决策树中的基尼杂质和熵 – ML
机器学习是一个计算机科学领域,它为计算机提供了无需明确编程即可学习的能力。机器学习是每个人都想学习的最需要的技术之一,大多数公司都需要高技能的机器学习工程师。在这个领域,有各种机器学习算法可以轻松解决复杂的问题。这些算法是高度自动化和自我修改的,随着时间的推移,随着数据量的增加和所需的人工干预的减少,它们会不断改进。要了解每个 ML 工程师都应该知道的顶级机器学习算法,请单击此处。
在本文中,我们将更多地关注决策树算法中的基尼杂质和熵方法,以及它们中哪个更好。

决策树是我们在机器学习中使用的最流行和最强大的分类算法之一。名称本身的决策树表示它用于根据给定的数据集做出决策。决策树背后的概念是它有助于选择适当的特征将树拆分为子部分,并且拆分背后使用的算法是 ID3。如果决策树构建合适,那么树的深度将更小,否则深度将更大。为了以有效的方式构建决策树,我们使用了熵的概念。要了解有关决策树的更多信息,请单击此处。在本文中,我们将更加关注基尼不纯度和熵之间的区别。
熵:
如上所述,熵帮助我们构建合适的决策树来选择最佳分离器。熵可以定义为子分裂纯度的度量。熵总是在 0 到 1 之间。任何分裂的熵都可以通过这个公式来计算。

该算法在每次分割后计算每个特征的熵,随着分割的继续,它选择最佳特征并根据它开始分割。关于熵的详细计算,可以参考这篇文章。
基尼杂质:
基尼杂质的内部工作也有点类似于决策树中熵的工作。在决策树算法中,两者都用于通过根据适当的特征进行分裂来构建树,但是这两种方法的计算有很大的不同。使用这个公式可以计算分裂后特征的基尼杂质。
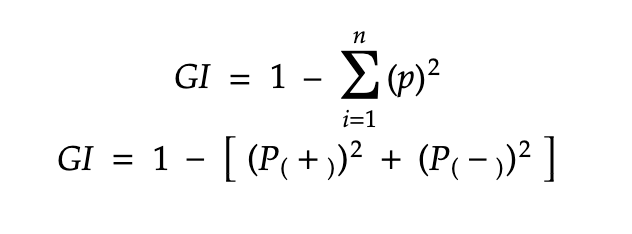
详细计算基尼杂质的例子,可以参考这篇文章。通过使用上述公式,计算特征/分裂的基尼杂质。
熵与基尼不纯度:
现在我们已经了解了基尼杂质和熵及其实际工作原理。此外,我们已经看到了如何计算分割/特征的基尼杂质/熵。但是这里出现的主要问题是为什么我们需要两种计算方法,哪个更好?

两种方法的内部工作非常相似,都用于在每次新拆分后计算特征/拆分。但是如果我们比较这两种方法,那么就计算能力而言,基尼杂质比熵更有效。正如你在熵图中看到的,它首先增加到 1 然后开始减少,但在基尼杂质的情况下,它只增加到 0.5 然后开始减少,因此它需要的计算能力更少。 Entropy 的范围在 0 到 1 之间,Gini Impurity 的范围在 0 到 0.5 之间。因此我们可以得出结论,与选择最佳特征的熵相比,基尼杂质更好。