- pytorch 预测 - Python (1)
- pytorch 预测 - Python 代码示例
- pytorch 预测 conda (1)
- 数据挖掘-分类和预测(1)
- 数据挖掘-分类和预测
- PyTorch分类简介(1)
- PyTorch分类简介
- pytorch 预测 conda - 任何代码示例
- 使用线性回归预测python(1)
- 使用线性回归预测python代码示例
- PyTorch-线性回归(1)
- PyTorch-线性回归
- PyTorch线性回归(1)
- PyTorch线性回归
- 数据挖掘中分类和预测方法的区别
- 数据挖掘中分类和预测方法的区别(1)
- 使用PyTorch进行线性回归(1)
- 使用PyTorch进行线性回归
- PyTorch (1)
- R分类
- 桶分类
- 胺的分类
- 桶分类(1)
- R分类(1)
- 线性图
- 线性图(1)
- 筛线性 (1)
- 线性模型的PyTorch训练(1)
- 线性模型的PyTorch训练
📅 最后修改于: 2020-11-11 00:38:50 🧑 作者: Mango
预测和线性分类
在此,我们简要介绍了如何实现基于机器学习的算法,以训练线性模型来拟合一组数据点。
为此,无需具备任何深度学习的先验知识。我们将从讨论监督学习开始。我们将讨论监督学习的概念及其与之的关系。
机器学习
机器学习是AI的一种应用。机器学习(ML)使系统能够借助经验自动学习和改进。 ML专注于计算机程序的开发,该程序可以访问数据并将其用于自身学习。
学习的过程始于数据或观察,例如示例,说明或直接经验,以便根据我们提供的示例查找数据模式并在将来做出更好的决策。其目的是允许计算机在没有人工干预的情况下自动学习,并相应地调整操作。
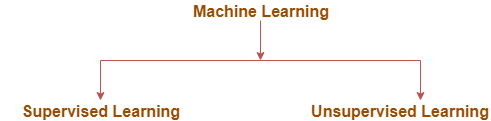
监督学习
顾名思义,主管是在担任教师。在监督学习中,我们使用标记良好的数据来训练或教导机器。标记正确的意味着几乎没有数据已被正确答案标记。之后,机器将获得一组新的数据。监督学习算法会分析训练数据并从标记的数据中产生正确的结果。
监督学习分为两大类算法:
- 分类:当输出变量或仅输出是诸如“红色”或“蓝色”或“疾病或无疾病”的类别时,分类问题就是一个问题。
- 回归:当输出变量或简单输出是实数或连续值(例如“工资”或“权重”)时,回归问题就是一个问题。
无监督学习
在无监督学习中,机器会使用既未分类也未标记的信息进行训练,并允许算法在没有指导的情况下对信息进行操作。在无监督学习中,任务是根据相似性,差异和模式对未分类的信息进行分组,而无需事先对数据进行训练。
没有主管,这意味着不会对机器进行培训。因此,机器仅限于自行查找隐藏的结构。
无监督学习分为两大类算法:
- 聚类:聚类问题是我们必须发现数据中固有分组的问题。例如按课程或年龄行为对学生进行分组。
- 关联:关联问题是一个问题,我们必须发现描述我们大部分数据的规则,例如购买苹果的人也想购买香蕉。
进行预测(创建数据模型)
进行预测是建立线性回归模型的第一步。在线性回归模型中,我们使用监督学习,因为回归是其第二大类。因此,对学习者进行了培训,并利用了与标记特征相关联的数据集,这些特征定义了我们训练数据的含义。
学习者能够在将新输入的数据提供给机器之前预测相应的输出。
查找预测的步骤
- 第一步是安装手电筒,然后将其导入使用。
- 下一步是初始化变量c和c以了解直线方程。
- 初始化线方程,使y = w * x + b,这里w是斜率,b是偏置项,y是预测。
- 预测是在forward()方法内部计算的。
让我们看一个例子,以了解如何在线性回归中进行预测。
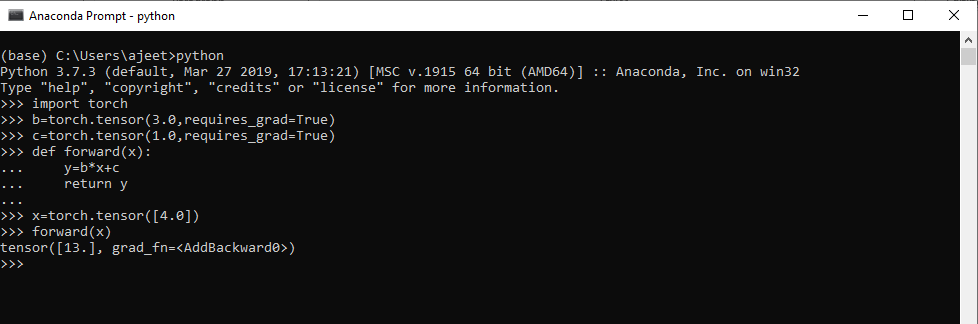
对于单个数据
import torch
b=torch.tensor(3.0,requires_grad=True)
c=torch.tensor(1.0,requires_grad=True)
def forward(x):
y=b*x+c
return y
x=torch.tensor([4.0])
forward(x)
输出:
tensor([13.], grad_fn=)
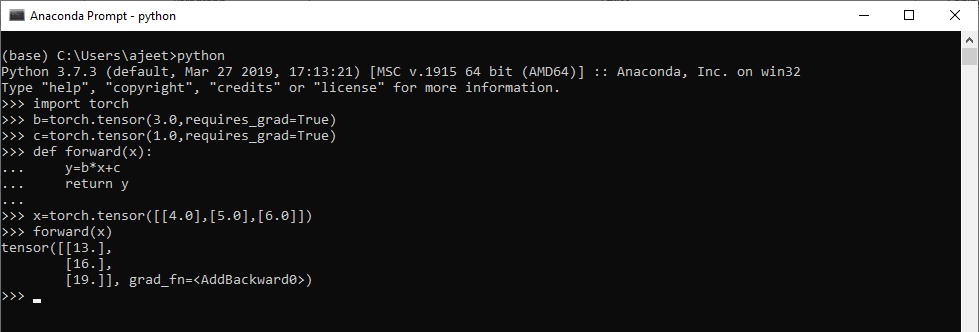
对于多个数据
import torch
b=torch.tensor(3.0,requires_grad=True)
c=torch.tensor(1.0,requires_grad=True)
def forward(x):
y=b*x+c
return y
x=torch.tensor([[4.0],[5.0],[6.0]])
forward(x)
输出:
tensor([[13.],
[16.],
[19.]], grad_fn=)
使用线性类进行预测
绑定预测还有另一种标准方法。为此,我们必须导入torch.nn包的线性类。在此,我们使用manual_seed()方法生成随机数。当我们使用线性类创建模型时,将为线性类提供随机数值,这自召回以来就很有意义。
让我们看一个如何使用model和manual_seed()方法进行预测的示例。
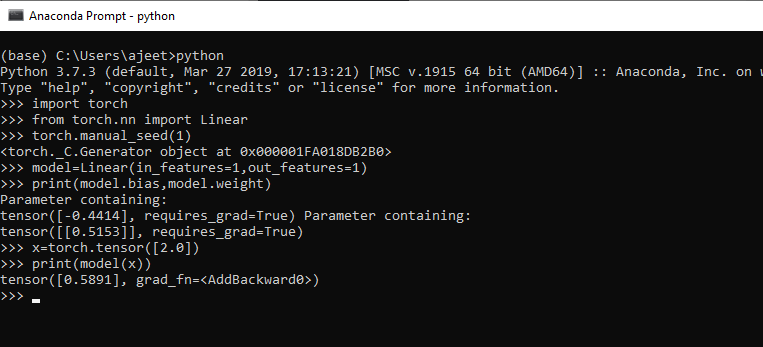
对于单个数据
import torch
from torch.nn import Linear
torch.manual_seed(1)
model=Linear(in_features=1,out_features=1)
print(model.bias,model.weight)
x=torch.tensor([2.0])
print(model(x))
输出:
Parameter containing:
tensor([-0.4414], requires_grad=True) Parameter containing:
tensor([[0.5153]], requires_grad=True)
tensor([0.5891], grad_fn=)
对于多个数据
import torch
from torch.nn import Linear
torch.manual_seed(1)
model=Linear(in_features=1,out_features=1)
print(model.bias,model.weight)
x=torch.tensor([[2.0],[4.0],[6.0]])
print(model(x))
输出:
Parameter containing:
tensor([-0.4414], requires_grad=True) Parameter containing:
tensor([[0.5153]], requires_grad=True)
tensor([[0.5891],
[1.6197],
[2.6502]], grad_fn=)
