使用 Dplyr 重新排序 R 中的数据帧列
在本文中,我们将讨论如何使用 R 编程语言中的 dplyr 包重新排列或重新排序数据帧的列。
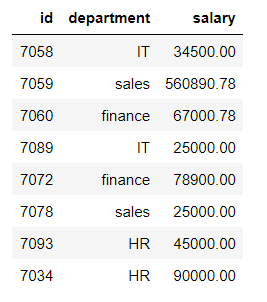
创建用于演示的数据框:
R
# load the package
library(dplyr)
# create the dataframe with three columns
# id , department and salary with 8 rows
data = data.frame(id = c(7058, 7059, 7060, 7089,
7072, 7078, 7093, 7034),
department = c('IT','sales','finance',
'IT','finance','sales',
'HR','HR'),
salary = c(34500.00, 560890.78, 67000.78,
25000.00, 78900.00, 25000.00,
45000.00, 90000))
# display dataframe
dataR
print("Before: ")
data
print("After: ")
# reorder the columns using select
select(data, salary, id, department)R
# display actual dataframe
print("actual dataframe")
print(data)
print("reorder the column with position")
# reorder the columns with column positions
# using select
print(select(data,3,1,2))R
print("Actual dataframe")
# display actual dataframe
print(data)
print("Reorder dataframe")
# rearrange the columns in alphabetic
# order
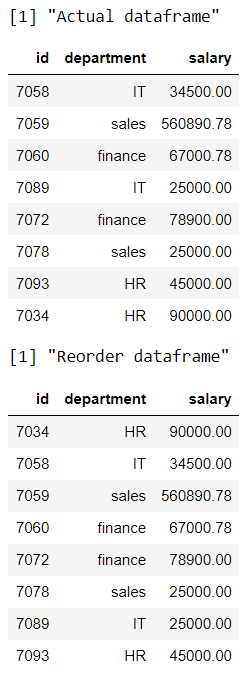
data %>% select(order(colnames(data)))R
print("Actual dataframe")
# display actual dataframe
print(data)
print("Reorder dataframe")
# rearrange the columns in reverse alphabetic order
data %>% select(order(colnames(data),
decreasing = TRUE))R
print("Actual dataframe")
# display actual dataframe
print(data)
print("Reorder dataframe")
# getting department column as first
data %>% select(department, everything())R
print("Actual dataframe")
# display actual dataframe
print(data)
print("Reorder dataframe")
# arrange the rows based on department column
data %>% arrange(department)R
print("Actual dataframe")
# display actual dataframe
print(data)
print("Reorder dataframe")
# arrange the rows based on salary
# column in descending order
data %>% arrange(desc(salary))R
print("Actual dataframe")
# display actual dataframe
data
print("Reorder dataframe")
# rearrange multiple columns
arrange_all(data)输出:
方法一:使用select()方法
我们将使用 select() 方法对列重新排序。
Syntax: select(dataframe,columns)
where
- dataframe is the input dataframe
- columns are the input columns to be reordered
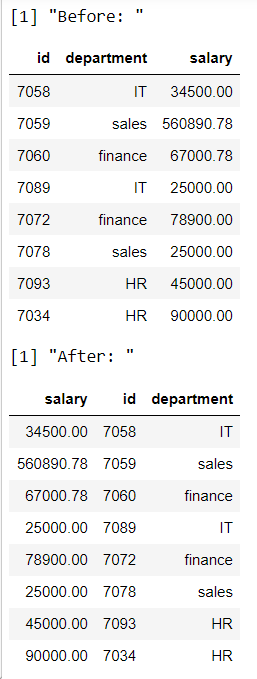
在这里,我们将数据框(id,department,salary)重新排列为(salary,id,department)
电阻
print("Before: ")
data
print("After: ")
# reorder the columns using select
select(data, salary, id, department)
输出:
方法二:按列位置重新排列数据框的列。
在这里,我们将使用列的索引/位置重新排列列。所以我们将使用 select 方法来做到这一点。
注意:列的索引/位置从 1 开始
Syntax: select(dataframe.index_positions)
Where,
- dataframe is the input dataframe
- index_positions are column positions to be rearranged
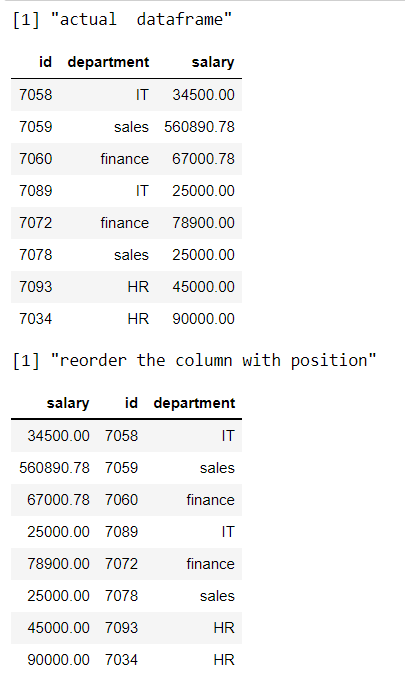
在这里,我们重新安排了不同的位置。
电阻
# display actual dataframe
print("actual dataframe")
print(data)
print("reorder the column with position")
# reorder the columns with column positions
# using select
print(select(data,3,1,2))
输出:
方法 3:按字母顺序重新排列或重新排列列名
这里我们使用 order()函数和 select()函数按字母顺序重新排列列。所以我们将使用 colnames函数对列进行排序。
Syntax: dataframe %>% select(order(colnames(dataframe)))
where,
- dataframe is the input dataframe
- %>% is the pipe operator to pass the result to the dataframe
- order() is used to rearrange the dataframe columns in alphabetical order
- colnames() is the function to get the columns in the dataframe
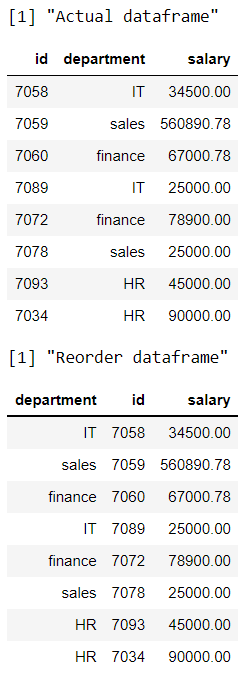
在这里,我们根据按字母顺序排列的列名重新排列数据。
电阻
print("Actual dataframe")
# display actual dataframe
print(data)
print("Reorder dataframe")
# rearrange the columns in alphabetic
# order
data %>% select(order(colnames(data)))
输出:
方法 4:按字母顺序相反的顺序重新排列或重新排列列名
所以我们将使用 colnames函数对列进行反向排序。
Syntax: dataframe %>% select(order(colnames(dataframe),decreasing=TRUE))
where,
- dataframe is the input dataframe
- %>% is the pipe operator to pass the result to the dataframe
- order() is used to rearrange the dataframe columns in alphabetical order
- colnames() is the function to get the columns in the dataframe
- decreasing=TRUE parameter specifies to sort the dataframe in descending order
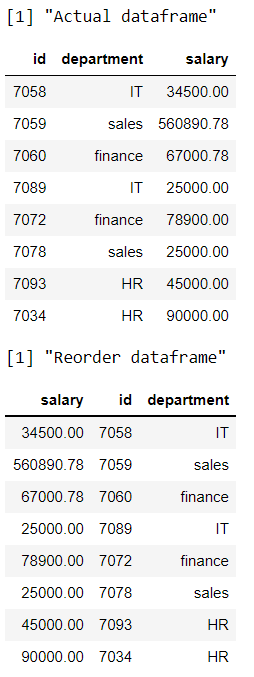
这里我们根据列名按字母顺序倒序重新排列数据。
电阻
print("Actual dataframe")
# display actual dataframe
print(data)
print("Reorder dataframe")
# rearrange the columns in reverse alphabetic order
data %>% select(order(colnames(data),
decreasing = TRUE))
输出:
方法 5:将列移动或移动到 R 中的第一个位置/最后一个位置
我们将使用everything() 方法将列移到第一个,这样我们就可以重新排列数据框。
Syntax: dataframe %>% select(column_name, everything())
where,
- dataframe is the input dataframe
- column_name is the column to be shifted first
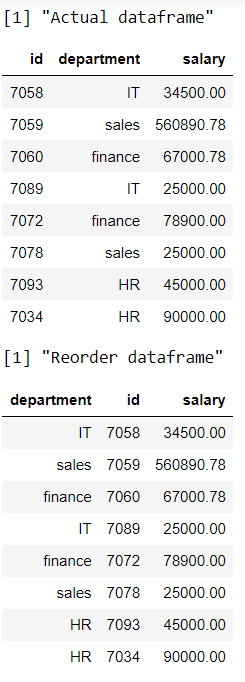
R程序首先将部门列转移
电阻
print("Actual dataframe")
# display actual dataframe
print(data)
print("Reorder dataframe")
# getting department column as first
data %>% select(department, everything())
输出:
方法 6:使用 dplyr 排列()
在这里,我们将使用排列()函数根据特定列按升序重新排列行
Syntax: dataframe %>% arrange(column_name)
Where
- dataframe is the input dataframe
- column_name is the column in which dataframe rows are arranged based on this column
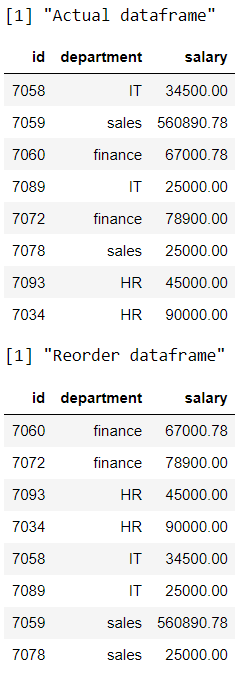
R程序根据部门列重新排列行
电阻
print("Actual dataframe")
# display actual dataframe
print(data)
print("Reorder dataframe")
# arrange the rows based on department column
data %>% arrange(department)
输出:
方法七:使用dplyr的arrange()和des()方法
在这里,我们将使用排列()函数和 desc()函数以升序重新排列基于特定列的行。
Syntax: dataframe %>% arrange(desc(column_name))
Where
- dataframe is the input dataframe
- column_name is the column in which dataframe rows are arranged based on this column in descending order
电阻
print("Actual dataframe")
# display actual dataframe
print(data)
print("Reorder dataframe")
# arrange the rows based on salary
# column in descending order
data %>% arrange(desc(salary))
输出:
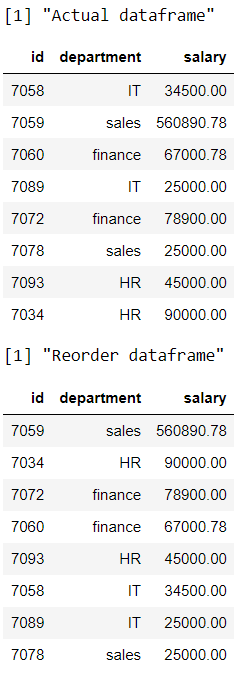
方法八:在R dplyr中使用arrange_all()函数
在这里,我们将根据数据框中的多个变量对行进行排列/重新排序,因此我们使用了arrange_all()函数
Syntax: arrange_all(dataframe)
电阻
print("Actual dataframe")
# display actual dataframe
data
print("Reorder dataframe")
# rearrange multiple columns
arrange_all(data)
输出: