📌 相关文章
- 在 R 编程中获取内核密度估计 – density()函数
- 在 R 编程中获取内核密度估计 – density()函数(1)
- Linux 内核
- Linux 内核(1)
- 什么是内核 (1)
- Parzen Windows 密度估计技术
- Parzen Windows 密度估计技术(1)
- 如何在 python 中获取内核数(1)
- 如何在 python 代码示例中获取内核数
- 什么是内核 - 任何代码示例
- 操作系统中的内核(1)
- 操作系统中的内核
- 操作系统中的内核
- 操作系统中的内核(1)
- Shell和内核之间的区别
- Shell和内核之间的区别(1)
- conda 中的 R 内核 (1)
- 离子本机内核 (1)
- 如何在 Seaborn 中创建饼图?
- 如何在 Seaborn 中创建饼图?(1)
- python中的seaborn是什么(1)
- seaborn python 中的子图 - TypeScript (1)
- 操作系统和内核的区别
- 操作系统和内核的区别(1)
- seaborn 下载 (1)
- jupyter 内核列表 (1)
- Seaborn教程(1)
- Seaborn教程
- Seaborn-简介
📜 Seaborn-内核密度估计
📅 最后修改于: 2020-11-06 06:44:23 🧑 作者: Mango
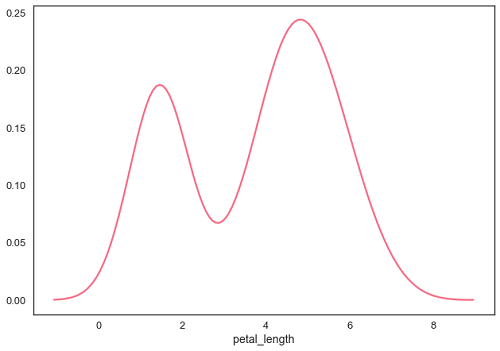
核密度估计(KDE)是一种估计连续随机变量的概率密度函数的方法。用于非参数分析。
在distplot中将hist标志设置为False将产生内核密度估计图。
例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'],hist=False)
plt.show()
输出
拟合参数分布
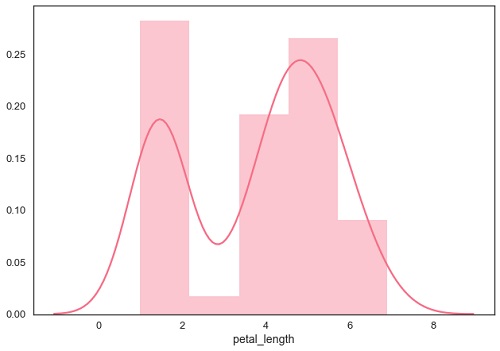
distplot()用于可视化数据集的参数分布。
例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.distplot(df['petal_length'])
plt.show()
输出
绘制双变量分布
双变量分布用于确定两个变量之间的关系。这主要涉及两个变量之间的关系以及一个变量相对于另一个变量的行为方式。
分析seaborn中的双变量分布的最佳方法是使用jointplot()函数。
Jointplot创建一个多面板图形,该图形可以投影两个变量之间的双变量关系,以及每个变量在独立轴上的单变量分布。
散点图
散点图是可视化分布的最便捷方法,其中每个观测值均通过x和y轴以二维图表示。
例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df)
plt.show()
输出
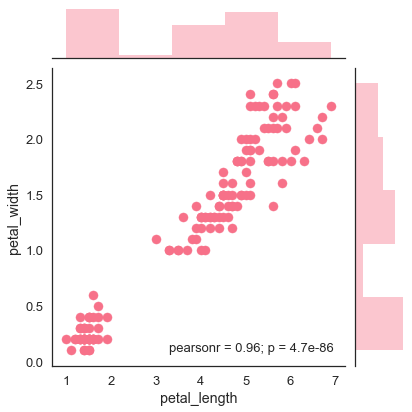
上图显示了虹膜数据中的花瓣长度和花瓣宽度之间的关系。该图的趋势表明,所研究的变量之间存在正相关。
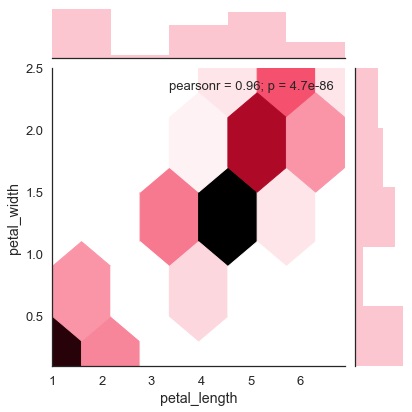
六边形图
当数据稀疏时,即当数据非常分散且难以通过散点图进行分析时,六边形合并用于双变量数据分析。
称为“种类”和值“十六进制”的附加参数绘制了六边形图。
例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df,kind = 'hex')
plt.show()
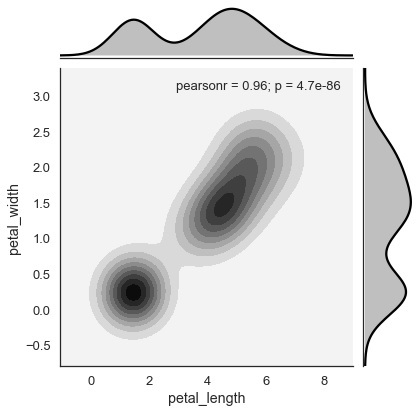
内核密度估计
内核密度估计是估计变量分布的非参数方法。在seaborn中,我们可以使用jointplot()绘制kde 。
将值’kde’传递给参数种类以绘制内核图。
例
import pandas as pd
import seaborn as sb
from matplotlib import pyplot as plt
df = sb.load_dataset('iris')
sb.jointplot(x = 'petal_length',y = 'petal_width',data = df,kind = 'hex')
plt.show()
输出