Julia 中的决策树分类器
在 Julia 的统计中,分类是根据包含类别成员已知的观察(或实例)的训练数据集来识别新观察属于一组类别(子种群)中的哪一个的问题。
在机器学习的术语中,分类被认为是有监督学习的一个实例,即在可以使用正确识别的观察训练集的情况下进行学习。
我们拥有的一些分类技术是:
- 线性分类器:逻辑回归、朴素贝叶斯分类器
- 最近的邻居
- 支持向量机
- 决策树
- 提升树
- 随机森林
- 神经网络
决策树分类器
决策树是分类示例的简单表示。它是一种有监督的机器学习,其中数据根据某个参数连续拆分。
决策树通常用于运筹学和运营管理。如果在实践中必须在不完全知识的情况下在线进行决策,则决策树应与概率模型并行作为最佳选择模型或在线选择模型算法。决策树的另一个用途是作为计算条件概率的描述方法。
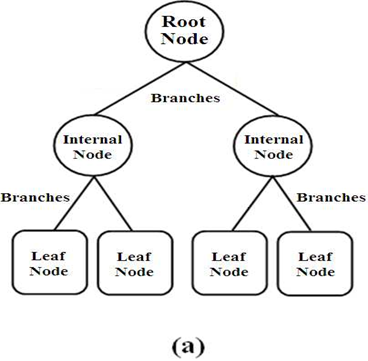
决策树主要有三个组成部分:
- 根节点:它代表整个总体或样本,并进一步分为两个或更多同质集。
- Edges/Branch:代表一个决策规则并连接到下一个节点。
- 叶节点:叶节点是树中没有附加节点的节点。他们不再进一步拆分数据
Julia 中决策树分类器的实现
决策树是一种类似结构的流程图
- 使用轴对齐的线性决策边界来划分或二等分数据
- 分而治之的方法
包和要求
- Pkg.add(“决策树”)
- Pkg.add(“数据帧”)
- Pkg.add(“Gadly”)
Julia
# using the packages
using DataFrames
using DecisionTree
# Loading the Data
# https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/
df = readtable("breastc.csv")Julia
# using gadly package
using Gadfly
plot(df, x = Xfeatures,
y = Ylabel, Geom.histogram,
color = :Class,
Guide.xlabel("Features"))输出:

朱莉娅
# using gadly package
using Gadfly
plot(df, x = Xfeatures,
y = Ylabel, Geom.histogram,
color = :Class,
Guide.xlabel("Features"))
输出:
