遍历 Pandas DataFrame 中的行和列
迭代是一个通用术语,用于一个接一个地获取某物的每一项。 Pandas DataFrame 由行和列组成,因此,为了迭代数据帧,我们必须像字典一样迭代数据帧。在字典中,我们以与在数据帧中迭代相同的方式迭代对象的键。

在本文中,我们使用“nba.csv”文件下载 CSV,请单击此处。
在 Pandas Dataframe 中,我们可以通过两种方式迭代元素:
- 遍历行
- 遍历列
遍历行:
为了迭代行,我们可以使用三个函数iteritems()、iterrows()、itertuples()。这三个函数将有助于对行进行迭代。
使用 iterrows() 对行进行迭代
为了迭代行,我们应用了 iterrows()函数,该函数返回每个索引值以及包含每行数据的序列。
代码#1:
Python3
# importing pandas as pd
import pandas as pd
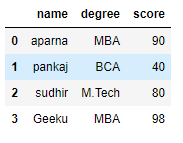
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe from a dictionary
df = pd.DataFrame(dict)
print(df)Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe from a dictionary
df = pd.DataFrame(dict)
# iterating over rows using iterrows() function
for i, j in df.iterrows():
print(i, j)
print()Python
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# for data visualization we filter first 3 datasets
data.head(3)Python
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
for i, j in data.iterrows():
print(i, j)
print()Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe from a dictionary
df = pd.DataFrame(dict)
print(df)Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe from a dictionary
df = pd.DataFrame(dict)
# using iteritems() function to retrieve rows
for key, value in df.iteritems():
print(key, value)
print()Python
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# for data visualization we filter first 3 datasets
data.head(3)Python
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
for key, value in data.iteritems():
print(key, value)
print()Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe from a dictionary
df = pd.DataFrame(dict)
print(df)Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
# using a itertuples()
for i in df.itertuples():
print(i)Python
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# for data visualization we filter first 3 datasets
data.head(3)Python
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
for i in data.itertuples():
print(i)Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe from a dictionary
df = pd.DataFrame(dict)
print(df)Python
# creating a list of dataframe columns
columns = list(df)
for i in columns:
# printing the third element of the column
print (df[i][2])Python
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# for data visualization we filter first 3 datasets
col = data.head(3)
colPython
# creating a list of dataframe columns
clmn = list(col)
for i in clmn:
# printing a third element of column
print(col[i][2])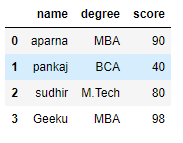
现在我们应用 iterrows()函数来获取行的每个元素。
Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe from a dictionary
df = pd.DataFrame(dict)
# iterating over rows using iterrows() function
for i, j in df.iterrows():
print(i, j)
print()
输出:

代码#2:
Python
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# for data visualization we filter first 3 datasets
data.head(3)

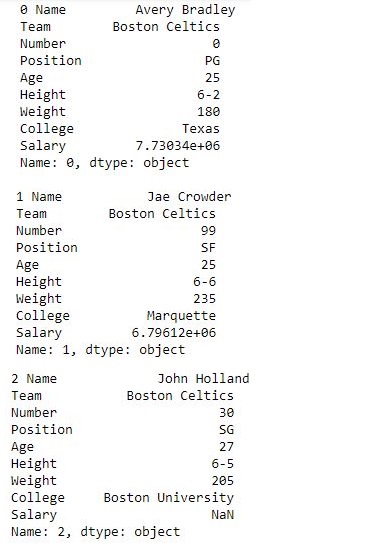
现在我们应用 iterrows 来获取数据框中行的每个元素
Python
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
for i, j in data.iterrows():
print(i, j)
print()
输出:
使用 iteritems() 对行进行迭代
为了迭代行,我们使用 iteritems()函数,该函数迭代每列作为键,以标签作为键的值对,以及作为系列对象的列值。
代码#1:
Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe from a dictionary
df = pd.DataFrame(dict)
print(df)
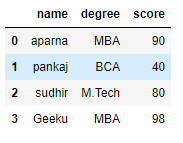
现在我们应用一个 iteritems()函数来检索一行数据帧。
Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe from a dictionary
df = pd.DataFrame(dict)
# using iteritems() function to retrieve rows
for key, value in df.iteritems():
print(key, value)
print()
输出:
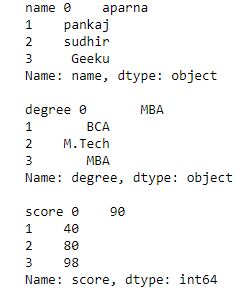
代码#2:
Python
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# for data visualization we filter first 3 datasets
data.head(3)
输出:

现在我们应用 iteritems() 以从数据框中检索行
Python
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
for key, value in data.iteritems():
print(key, value)
print()
输出:
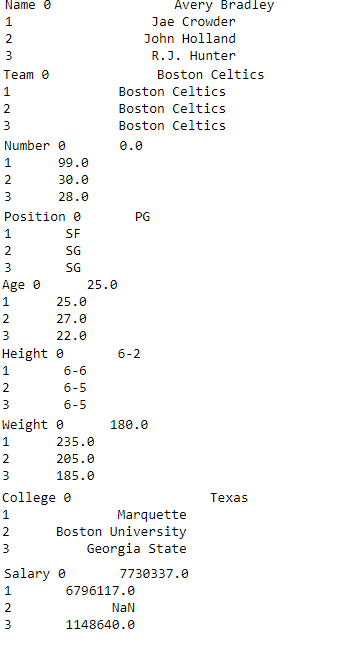
使用 itertuples() 对行进行迭代
为了遍历行,我们应用了一个函数itertuples(),这个函数为 DataFrame 中的每一行返回一个元组。元组的第一个元素将是行的相应索引值,而其余的值是行值。
代码#1:
Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe from a dictionary
df = pd.DataFrame(dict)
print(df)
现在我们应用一个 itertuples()函数来获取每一行的元组
Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
# using a itertuples()
for i in df.itertuples():
print(i)
输出:

代码#2:
Python
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# for data visualization we filter first 3 datasets
data.head(3)

现在我们应用一个 itertuples() 来获取每行的 atuple
Python
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
for i in data.itertuples():
print(i)
输出:

遍历 Columns :
为了遍历列,我们需要创建一个数据框列的列表,然后遍历该列表以提取数据框列。
代码#1:
Python3
# importing pandas as pd
import pandas as pd
# dictionary of lists
dict = {'name':["aparna", "pankaj", "sudhir", "Geeku"],
'degree': ["MBA", "BCA", "M.Tech", "MBA"],
'score':[90, 40, 80, 98]}
# creating a dataframe from a dictionary
df = pd.DataFrame(dict)
print(df)

现在我们遍历列为了遍历列,我们首先创建一个数据框列的列表,然后遍历列表。
Python
# creating a list of dataframe columns
columns = list(df)
for i in columns:
# printing the third element of the column
print (df[i][2])
输出:

代码#2:
Python
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# for data visualization we filter first 3 datasets
col = data.head(3)
col

现在我们遍历 CSV 文件中的列以遍历列,我们创建数据框列的列表并遍历列表
Python
# creating a list of dataframe columns
clmn = list(col)
for i in clmn:
# printing a third element of column
print(col[i][2])
输出:
