灰狼优化 – 介绍
优化基本上无处不在,从工程设计到经济,从假期计划到互联网路由。由于金钱、资源和时间总是有限的,因此对这些可用资源的最佳利用至关重要。
一般来说,优化问题可以写成
优化 ,
, 受制于,
 ,
, 
 , (
, (
其中f 1 , …, f N是目标,而h j 和g k分别是等式和不等式约束。在 N=1 的情况下,称为单目标优化。当 N≥2 时,它成为一个多目标优化问题,其求解策略与单目标不同。本文主要关注单目标优化问题。
不同类型的优化算法
确定性优化算法:
确定性方法利用问题的分析特性来生成收敛到全局最优解的一系列点。这些方法可以提供用于解决优化问题以获得全局或近似全局最优的通用工具。
例如:线性规划、非线性规划、混合整数非线性规划等。
启发式和元启发式:
元启发式算法是一种更高级别的程序或启发式算法,旨在查找、生成或选择可以为优化问题提供足够好的解决方案的启发式算法(部分搜索算法)。它们特别适用于不完整或不完善的信息可用或计算能力有限的情况。
元启发式对正在解决的优化问题做出相对较少的假设,因此可用于各种问题。
示例:粒子群优化 (PSO)、蚁群优化 (ACO)、遗传算法 (GA)、布谷鸟搜索算法、灰狼优化 (GWO) 等。
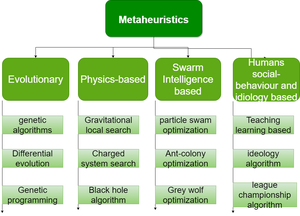
图 1:元启发式算法的分类以及每个类的示例
本文旨在介绍一种称为灰狼优化 (GWO) 的新型元启发式算法的基础知识
算法的灵感
灰狼优化器(GWO)是一种基于种群的元启发式算法,它模拟自然界中灰狼的领导层级和狩猎机制,由 Seyedali Mirjalili 等人提出。在 2014 年。
- 灰狼被认为是处于食物链顶端的顶级掠食者
- 灰狼喜欢群居(群居),每群平均有5-12只。
- 如附图所示,该组中的所有个人都具有非常严格的社会支配地位等级。
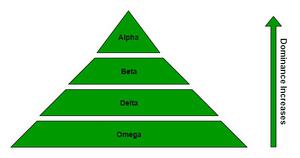
图 2:灰狼的社会等级
- 阿尔法α狼被认为是狼群中的主导狼,狼群成员应遵守他/她的命令。
- Beta β是从属狼,帮助 alpha 进行决策,被认为是 alpha 的最佳人选。
- Delta δ狼必须服从 alpha 和 beta,但它们主宰了 omega。有不同类别的类似三角洲的侦察兵、哨兵、长老、猎人、看守者等。
- 欧米茄ω狼被认为是群体中的替罪羊,是群体中最不重要的个体,最后才被允许进食。
灰狼狩猎的主要阶段:
- 跟踪、追逐和接近猎物。
- 追逐、包围和骚扰猎物,直到它停止移动。
- 向猎物进攻。
灰狼的社会等级和狩猎行为被数学建模以设计 GWO。
数学模型和算法:
社会等级:
- 作为阿尔法狼的最适解决方案 ( α)
- 作为 Beta 狼 ( β) 的次佳解决方案
- 作为 Delta wolf ( δ) 的第三个最佳解决方案
- 其余候选解为 Omega wolves (ω)
包围猎物:
 (1)
(1)
 (2)
(2)
其中 t 表示当前迭代,  和
和是系数向量,
 是猎物的位置向量,和
是猎物的位置向量,和 表示灰狼的位置向量。
表示灰狼的位置向量。 
和
(3)
的组成部分 在迭代过程中从 2 线性减少到 0 并且
在迭代过程中从 2 线性减少到 0 并且 ,
 是 [0, 1] 中的随机向量。
是 [0, 1] 中的随机向量。
打猎:
在每次迭代中,omega 狼都会根据位置 α、β 和 δ α、β 和 δ 更新它们的位置,因为 α、β 和 δ 对猎物的潜在位置有更好的了解。
 ,
, ,
 (4)
(4)
 ,
,  ,
,  (5)
(5)
 (6)
(6)
攻击猎物(剥削):
当猎物停止移动时,灰狼通过攻击猎物来完成狩猎,并在数学上建模我们降低了 .
.  是区间 [-2a, 2a] 中的随机值,其中 a 在迭代过程中从 2 减少到 0。
是区间 [-2a, 2a] 中的随机值,其中 a 在迭代过程中从 2 减少到 0。
|A|<1 迫使狼群攻击猎物(剥削)
寻找猎物(探索):
|A|>1 迫使灰狼与猎物分道扬镳,希望能找到更合适的猎物(剥削)
GWO 的另一个有利于探索的组成部分是 .它包含 [0, 2] 之间的随机值。 C>1 强调攻击,而 C<1 不强调攻击。
GWO算法的伪代码:
- Step1:随机初始化灰狼种群X i (i=1,2,…,n)
- Step2:初始化a=2、A和C的值(使用eq.3)
- Step3:计算种群中每个成员的适应度
- X α = 具有最佳适应值的成员
- X β =第二好的成员(就适应度值而言)
- X δ =第三好的成员(就适应值而言)
- Step4: FOR t = 1 to Max_number_of_iterations:
- 通过方程更新所有欧米茄狼的位置。 4、5 和 6
- 更新 a、A、C(使用等式 3)
- a = 2(1-t/T)
- 计算所有搜索代理的适应度
- 更新 Xα、Xβ、Xδ。
- 结束于
- Step5:返回X α
参考:
- https://www.sciencedirect.com/science/article/pii/S0965997813001853
- https://www.slideshare.net/afar1111/grey-wolf-optimizer