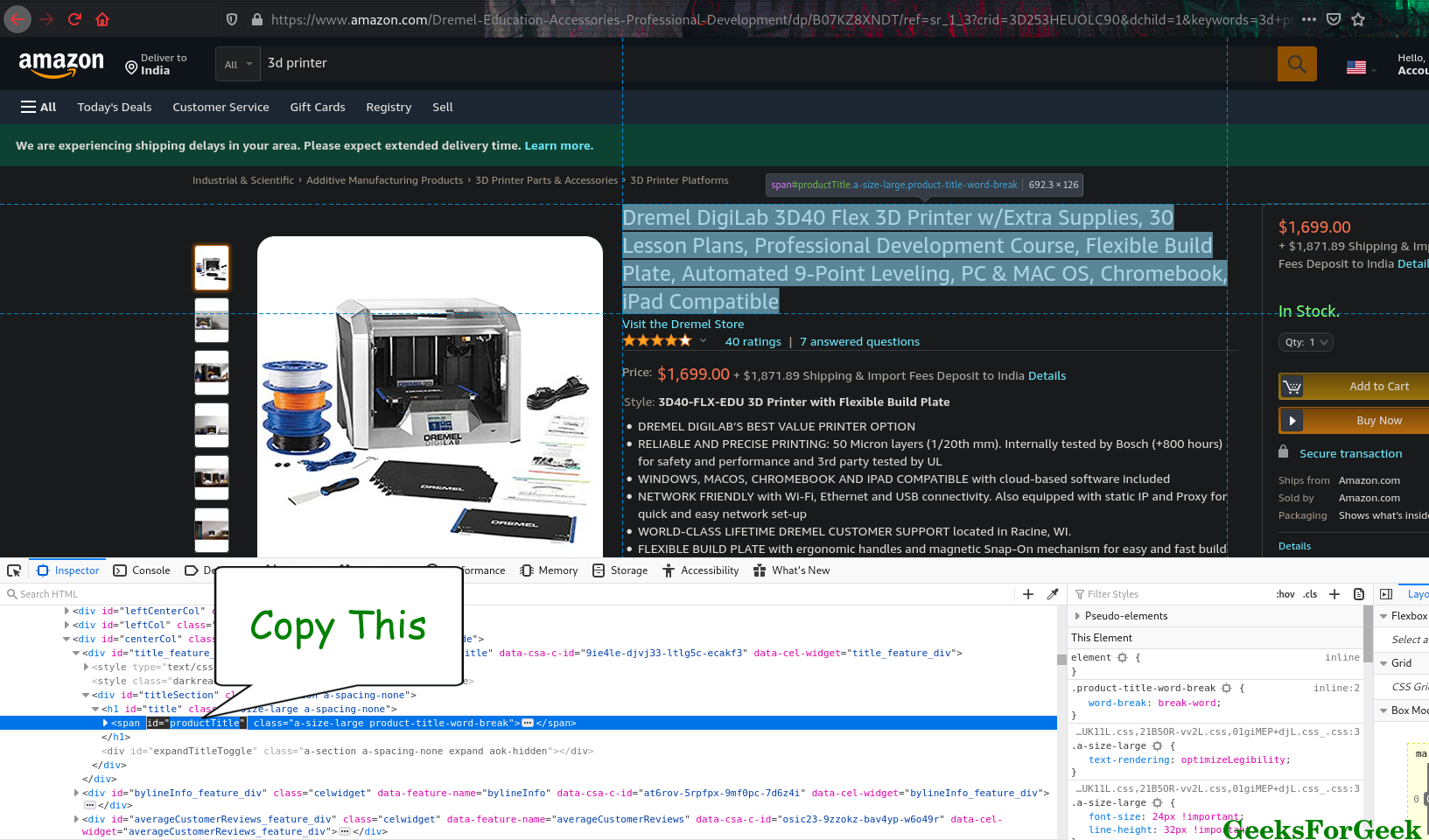
复制元素id
我们将它提供给 soup.find 并将函数的输出转换为字符串。我们从字符串中删除逗号,这样它就不会干扰 CSV try-except 书写格式。
蟒蛇3
try:
title = soup.find("span",
attrs={"id": 'productTitle'})
title_value = title.string
title_string = title_value
.strip().replace(',', '')
except AttributeError:
title_string = "NA"
print("product Title = ", title_string)
第 3 步:将当前信息保存到文本文件
我们使用我们的文件对象并写入我们刚刚捕获的字符串,并在字符串以 CSV 格式解释时以逗号“,”结尾以分隔其列。
蟒蛇3
File.write(f"{title_string},")
使用我们希望从网络捕获的所有属性执行上述 2 个步骤
如商品价格、可用性等。
第 4 步:关闭文件。
蟒蛇3
File.write(f"{available},\n")
# closing the file
File.close()
在写最后一点信息时,请注意我们如何添加“\n”来更改行。不这样做会在很长的一行中为我们提供所有必需的信息。我们使用 File.close() 关闭文件。这是必要的,如果我们不这样做,下次打开文件时可能会出错。
第五步:调用我们刚刚创建的函数。
蟒蛇3
if __name__ == '__main__':
# opening our url file to access URLs
file = open("url.txt", "r")
# iterating over the urls
for links in file.readlines():
main(links)
我们以阅读模式打开 url.txt 并遍历它的每一行,直到我们到达最后一行。在每一行调用 main函数。
这是我们整个代码的样子:
Python
# importing libraries
from bs4 import BeautifulSoup
import requests
def main(URL):
# opening our output file in append mode
File = open("out.csv", "a")
# specifying user agent, You can use other user agents
# available on the internet
HEADERS = ({'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64)
AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'})
# Making the HTTP Request
webpage = requests.get(URL, headers=HEADERS)
# Creating the Soup Object containing all data
soup = BeautifulSoup(webpage.content, "lxml")
# retrieving product title
try:
# Outer Tag Object
title = soup.find("span",
attrs={"id": 'productTitle'})
# Inner NavigableString Object
title_value = title.string
# Title as a string value
title_string = title_value.strip().replace(',', '')
except AttributeError:
title_string = "NA"
print("product Title = ", title_string)
# saving the title in the file
File.write(f"{title_string},")
# retrieving price
try:
price = soup.find(
"span", attrs={'id': 'priceblock_ourprice'})
.string.strip().replace(',', '')
# we are omitting unnecessary spaces
# and commas form our string
except AttributeError:
price = "NA"
print("Products price = ", price)
# saving
File.write(f"{price},")
# retrieving product rating
try:
rating = soup.find("i", attrs={
'class': 'a-icon a-icon-star a-star-4-5'})
.string.strip().replace(',', '')
except AttributeError:
try:
rating = soup.find(
"span", attrs={'class': 'a-icon-alt'})
.string.strip().replace(',', '')
except:
rating = "NA"
print("Overall rating = ", rating)
File.write(f"{rating},")
try:
review_count = soup.find(
"span", attrs={'id': 'acrCustomerReviewText'})
.string.strip().replace(',', '')
except AttributeError:
review_count = "NA"
print("Total reviews = ", review_count)
File.write(f"{review_count},")
# print availablility status
try:
available = soup.find("div", attrs={'id': 'availability'})
available = available.find("span")
.string.strip().replace(',', '')
except AttributeError:
available = "NA"
print("Availability = ", available)
# saving the availability and closing the line
File.write(f"{available},\n")
# closing the file
File.close()
if __name__ == '__main__':
# opening our url file to access URLs
file = open("url.txt", "r")
# iterating over the urls
for links in file.readlines():
main(links)
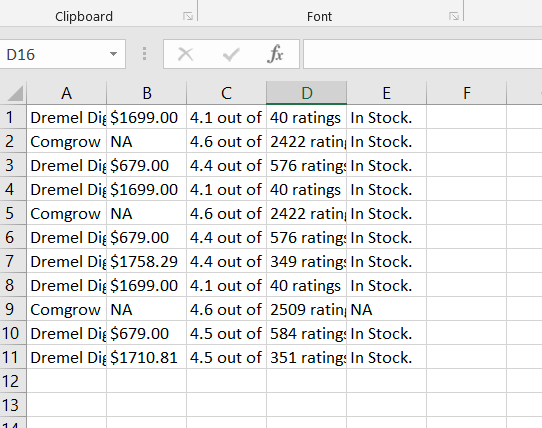
输出:
product Title = Dremel DigiLab 3D40 Flex 3D Printer w/Extra Supplies 30 Lesson Plans Professional Development Course Flexible Build Plate Automated 9-Point Leveling PC & MAC OS Chromebook iPad Compatible
Products price = $1699.00
Overall rating = 4.1 out of 5 stars
Total reviews = 40 ratings
Availability = In Stock.
product Title = Comgrow Creality Ender 3 Pro 3D Printer with Removable Build Surface Plate and UL Certified Power Supply 220x220x250mm
Products price = NA
Overall rating = 4.6 out of 5 stars
Total reviews = 2509 ratings
Availability = NA
product Title = Dremel Digilab 3D20 3D Printer Idea Builder for Brand New Hobbyists and Tinkerers
Products price = $679.00
Overall rating = 4.5 out of 5 stars
Total reviews = 584 ratings
Availability = In Stock.
product Title = Dremel DigiLab 3D45 Award Winning 3D Printer w/Filament PC & MAC OS Chromebook iPad Compatible Network-Friendly Built-in HD Camera Heated Build Plate Nylon ECO ABS PETG PLA Print Capability
Products price = $1710.81
Overall rating = 4.5 out of 5 stars
Total reviews = 351 ratings
Availability = In Stock.
这是我们的 out.csv 的样子。