mrjob是YELP为 MapReduce 开发的著名Python库。该库帮助开发人员使用Python编程语言编写 MapReduce 代码。开发人员可以使用 Amazon EMR(Elastic MapReduce)在他们的系统或云上本地测试使用mrjob编写的 MapReduce Python代码。 Amazon EMR 是 Amazon Web Services 为大数据目的提供的基于云的 Web 服务。 mrjob目前是 MapReduce 编程或 Hadoop Streaming 作业的活跃框架,并且对 Hadoop 与Python 的文档支持比当前可用的任何其他库或框架都好。使用mrjob ,我们可以在一个类中为 Mapper 和 Reducer 编写代码。如果我们没有安装 Hadoop 那么我们也可以测试 我们本地系统环境中的mrjob程序。 mrjob 支持Python 2.7/3.4+。
在您的系统中安装mrjob
pip install mrjob # for python3 use pip3

因此,让我们解决一个演示问题,以了解如何将这个库与 Hadoop 结合使用。
目的:使用Python mrjob 计算文本文件中单词出现的次数
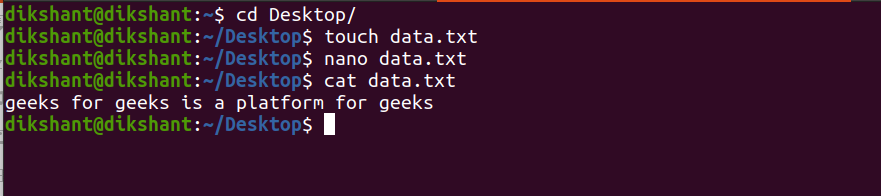
第 1 步:创建一个名为data.txt的文本文件并向其中添加一些内容。
touch data.txt //used to create file in linux
nano data.txt // nano is a command line editor in linux
cat data.txt // used to see the inner content of file
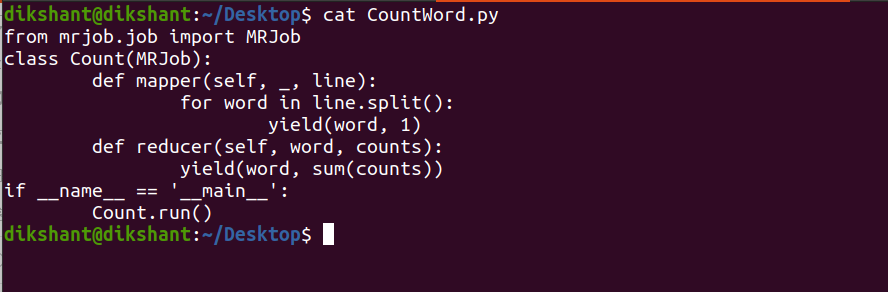
步骤 2:在 data.txt 文件可用的位置创建一个名为CountWord.py的文件。
touch CountWord.py // create the python file with name CountWord
第 3 步:将以下代码添加到此Python文件中。
Python3
from mrjob.job import MRJob
class Count(MRJob):
""" The below mapper() function defines the mapper for MapReduce and takes
key value argument and generates the output in tuple format .
The mapper below is splitting the line and generating a word with its own
count i.e. 1 """
def mapper(self, _, line):
for word in line.split():
yield(word, 1)
""" The below reducer() is aggregating the result according to their key and
producing the output in a key-value format with its total count"""
def reducer(self, word, counts):
yield(word, sum(counts))
"""the below 2 lines are ensuring the execution of mrjob, the program will not
execute without them"""
if __name__ == '__main__':
Count.run()下面是我的 CountWord.py 文件的图像。
第 4 步:如下所示在本地机器上运行Python文件以测试它是否工作正常(注意:我使用的是 python3)。
python CountWord.py data.txt
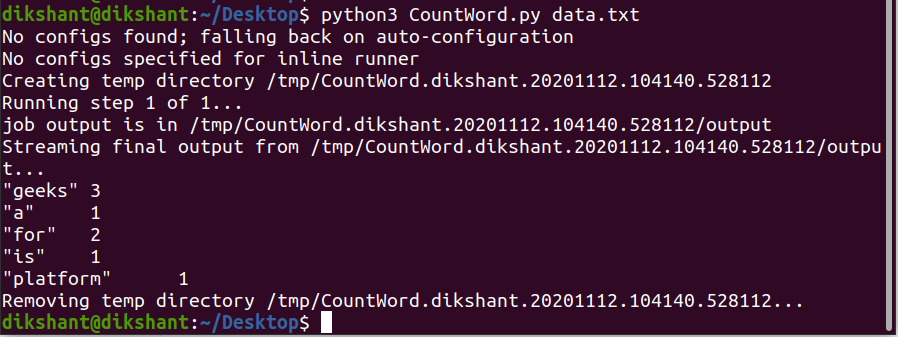
我们可以观察到它运行良好。默认情况下,mrjob 将输出生成到 STDOUT,即在终端上。
现在一旦我们确认 Mapper 和 Reducer 工作正常。然后我们可以将此代码部署到 Hadoop 集群或 Amazon EMR 并可以使用它。当我们想在 Hadoop 或 Amazon EMR 上运行 mrjob 代码时,我们必须在命令中指定 -r/–runner 选项。下面解释了可用于运行 mrjob 的不同选择。
| Choice | Description |
|---|---|
| -r inline | mrjob runs in a single python program(Default Option) |
| -r local | mrjob runs locally in some subprocess along with some Hadoop features |
| -r hadoop | mrjob runs on Hadoop |
| -r emr | mrjob runs on Amazon Elastic MapReduce |
在 Hadoop HDFS 上运行 mrjob
句法:
python -r hadoop
命令:
使用以下命令将data.txt发送到 HDFS (注意:我已经将 data.txt 发送到 HDFS 上的 C ountcontent文件夹) 。
hdfs dfs -put /home/dikshant/Desktop/data.txt /

运行以下命令在 Hadoop 上运行 mrjob。
python CountWord.py -r hadoop hdfs:///content/data.txt
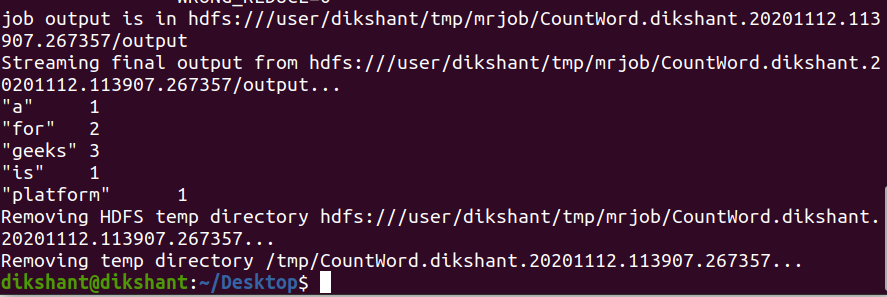
从上图中,我们可以清楚地看到,我们已经成功地对 HDFS 上可用的文本文件执行了 mrjob。