获取包含给定子字符串的 Pandas DataFrame 中的所有行
让我们看看如何借助不同的示例获取包含给定子字符串的 Pandas DataFrame 中的所有行。
代码 #1:检查位置列中的值 PG
# importing pandas
import pandas as pd
# Creating the dataframe with dict of lists
df = pd.DataFrame({'Name': ['Geeks', 'Peter', 'James', 'Jack', 'Lisa'],
'Team': ['Boston', 'Boston', 'Boston', 'Chele', 'Barse'],
'Position': ['PG', 'PG', 'UG', 'PG', 'UG'],
'Number': [3, 4, 7, 11, 5],
'Age': [33, 25, 34, 35, 28],
'Height': ['6-2', '6-4', '5-9', '6-1', '5-8'],
'Weight': [89, 79, 113, 78, 84],
'College': ['MIT', 'MIT', 'MIT', 'Stanford', 'Stanford'],
'Salary': [99999, 99994, 89999, 78889, 87779]},
index =['ind1', 'ind2', 'ind3', 'ind4', 'ind5'])
print(df, "\n")
print("Check PG values in Position column:\n")
df1 = df['Position'].str.contains("PG")
print(df1)
输出: 
但是这个结果似乎不是很有帮助,因为它返回带有索引的布尔值。让我们看看我们是否可以做得更好。
代码 #2:获取满足条件的行
# importing pandas as pd
import pandas as pd
# Creating the dataframe with dict of lists
df = pd.DataFrame({'Name': ['Geeks', 'Peter', 'James', 'Jack', 'Lisa'],
'Team': ['Boston', 'Boston', 'Boston', 'Chele', 'Barse'],
'Position': ['PG', 'PG', 'UG', 'PG', 'UG'],
'Number': [3, 4, 7, 11, 5],
'Age': [33, 25, 34, 35, 28],
'Height': ['6-2', '6-4', '5-9', '6-1', '5-8'],
'Weight': [89, 79, 113, 78, 84],
'College': ['MIT', 'MIT', 'MIT', 'Stanford', 'Stanford'],
'Salary': [99999, 99994, 89999, 78889, 87779]},
index =['ind1', 'ind2', 'ind3', 'ind4', 'ind5'])
df1 = df[df['Position'].str.contains("PG")]
print(df1)
输出: 
代码 #3:过滤 Team 包含“Boston”或 College 包含“MIT”的所有行。
# importing pandas
import pandas as pd
# Creating the dataframe with dict of lists
df = pd.DataFrame({'Name': ['Geeks', 'Peter', 'James', 'Jack', 'Lisa'],
'Team': ['Boston', 'Boston', 'Boston', 'Chele', 'Barse'],
'Position': ['PG', 'PG', 'UG', 'PG', 'UG'],
'Number': [3, 4, 7, 11, 5],
'Age': [33, 25, 34, 35, 28],
'Height': ['6-2', '6-4', '5-9', '6-1', '5-8'],
'Weight': [89, 79, 113, 78, 84],
'College': ['MIT', 'MIT', 'MIT', 'Stanford', 'Stanford'],
'Salary': [99999, 99994, 89999, 78889, 87779]},
index =['ind1', 'ind2', 'ind3', 'ind4', 'ind5'])
df1 = df[df['Team'].str.contains("Boston") | df['College'].str.contains('MIT')]
print(df1)
输出:  代码#4:过滤行检查团队名称包含'波士顿和位置必须是PG。
代码#4:过滤行检查团队名称包含'波士顿和位置必须是PG。
# importing pandas module
import pandas as pd
# making data frame
df = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
df1 = df[df['Team'].str.contains('Boston') & df['Position'].str.contains('PG')]
df1
输出: 
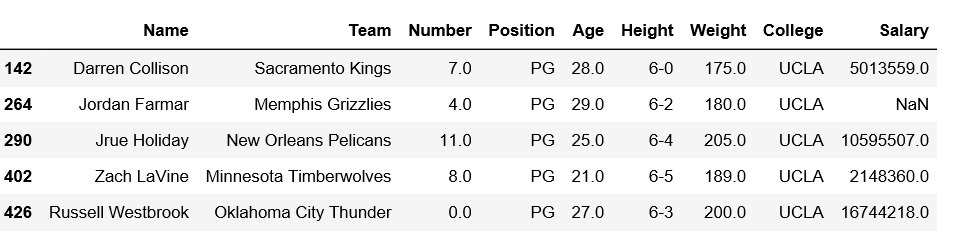
代码 #5:过滤行检查 Position 是否包含 PG,College 必须包含类似 UC。
# importing pandas module
import pandas as pd
# making data frame
df = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
df1 = df[df['Position'].str.contains("PG") & df['College'].str.contains('UC')]
df1
输出: