AI中的博弈论
博弈论基本上是数学的一个分支,用于在具有预定义规则(游戏或操纵)和结果的背景下,不同参与者(代理)之间的典型战略交互,所有这些参与者都同样理性。每个玩家或代理都是一个理性的实体,他们自私并试图使用特定策略来最大化获得的奖励。所有玩家都遵守一定的规则,以便获得预定义的季后赛——特定结果后的奖励。因此,一场比赛可以定义为一组球员、行动、策略和所有球员都在竞争的最终季后赛。
博弈论现在已经成为机器学习算法和许多日常生活情况的描述因素。
以 SVM(支持向量机)为例。根据博弈论,SVM 是 2 名玩家之间的博弈,其中一个玩家在提供最难分类的点后挑战另一个以找到最佳超平面。这场比赛的最终季后赛将是一个解决方案,将在竞争双方的战略能力之间进行权衡。
游戏类型:
目前,游戏的分类大概有5种。它们如下:
- 零和和非零和博弈:在非零和博弈中,有多个玩家,他们都可以选择因另一个玩家的任何举动而获得收益。然而,在零和游戏中,如果一名球员有所收获,其他球员必然会输掉关键的季后赛。
- 同时和顺序游戏:顺序游戏是更流行的游戏,每个玩家都知道另一个玩家的移动。同时游戏更难,因为在它们中,玩家参与并发游戏。棋盘游戏是顺序游戏的完美例子,也被称为回合制或扩展形式的游戏。
- 不完美信息和完美信息博弈:在完美信息博弈中,每个玩家都知道另一个玩家的移动,也知道另一个玩家可能会应用的各种策略来赢得最终的季后赛。然而,在不完全信息博弈中,没有玩家知道对方在做什么。卡片是不完美信息游戏的一个很好的例子,而国际象棋是完美信息游戏的完美例子。
- 非对称和对称博弈:非对称博弈是指每个玩家都有不同且通常相互冲突的最终目标的胜利。对称博弈是所有玩家都有相同的最终目标,但每个人所使用的策略完全不同的博弈。
- 合作与非合作博弈:在非合作博弈中,每个玩家为自己进行游戏,而在合作博弈中,玩家结成联盟以达到最终目标。
纳什均衡:
纳什均衡可以被认为是博弈论的精髓。它基本上是一种状态,一种游戏中多个玩家协作的平衡点。纳什均衡保证了每个玩家的最大利润。
让我们尝试在生成对抗网络 (GAN) 的帮助下理解这一点。
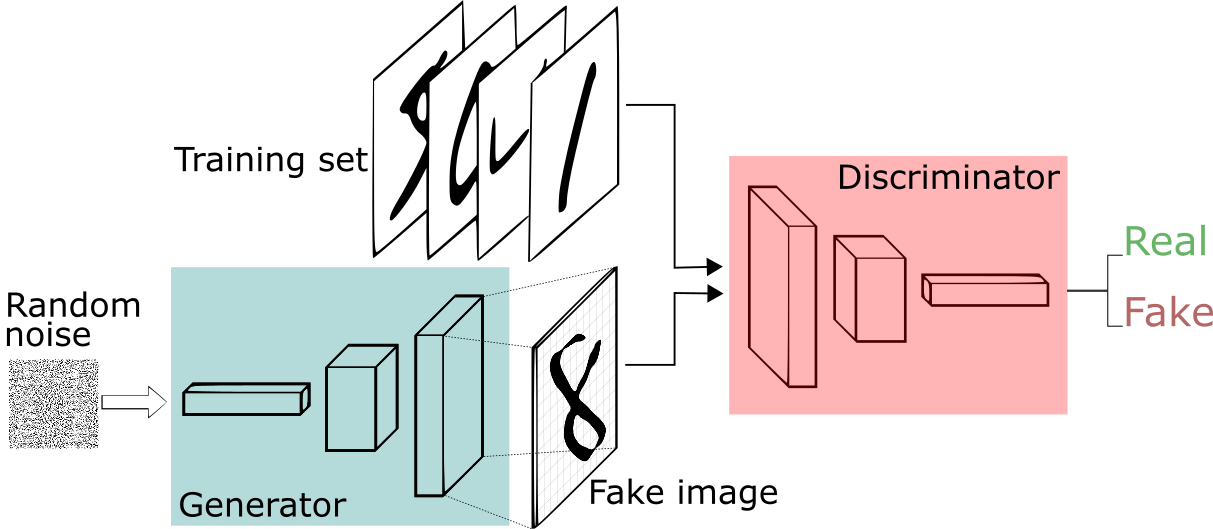
什么是 GAN?
它是两个神经网络的组合:判别器和生成器。生成器神经网络接受输入图像进行分析,然后生成新的样本图像,这些图像尽可能接近地表示实际输入图像。生成图像后,将它们发送到鉴别器神经网络。这个神经网络判断发送给它的图像,并将它们分类为生成图像和实际输入图像。如果图像被归类为原始图像,则 DNN 改变其判断参数。如果图像被归类为生成图像,则图像被拒绝并返回到 GNN。然后 GNN 会更改其参数以提高所生成图像的质量。
这是一个竞争过程,直到两个神经网络都不需要对其参数进行任何更改并且两个神经网络都无法进一步改进为止。这种没有进一步改善的状态被称为 NASH 均衡。换句话说,GAN 是一个 2 人竞争游戏,其中两个玩家都在不断优化自己以找到纳什均衡。
但是我们如何知道博弈是否达到了纳什均衡?
在任何游戏中,其中一个代理人需要在其他代理人面前披露他们的策略。启示后,如果没有任何玩家改变策略,则可以理解为游戏达到了纳什均衡。
现在我们已经了解了博弈论的基础知识,让我们尝试了解如何在同时博弈中获得纳什均衡。有很多例子,但最著名的是囚徒困境。还有更多的例子,例如封闭袋交换游戏、朋友或敌人游戏和迭代的雪堆游戏。
在所有这些比赛中,都有两名球员参与,最终的季后赛是两名球员必须做出决定的结果。双方都必须在叛逃和合作之间做出选择。如果双方球员合作,最终的季后赛对双方都是有利的。然而,如果双方都出局,最终的季后赛对双方球员都是不利的。如果同时出现一名球员叛逃和另一名合作的情况,最终季后赛将对一名球员有利,对另一名球员不利。
在这里,纳什均衡起着重要的作用。只有双方球员都制定了一个互惠互利的策略,并为双方提供了一个积极的季后赛,这个问题的解决方案才会是最佳的。
还有更多真实的例子和大量代码试图解决这个难题。然而,基本本质是在不舒服的情况下达到纳什均衡。
博弈论现在在哪里?
博弈论在公共卫生服务、公共安全和野生动物等领域的各种应用中正日益成为现实世界的一部分。目前,博弈论正被用于 GAN、多智能体系统以及模仿和强化学习中的对抗训练。在完全信息和对称博弈的情况下,许多机器学习和深度学习技术都适用。真正的挑战在于开发处理不完整信息游戏的技术,例如扑克。游戏的复杂性在于卡牌的组合太多,以及各玩家所持卡牌的不确定性。