毫升 |频繁模式增长算法
先决条件:先验算法
先决条件: Trie 数据结构
Apriori 算法的两个主要缺点是:
- 在每一步,都必须建立候选集。
- 为了构建候选集,算法必须反复扫描数据库。
这两个属性不可避免地使算法变慢。为了克服这些冗余步骤,开发了一种新的关联规则挖掘算法,称为频繁模式增长算法。它通过将所有事务存储在 Trie 数据结构中来克服 Apriori 算法的缺点。考虑以下数据:-

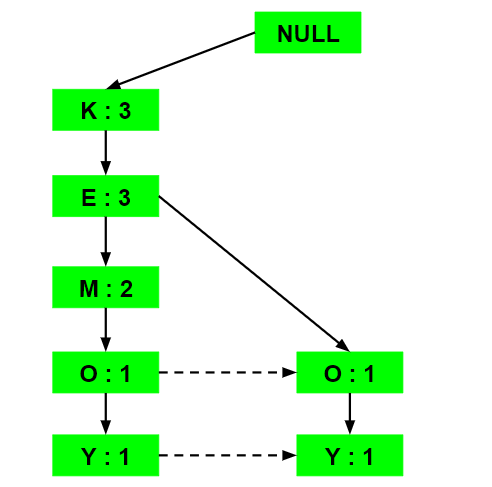
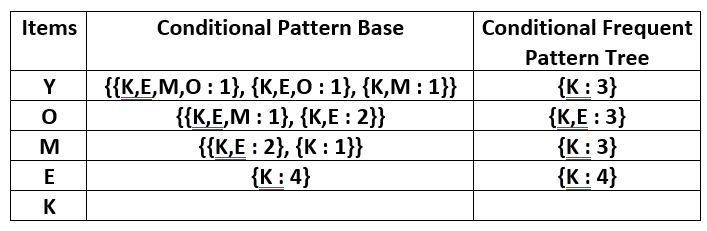
上面给出的数据是一个假设的交易数据集,每个字母代表一个项目。计算每个单独项目的频率:- 设最小支持度为 3。建立一个频繁模式集,其中包含频率大于或等于最小支持度的所有元素。这些元素按其各自频率的降序存储。插入相关项目后,集合 L 如下所示:- L = {K:5,E:4,M:3,O:3,Y:3} 现在,对于每个事务,都构建了相应的Ordered-Item 集。它是通过迭代频繁模式集并检查当前项目是否包含在相关事务中来完成的。如果包含当前项目,则将该项目插入当前事务的 Ordered-Item 集中。下表是为所有事务构建的: 现在,所有 Ordered-Item 集都被插入到 Trie 数据结构中。 a)插入集合 {K, E, M, O, Y}: 在这里,所有项目都简单地按照集合中出现的顺序一个接一个地链接,并将每个项目的支持计数初始化为 1。 b)插入集合 {K, E, O, Y}: 在插入元素 K 和 E 之前,只需将支持计数增加 1。在插入 O 时,我们可以看到 E 和 O 之间没有直接链接,因此使用支持计数初始化项目 O 的新节点为 1 并且项目 E 链接到这个新节点。在插入 Y 时,我们首先为项目 Y 初始化一个新节点,支持计数为 1,并将 O 的新节点与 Y 的新节点链接。 c)插入集合 {K, E, M}: 这里简单地将每个元素的支持计数增加 1。 d)插入集合 {K, M, Y}: 与步骤 b) 类似,首先增加 K 的支持数,然后初始化 M 和 Y 的新节点并相应地链接。 e)插入集合 {K, E, O}: 这里只是增加了各个元素的支持数。请注意,项目 O 的新节点的支持计数增加了。 现在,对于每个项目,计算条件模式基,它是通向频繁模式树中给定项目的任何节点的所有路径的路径标签。请注意,下表中的项目按其频率的升序排列。 现在为每个项目构建条件频繁模式树。它是通过获取该项目的条件模式库中所有路径中共有的元素集并通过对条件模式库中所有路径的支持计数求和来计算其支持计数来完成的。 从条件频繁模式树中,频繁模式规则是通过将条件频繁模式树集合的项目与下表中给出的项目的对应项配对来生成的。 对于每一行,可以推断出两种类型的关联规则,例如对于包含元素的第一行,可以推断出规则 K -> Y 和 Y -> K。为了确定有效规则,计算两个规则的置信度,并保留置信度大于或等于最小置信度值的规则。