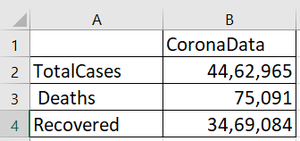
网络将冠状病毒数据抓取到 MS Excel 中
先决条件:使用 BeautifulSoap 进行网页抓取
冠状病毒病例在全球范围内迅速增加。本文将指导您如何通过网络抓取冠状病毒数据并导入 Ms-excel。
什么是网页抓取?
如果您曾经从网站复制和粘贴信息,那么您执行的函数与任何网络抓取工具相同,只是在微观的手动范围内。网页抓取,也称为在线数据挖掘,是一种从网站中提取或抓取数据的方法。收集这些知识,然后将其转换为用户更容易访问的媒体。它可以是电子表格或 API。
方法:
- 请求来自网页的响应。
- 在BeautifulsSoup()类方法和lxml模块的帮助下解析和提取。
- 使用pandas下载并导出数据到Excel。
数据来源:
我们需要一个网页来获取冠状病毒数据。所以我们将在这里使用 Worldometer 网站。 Worldometer 的网页将如下所示:
数据源
程序化实施
您将需要一些库,因此首先,您需要安装它们。
转到您的命令行并安装它们。
pip install requests
pip install lxml
pip install bs4现在让我们看看我们可以用这些库做什么。
以下是将冠状病毒数据从 Web 抓取到 Excel 的步骤:
步骤 1)使用请求库抓取页面。
Python3
# Import required module
import requests
# Make requests from webpage
result = requests.get('https://www.worldometers.info/coronavirus/country/india/')Python3
# Import required modules
import bs4
# Creating soap object
soup = bs4.BeautifulSoup(result.text,'lxml')Python3
# Searching div tags having maincounter-number class
cases = soup.find_all('div' ,class_= 'maincounter-number')Python3
# List to store number of cases
data = []
# Find the span and get data from it
for i in cases:
span = i.find('span')
data.append(span.string)
# Display number of cases
print(data)Python3
import pandas as pd
# Creating dataframe
df = pd.DataFrame({"CoronaData": data})
# Naming the columns
df.index = ['TotalCases', ' Deaths', 'Recovered']Python3
# Exporting data into Excel
df.to_csv('Corona_Data.csv')Python3
# Import required modules
import requests
import bs4
import pandas as pd
# Make requests from webpage
url = 'https://www.worldometers.info/coronavirus/country/india/'
result = requests.get(url)
# Creating soap object
soup = bs4.BeautifulSoup(result.text,'lxml')
# Searching div tags having maincounter-number class
cases = soup.find_all('div' ,class_= 'maincounter-number')
# List to store number of cases
data = []
# Find the span and get data from it
for i in cases:
span = i.find('span')
data.append(span.string)
# Display number of cases
print(data)
# Creating dataframe
df = pd.DataFrame({"CoronaData": data})
# Naming the columns
df.index = ['TotalCases', ' Deaths', 'Recovered']
# Exporting data into Excel
df.to_csv('Corona_Data.csv')我们下载的请求库去获取响应,为了从网页获取请求,我们使用 requests.get(website URL) 方法。如果请求成功,它将被存储为一个巨大的Python字符串。当我们运行 result.text 时,我们将能够获取完整的网页源代码。但是代码不会被结构化。
注意:如果您有阻止Python/Jupyter 的防火墙,这可能会失败。有时,如果第一次失败,您需要运行两次。
步骤 2)使用BeautifulSoap()方法从网站中提取数据。
bs4库已经有很多内置工具和方法可以从这种性质的字符串(基本上是一个 HTML 文件)中获取信息。它是一个Python库,用于从 HTML 和 XML 文件中提取数据。使用bs4模块的BeautifulSoup()方法,我们可以创建一个包含网页所有成分的汤对象。
蟒蛇3
# Import required modules
import bs4
# Creating soap object
soup = bs4.BeautifulSoup(result.text,'lxml')
导入bs4就是创建一个BeautifulSoup对象。我们将在这里传递两件事,result.text字符串和lxml作为字符串作为构造函数参数。 lxml遍历这个 HTML 文档,然后找出不同的 CSS类、 id 、HTML 元素和标签等。
提取数据,要找到元素,您需要右键单击并点击检查案例数。请参阅下面随附的快照。

检查网站
我们需要找到正确的类,即class_= 'maincounter-number'符合我们的目的。请参阅下面随附的快照。

找到合适的班级
BeautifulSoup对象已在我们的Python脚本中创建,网站的 HTML 数据已从页面中删除。接下来,我们需要从 HTML 代码中获取我们感兴趣的数据。
蟒蛇3
# Searching div tags having maincounter-number class
cases = soup.find_all('div' ,class_= 'maincounter-number')
输入屏幕截图(检查元素):

仍然有很多我们不想要的 HTML 代码。我们想要的数据条目包含在 HTML div 元素和class_= 'maincounter-number'中。我们可以利用这些知识进一步清理抓取的数据。
步骤 3)存储数据
我们需要以某种可以有效使用的形式保存抓取的数据。对于此项目,所有数据都将保存在Python列表中。
蟒蛇3
# List to store number of cases
data = []
# Find the span and get data from it
for i in cases:
span = i.find('span')
data.append(span.string)
# Display number of cases
print(data)
输入截图(检查元素):

输出:

我们将使用span从div获取数据。我们只需要案例的数量,而不是标签。所以我们将使用跨度。 字符串来获取这些数字,然后将它们存储在data[] 中。
现在我们有了案例数量,我们准备将数据导出到 Excel 文件中。
步骤 4)处理数据
我们的最后一步是将数据导出到 Ms-excel,为此我们将使用pandas模块。要加载pandas模块并开始使用它,请导入包。
蟒蛇3
import pandas as pd
# Creating dataframe
df = pd.DataFrame({"CoronaData": data})
# Naming the columns
df.index = ['TotalCases', ' Deaths', 'Recovered']
DataFrame是一种二维标记数据结构,具有标记轴(行和列)的潜在异构表格数据结构。
df = pd.DataFrame({“CoronaData”: data})用于创建DataFrame并为其命名并将其映射到我们之前创建的数据列表。
接下来,我们将使用df.index给出列名。
输出:

步骤 5)将数据导出到 Excel
我们准备好将数据导出到 Excel 中。我们将使用df.to_csv()方法来完成这个任务。
蟒蛇3
# Exporting data into Excel
df.to_csv('Corona_Data.csv')
输出:

以下是上述步骤的完整程序:
蟒蛇3
# Import required modules
import requests
import bs4
import pandas as pd
# Make requests from webpage
url = 'https://www.worldometers.info/coronavirus/country/india/'
result = requests.get(url)
# Creating soap object
soup = bs4.BeautifulSoup(result.text,'lxml')
# Searching div tags having maincounter-number class
cases = soup.find_all('div' ,class_= 'maincounter-number')
# List to store number of cases
data = []
# Find the span and get data from it
for i in cases:
span = i.find('span')
data.append(span.string)
# Display number of cases
print(data)
# Creating dataframe
df = pd.DataFrame({"CoronaData": data})
# Naming the columns
df.index = ['TotalCases', ' Deaths', 'Recovered']
# Exporting data into Excel
df.to_csv('Corona_Data.csv')
最后结果: