特征选择的卡方检验——数学解释
任何有监督的机器学习项目涉及的主要任务之一是从给定的数据集中选择最佳特征以获得最佳结果。选择这些特征的一种方法是卡方检验。
在数学上,对两个分布进行卡方检验,这两个分布确定了它们各自方差的相似程度。在其零假设中,它假设给定的分布是独立的。因此,该测试可用于通过确定输出类标签最依赖的特征来确定给定数据集的最佳特征。对于数据集中的每个特征,  计算,然后按照降序排列
计算,然后按照降序排列 价值。的价值越高
价值。的价值越高 ,输出标签对特征的依赖程度越高,特征对确定输出的重要性就越高。
,输出标签对特征的依赖程度越高,特征对确定输出的重要性就越高。
让有问题的特征有 m 个属性值,输出有 k 个类标签。那么值 由以下表达式给出:-
由以下表达式给出:-

在哪里
 – 观察频率
– 观察频率
 – 预期频率
– 预期频率
对于每个特征,创建一个包含 m 行和 k 列的列联表。每个单元格 (i,j) 表示属性特征为 i 和类标签为 k 的行数。因此,该表中的每个单元格表示观察到的频率。为了计算每个单元格的期望频率,首先计算特征值在总数据集中的比例,然后乘以当前类标签的总数。
解决的例子:
考虑下表:-
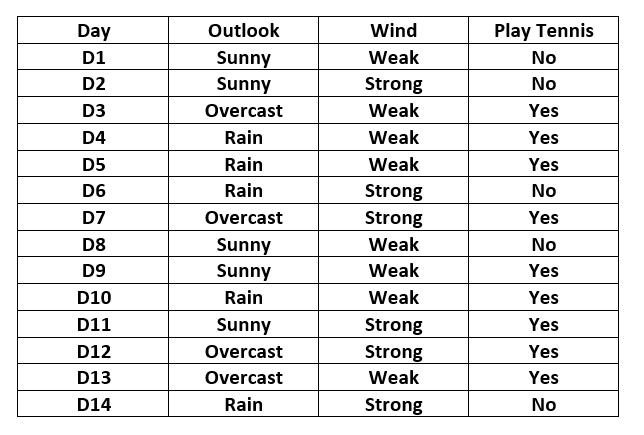
这里的输出变量是名为“PlayTennis”的列,它确定在给定天气条件的给定日期是否打网球。
特征“Outlook”的列联表构造如下:-
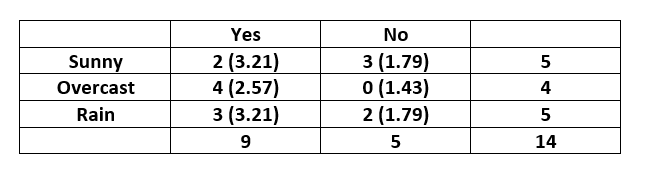
请注意,每个单元格的预期值在括号内给出。
单元格 (Sunny,Yes) 的预期值计算为 对其他人也是如此。
对其他人也是如此。
这 价值计算如下: -
价值计算如下: -


特征“风”的列联表构造如下:-

这 价值计算如下: -
价值计算如下: -


比较这两个分数,我们可以得出结论,“风”特征比“展望”特征在确定输出方面更重要。
本文演示了如何使用卡方检验进行特征选择。