毫升 |期望最大化算法
在机器学习的实际应用中,很常见的是有许多相关的特征可供学习,但只有其中的一小部分是可观察到的。因此,对于有时可观察有时不可观察的变量,我们可以使用观察到该变量可见的实例进行学习,然后在不可观察的实例中预测其值。
另一方面,期望最大化算法也可以用于潜在变量(不能直接观察到的变量,实际上是从其他观察变量的值中推断出来的),以便在一般形式的条件下预测它们的值我们知道控制这些潜在变量的概率分布。该算法实际上是机器学习领域许多无监督聚类算法的基础。
它在 1977 年由 Arthur Dempster、Nan Laird 和 Donald Rubin 发表的一篇论文中得到解释、提出并命名。它用于在涉及潜在变量且数据缺失或不完整的情况下查找统计模型的局部最大似然参数。算法:
- 给定一组不完整的数据,考虑一组起始参数。
- 期望步骤(E-步骤):使用观察到的数据集可用数据,估计(猜测)缺失数据的值。
- 最大化步骤(M-步骤):使用期望(E)步骤后生成的完整数据以更新参数。
- 重复步骤 2 和步骤 3 直到收敛。
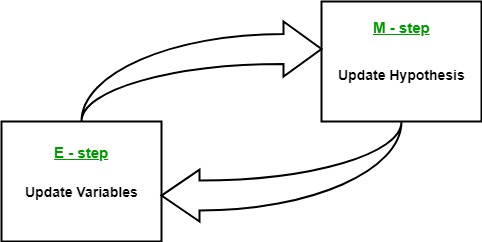
期望最大化算法的本质是使用数据集的可用观测数据来估计缺失的数据,然后使用该数据更新参数的值。让我们详细了解EM算法。
- 最初,考虑一组参数的初始值。假设观察数据来自特定模型,则向系统提供一组不完整的观察数据。
- 下一步被称为“期望”——步骤或E-步骤。在这一步中,我们使用观察到的数据来估计或猜测缺失或不完整数据的值。它主要用于更新变量。
- 下一步称为“最大化”步或 M 步。在这一步中,我们使用前面“期望”步骤中生成的完整数据来更新参数的值。它主要用于更新假设。
- 现在,在第四步中,检查值是否收敛,如果是,则停止,否则重复步骤 2和步骤 3,即“期望”-步骤和“最大化”-步骤,直到收敛发生。
EM算法流程图—— 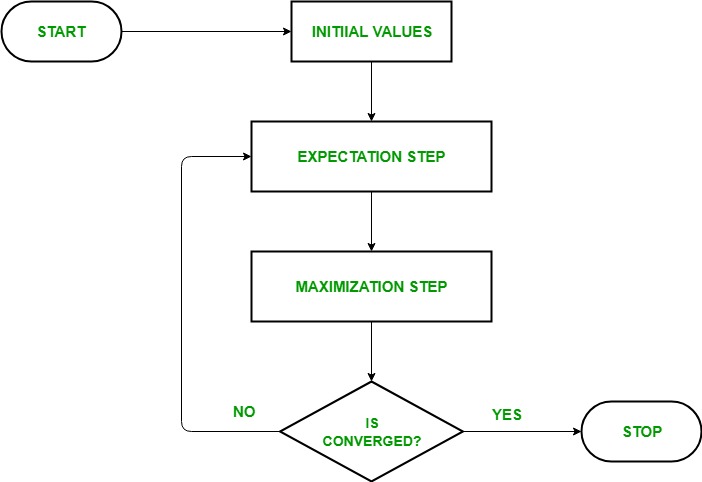
EM算法的使用——
- 它可用于填充样本中缺失的数据。
- 它可以作为集群无监督学习的基础。
- 它可用于估计隐马尔可夫模型(HMM)的参数。
- 它可用于发现潜在变量的值。
EM算法的优点——
- 总是保证可能性会随着每次迭代而增加。
- E-step 和 M-step 对于许多实施方面的问题通常很容易。
- M 步的解通常以封闭形式存在。
EM算法的缺点——
- 它的收敛速度很慢。
- 它只收敛到局部最优。
- 它需要前向和后向概率(数值优化只需要前向概率)。