扩张和全局滑动窗口注意
先决条件:注意力机制 | ML、滑动窗口注意、扩张的 CNN
为了执行各种 NLP 任务,已经使用了基于转换器的模型,例如 BERT、SpanBERT 等。然而,这些模型由于其自我注意机制而具有有限的能力。这些模型往往无法检测和读取包含长文本的数据。为此, 2020 年代后期出现了 Logformer (长文档转换器)。
日志生成器:
Longformer 架构具有自注意力组件,具有检测和读取大跨度文本数据的能力。然而,该模型仍然需要O(n 2 )时间来缩放输入并占用O(n)内存,这是非常低效的。 (如图 1 所示)这是引入了各种注意力模型以使过程高效的地方。滑动窗口注意力模型(如上一篇文章中所述)用于使处理方式高效。该模型有两种变体,本文将讨论这些变体。

图 1:全 0(n 2 ) 连接
滑动窗口注意:
滑动窗口是一种基于解析具有固定步长的 mxn图像以有效捕获目标图像的注意力模式。它用于提高 logformer 的效率。在比较滑动窗口注意力(图 2)模型和全连接模型(图 1)时,可以很容易地观察到这种方法比前者更有效。
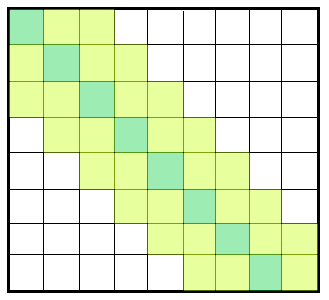
图 2:滑动窗口连接
有两种类型的滑动窗口注意力模型:
- 扩张的 SWA
- 全球SWA
膨胀滑动窗口注意:
滑动窗口的概念基于Dilated CNNs 的概念。滑动窗口算法之上的膨胀有助于更好地覆盖输入图像,同时保持与以前相同的计算成本。这个概念基于扩张率的变化以多种方式提供帮助。我们可以通过保持较低的膨胀率来解析小文本输入,从而承担最小的计算成本,并且可以通过增加此参数来遍历较大的输入文本。图 3描述了在引入 2 的扩张率时感受野的增加。(引入了 [n-1] 个间隙)
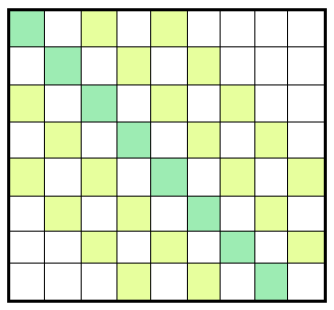
图 3:扩张的滑动窗口连接
全局滑动窗口注意:
这个注意力模型处理特定于任务的情况,我们必须从输入中检测特定的文本。这种注意力模型的对称特性有助于通过考虑输入中沿行/列的所有相应标记来查找特定序列,从而对这些细节给予全局关注。图 4显示了该模型如何在保持滑动窗口协议的同时处理此类外部情况。
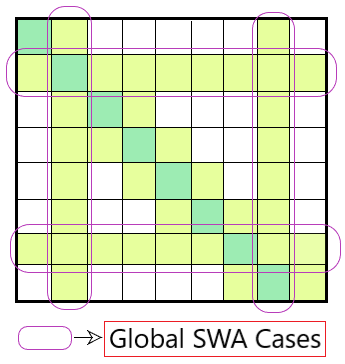
图 4:全局滑动窗口连接
上面讨论的注意力模型有助于提高 Logformer 的输出效率,使其成为 Transformer 的合适替代品。这些注意力模式在用于概率模型时也能提供更好的结果,例如自回归语言建模,其中将先前的单词作为输入来预测下一个单词序列。如有任何疑问/疑问,请在下方评论。