ML – 决策函数
决策函数是 sklearn 机器学习框架的分类器{ SVC, Logistic Regression } 类中存在的一种方法。该方法基本上返回一个 Numpy 数组,其中每个元素表示分类器对 x_test 的预测样本是位于超平面的右侧还是左侧,以及离超平面的距离。
它还告诉我们,分类器为 x_test 预测的每个值是正(大幅度正值)或负(大幅度负值)的置信度。
决策函数方法背后的数学:
让我们考虑线性可分二元类分类问题的 SVM:
成本函数:
![\left.\min _{\theta} C \sum_{i=1}^{m}\left[u^{(0)} \operatorname{cost}_{1}\left(\theta^{T} x^{(\theta)}\right)+\left(1-y^{(0)}\right) \operatorname{cost}_{0}\left(\theta^{T} x^{(0)}\right)\right]+\frac{1}{2} \sum_{i=1}^{n} \theta\right\}](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/ML_%E2%80%93_Decision_Function_0.png "由 QuickLaTeX.com 渲染")
这种线性可分二元类分类的假设:

优化算法最小化成本函数以找到假设的模型参数的最佳值,使得:

当我们将数据实例传递给决策函数方法时,实际上会发生什么?
这个数据样本被替换在这个假设中,它的模型参数已经通过最小化成本函数找到,并返回这个假设输出的值,如果实际输出为 1,则该值>1,如果实际输出为 0,则返回 <-1。返回value 确实代表了超平面的哪一侧以及给定的数据样本离它有多远。
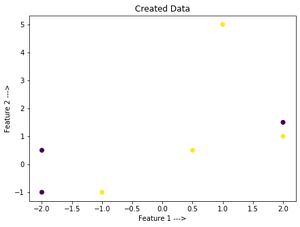
代码:创建我们自己的数据集并绘制输入。
# This code may not run on GFG IDE
# As required modules are not available.
# Create a simple data set
# Binary-Class Classification.
# Import Required Modules.
import matplotlib.pyplot as plt
import numpy as np
# Input Feature X.
x = np.array([[2, 1.5], [-2, -1], [-1, -1], [2, 1],
[1, 5], [0.5, 0.5], [-2, 0.5]])
# Input Feature Y.
y = np.array([0, 0, 1, 1, 1, 1, 0])
# Training set Featute x_train.
x_train = np.array([[2, 1.5], [-2, -1], [-1, -1], [2, 1]])
# Training set Target Variable y_train.
y_train = np.array([0, 0, 1, 1])
# Test set Featute x_test.
x_test = np.array([[1, 5], [0.5, 0.5], [-2, 0.5]])
# Test set Target Variable y_test
y_test = np.array([1, 1, 0])
# Plot the obtained data
plt.scatter(x[:, 0], x[:, 1], c = y)
plt.xlabel('Feature 1 --->')
plt.ylabel('Feature 2 --->')
plt.title('Created Data')
输出:
代码:训练我们的模型
# This code may not run on GFG IDE
# As required modules are not available.
# Import SVM Class from sklearn.
from sklearn.svm import SVC
clf = SVC()
# Train the model on the training set.
clf.fit(x_train, y_train)
# Predict on Test set
predict = clf.predict(x_test)
print('Predicted Values from Classifier:', predict)
print('Actual Output is:', y_test)
print('Accuracy of the model is:', clf.score(x_test, y_test))
输出:
Predicted Values from Classifier: [0 1 0]
Actual Output is: [1 1 0]
Accuracy of the model is: 0.6666666666666666
代码:决策函数法
# This code may not run on GFG IDE
# As required modules are not available.
# Using Decision Function Method Present in svc class
Decision_Function = clf.decision_function(x_test)
print('Output of Decision Function is:', Decision_Function)
print('Prediction for x_test from classifier is:', predict)
输出:
Output of Decision Function is: [-0.04274893 0.29143233 -0.13001369]
Prediction for x_test from classifier is: [0 1 0]
从上面的输出中,我们可以得出结论,决策函数输出表示分类器对 x_test 的预测样本是位于超平面的右侧还是左侧,以及离它有多远。它还告诉我们分类器为 x_test 预测的每个值是 Positive(大大小正值)或 Negative(大大小负值)的置信度有多高
代码:决策边界
# This code may not run on GFG IDE
# As required modules are not available.
# To Plot the Decision Boundary.
arr1 = np.arange(x[:, 0].min()-1, x[:, 0].max()+1, 0.01)
arr2 = np.arange(x[:, 1].min()-1, x[:, 1].max()+1, 0.01)
xx, yy = np.meshgrid(arr1, arr2)
input_array = np.array([xx.ravel(), yy.ravel()]).T
labels = clf.predict(input_array)
plt.figure(figsize =(10, 7))
plt.contourf(xx, yy, labels.reshape(xx.shape), alpha = 0.1)
plt.scatter(x_test[:, 0], x_test[:, 1], c = y_test.ravel(), alpha = 1)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Decision Boundary')
让我们可视化上面的结论。
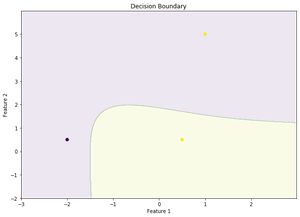
决策函数输出的优点是设置 DECISION THRESHOLD 并预测 x_test 的新输出,如果我们的项目分别是面向精度或面向召回的,我们可以获得所需的精度或召回值。