Z-test 是一种统计方法,用于确定测试统计量的分布是否可以近似为正态分布。它是在方差已知且样本量较大(应>=30)时确定两个样本均值是否近似相同或不同的方法。
何时使用 Z 检验:
- 样本量应该大于 30。否则,我们应该使用 t 检验。
- 样本应从总体中随机抽取。
- 应该知道总体的标准偏差。
- 从总体中抽取的样本应该相互独立。
- 数据应该是正态分布的,但是对于大样本量,它被假定为正态分布。
假设检验
假设是对对象特定属性的有根据的猜测/声明。假设检验是一种验证实验主张的方法。
- 零假设:零假设是一种声明,即总体参数(例如比例、均值或标准差)的值等于某个声称的值。我们要么拒绝,要么不能拒绝原假设。零假设由H 0表示。
- 备择假设:备择假设是声明参数的值与声称的值不同。用H A表示。
显着性水平:表示我们接受或拒绝原假设的显着性程度。由于在大多数实验中,接受或拒绝假设不可能达到 100% 的准确度,因此我们选择一个显着性水平。它由 alpha (∝)表示。
执行 Z 检验的步骤:
- 首先,确定原假设和替代假设。
- 确定显着性水平 (∝)。
- 使用 z-test 找到 z 的临界值
- 计算 z 检验统计量。下面是计算 z 检验统计量的公式。

- 在哪里,
- X¯:样本的平均值。
- Mu:人口的平均值。
- Sd:总体的标准差。
- n:样本量。
- 现在与假设进行比较,决定是否拒绝原假设
Z 检验的类型
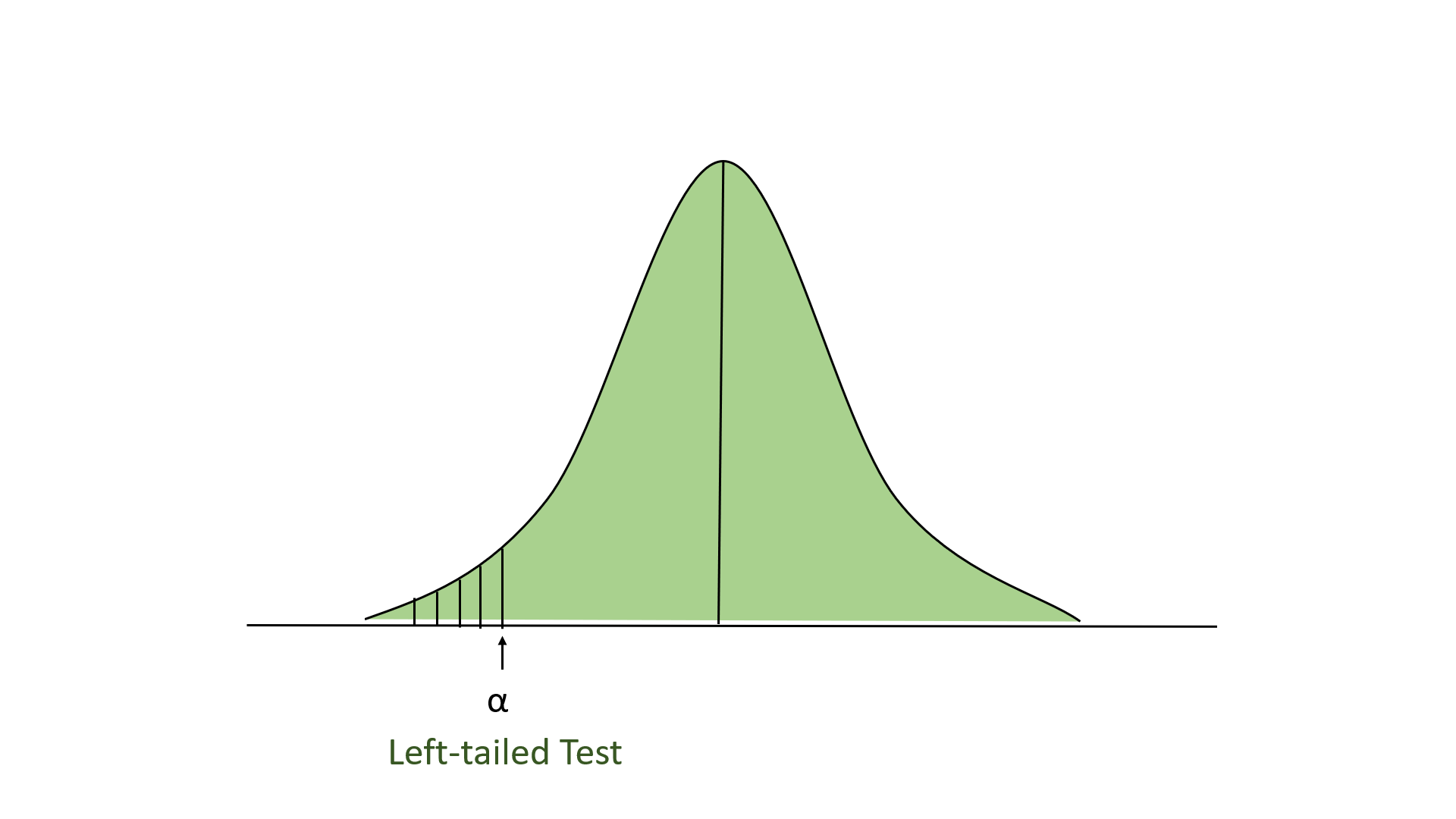
- 左尾测试:在这个测试中,我们的拒绝区域位于分布的最左边。这里我们的零假设是声称的价值小于或等于平均人口价值。
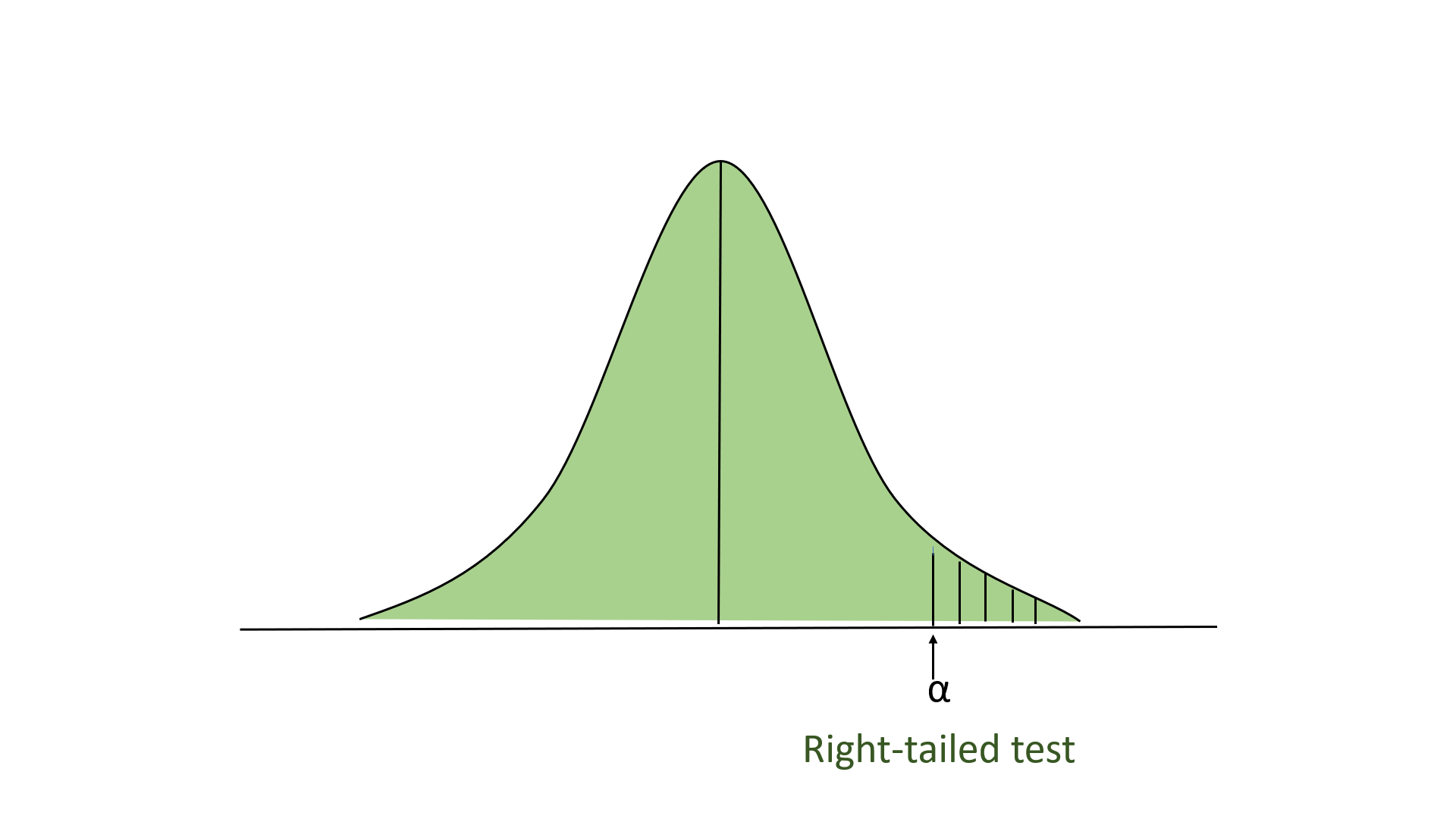
- 右尾测试:在这个测试中,我们的拒绝区域位于分布的最右边。这里我们的零假设是声称的价值小于或等于平均人口价值。
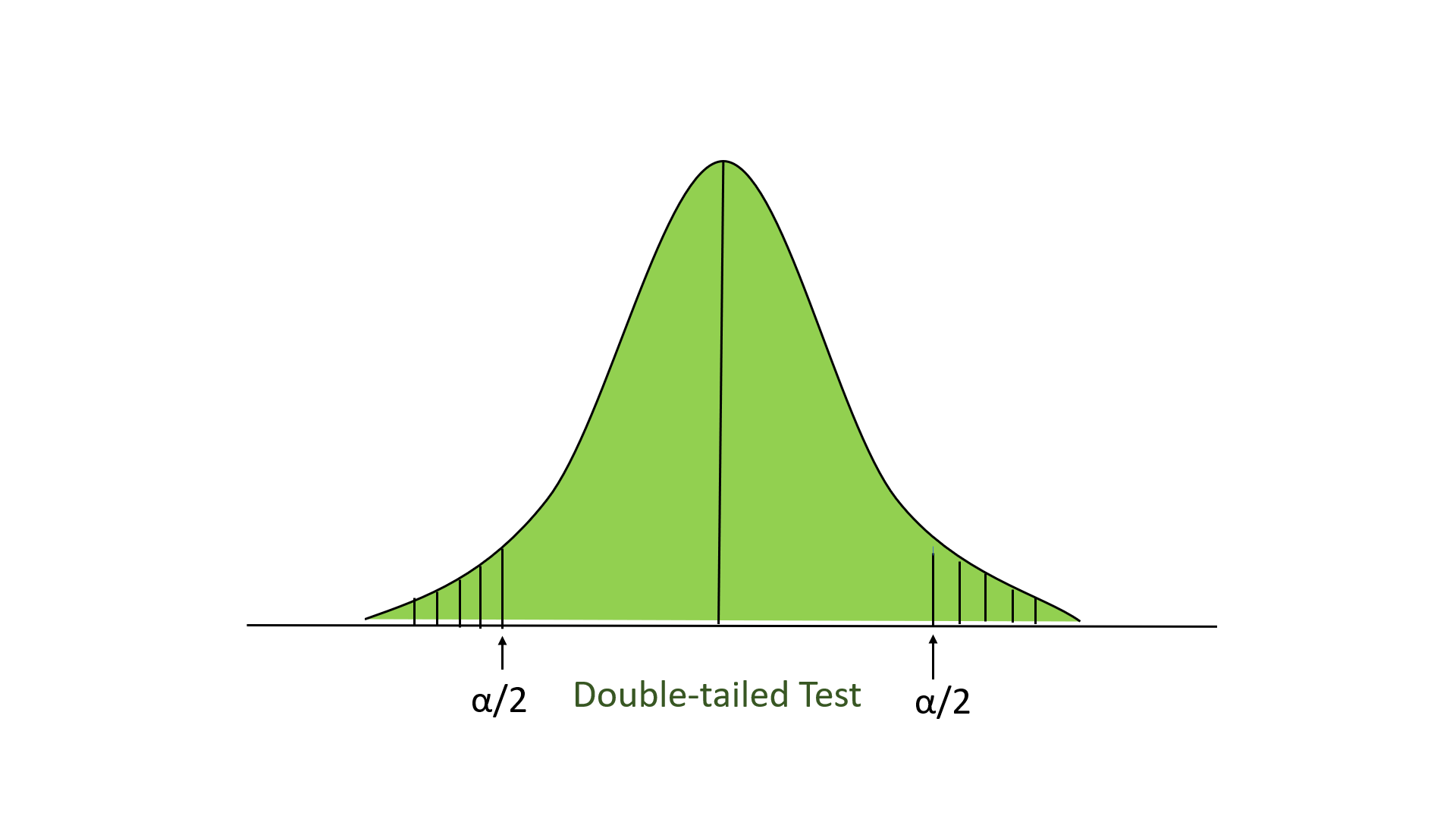
- 双尾测试:在这个测试中,我们的拒绝区域位于分布的两个极端。这里我们的零假设是声称的价值等于平均人口价值。
下面是执行 z-test 的示例:
问题:一所学校声称学生的学习比一般学校更聪明。在计算 50 名学生的 IQ 分数时,平均值为 11。总体 IQ 的平均值为 100,标准差为 15。在 5% 的显着性水平上说明校长的主张是否正确。
- 首先,我们定义零假设和备择假设。我们的零假设将是:
和我们的替代假设。
- 说明显着性水平。在这里,我们在这个问题中给出的显着性水平(∝=0.05),如果没有给出,那么我们取 ∝=0.05。
- 现在,我们查看 z 表。对于 ∝=0.05 的值,右尾检验的 z 得分为 1.645。
- 现在,我们对问题进行 Z 检验:

- 在哪里:
- X = 110
- 平均值(亩)= 100
- 标准偏差 (sigma) = 15
- 显着性水平 (alpha) = 0.05
- n = 50
- 这里 4.71 > 1.645,所以我们拒绝原假设。如果 z-test 统计量小于 z-score,那么我们不会拒绝原假设。
Python3
# imports
import math
import numpy as np
from numpy.random import randn
from statsmodels.stats.weightstats import ztest
# Generate a random array of 50 numbers having mean 110 and sd 15
# similar to the IQ scores data we assume above
mean_iq = 110
sd_iq = 15/math.sqrt(50)
alpha =0.05
null_mean =100
data = sd_iq*randn(50)+mean_iq
# print mean and sd
print('mean=%.2f stdv=%.2f' % (np.mean(data), np.std(data)))
# now we perform the test. In this function, we passed data, in the value parameter
# we passed mean value in the null hypothesis, in alternative hypothesis we check whether the
# mean is larger
ztest_Score, p_value= ztest(data,value = null_mean, alternative='larger')
# the function outputs a p_value and z-score corresponding to that value, we compare the
# p-value with alpha, if it is greater than alpha then we do not null hypothesis
# else we reject it.
if(p_value < alpha):
print("Reject Null Hypothesis")
else:
print("Fail to Reject NUll Hypothesis")Reject Null Hypothesis
两次抽样 z 检验:
在这个测试中,我们提供了 2 个正态分布的独立种群,我们从这两个种群中随机抽取样本。在这里,我们认为 u 1和 u 2是总体均值 X 1和 X 2是观察到的样本均值。在这里,我们的零假设可能是这样的:
和替代假设
以及计算z-test分数的公式:

其中sigma 1和sigma 2是标准差, n 1和 n 2是对应于 u 1和 u 2的总体样本量。
第一类错误和第二类错误:
- 第一类错误:当我们拒绝原假设时,即使假设为真,也会发生第一类错误。此错误由 alpha 表示。
- 第二类错误:当我们没有拒绝原假设时,即使假设是错误的,也会发生第二类错误。此错误由 beta 表示。
| Null Hypothesis is TRUE | Null Hypothesis is FALSE | |
|---|---|---|
| Reject Null Hypothesis |
Type I Error (False Positive) |
Correct decision |
| Fail to Reject the Null Hypothesis | Correct decision |
Type II error (False Negative) |