强化学习中的上置信界算法
在强化学习中,代理或决策者通过与世界交互来生成其训练数据。代理必须通过反复试验来了解其行为的后果,而不是被明确告知正确的行为。
多臂强盗问题
在强化学习中,我们使用多臂强盗问题来形式化使用 k 臂强盗在不确定性下进行决策的概念。 Multi-Armed Bandit Problem 中的决策者或代理可以在 k 个不同的动作之间进行选择,并根据它选择的动作获得奖励。 Bandit 问题用于描述强化学习中的基本概念,例如奖励、时间步长和值。

上图代表了一台老虎机,也被称为有两个杠杆的老虎机。我们假设每个杠杆都有单独的奖励分配,并且至少有一个杠杆可以产生最大的奖励。
每个杠杆对应的奖励的概率分布是不同的,赌徒(决策者)不知道。因此,这里的目标是确定在一组给定的试验后拉动哪个杠杆以获得最大奖励。
例如: 
想象一下在线广告试验,其中广告商想要衡量同一产品的三个不同广告的点击率。每当用户访问该网站时,广告商就会随机展示一个广告。然后广告商监控用户是否点击了广告。过了一会儿,广告商注意到一个广告似乎比其他广告效果更好。广告商现在必须决定是坚持使用效果最佳的广告还是继续进行随机研究。
如果广告商只展示一个广告,那么他就不能再收集其他两个广告的数据。也许其他广告中的一个更好,只是偶然出现的情况更糟。如果其他两个广告更糟,那么继续研究会对点击率产生不利影响。这个广告试验体现了不确定性下的决策。
在上面的例子中,代理的角色由广告商扮演。广告商必须在三个不同的操作之间进行选择,以显示第一个、第二个或第三个广告。每个广告都是一个动作。选择那个广告会产生一些未知的回报。最后,广告主在广告后获得的利润就是广告主获得的奖励。
行动价值:
为了让广告商决定哪个行动是最好的,我们必须定义采取每个行动的价值。我们使用概率语言使用动作值函数来定义这些值。选择动作q * (a) 的值被定义为我们从可能的动作集中采取动作a时收到的预期奖励R t 。

代理的目标是通过选择具有最高动作值的动作来最大化预期奖励。
行动价值估计:
由于选择一个动作的值,即Q * (a)是代理不知道的,所以我们将使用样本平均方法来估计它。 
探索与利用:
- 贪婪动作:当代理选择当前具有最大估计值的动作时。代理通过选择贪婪动作来利用其当前知识。
- Non-Greedy Action :当代理不选择最大的估计值并牺牲即时奖励以希望获得有关其他动作的更多信息时。
- 探索:它允许代理提高其对每个动作的了解。希望能带来长期利益。
- Exploitation :它允许代理选择贪婪的动作来尝试获得最大的短期利益奖励。纯粹贪婪的行动选择可能导致次优行为。
探索和利用之间出现了两难境地,因为代理不能同时选择探索和利用。因此,我们使用上置信界算法来解决探索开发困境
置信上限动作选择:
上置信界动作选择使用动作值估计中的不确定性来平衡探索和开发。由于当我们使用一组采样的奖励时,动作价值估计的准确性存在固有的不确定性,因此 UCB 使用估计中的不确定性来推动探索。
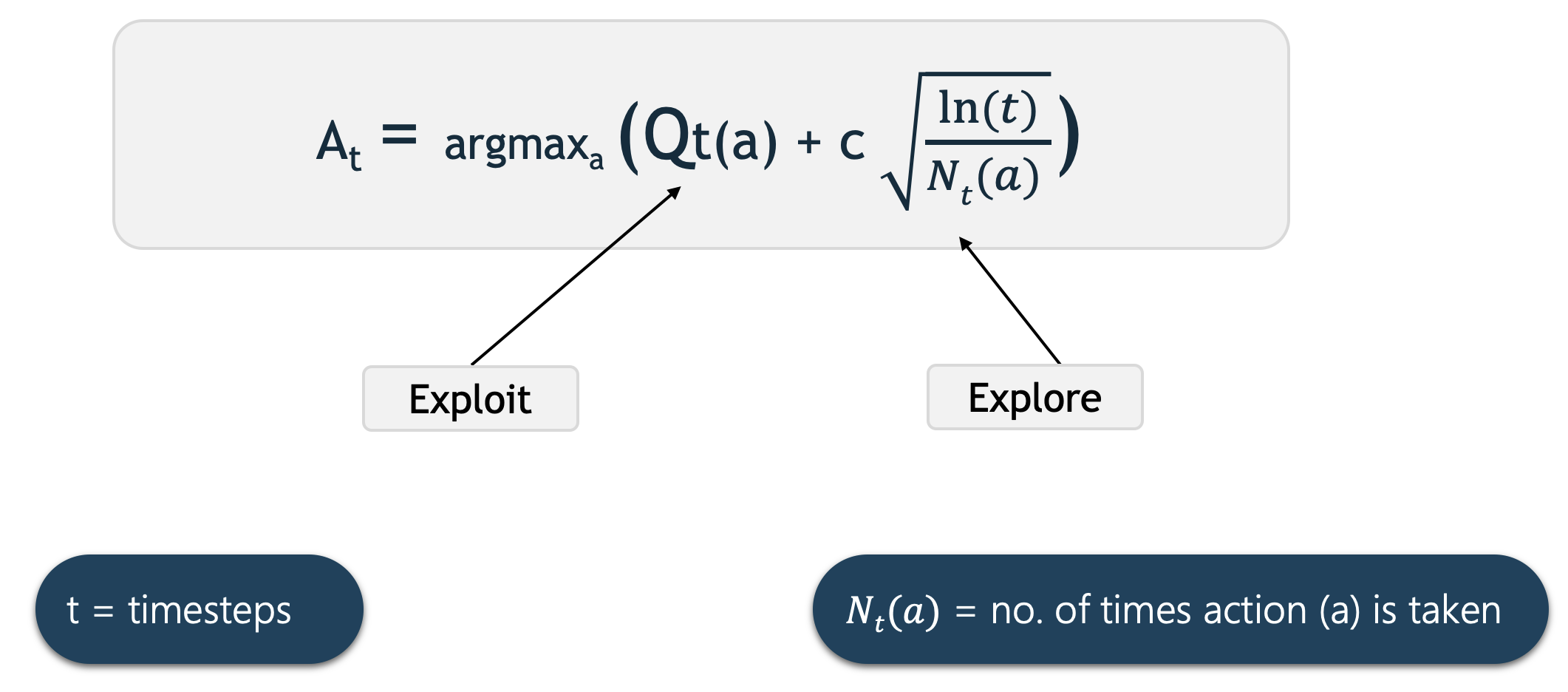
这里的Q t (a)表示在时间t 时对动作a的当前估计。我们选择具有最高估计动作值加上置信上限探索项的动作。

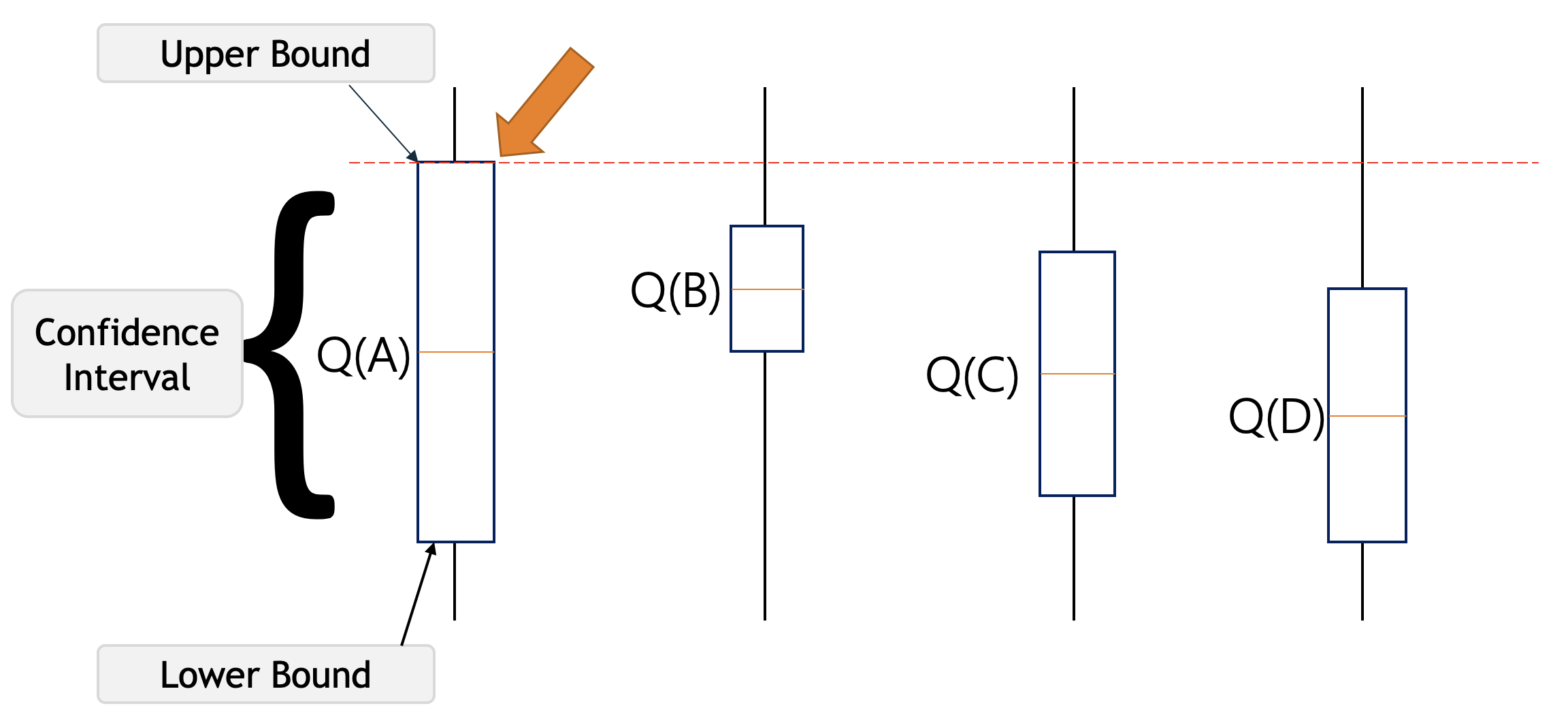
上图中的Q(A)表示动作A的当前动作值估计。括号表示围绕Q * (A)的置信区间,这表示我们确信动作A的实际动作值位于该区域的某个位置。
下括号称为下界,上括号称为上界。括号之间的区域是置信区间,表示估计中的不确定性。如果该区域非常小,那么我们就非常确定动作A的实际值接近我们的估计值。另一方面,如果区域很大,那么我们就不确定动作A的值是否接近我们的估计值。
置信上限遵循面对不确定性时乐观的原则,这意味着如果我们对某个行动不确定,我们应该乐观地假设它是正确的行动。
例如,假设我们在下图中有这四个具有相关不确定性的动作,我们的智能体不知道哪个是最佳动作。所以根据 UCB 算法,它会乐观地选择具有最高上限的动作,即A 。通过这样做,它要么具有最高的价值并获得最高的奖励,要么通过这样做,我们将了解我们最不了解的行动。
让我们假设在选择动作A 后,我们最终处于下图所示的状态。这次 UCB 将选择动作B,因为Q(B)具有最高的置信上限,因为它的动作值估计值最高,即使置信区间很小。 
最初,UCB 探索更多以系统地减少不确定性,但随着时间的推移,它的探索会减少。因此我们可以说,UCB 平均比其他算法(例如 Epsilon-greedy、Optimistic Initial Values 等)获得了更大的奖励。