R 编程中的图形绘制
在解释世界及其每天产生的大量数据时,数据可视化成为最理想的方式。与其筛选巨大的 Excel 表格,不如通过图表和图形可视化这些数据,以获得有意义的见解。
R - 绘图
R 编程语言提供了一些简单快捷的工具,可让我们将数据转换为图形等具有视觉洞察力的元素。
R中的绘图有两种类型:
- 一维绘图:在一维绘图中,我们一次绘制一个变量。例如,我们可以绘制一个变量,其中每个值在整个数据集中出现的次数(频率)。因此,它不与数据集的任何其他变量进行比较。这些是用于一维分析的 4 种主要类型的图表 -
- 五点总结
- 箱形图
- 直方图
- 条形图
- 二维绘图:在二维绘图中,我们可视化并比较一个变量与另一个变量。例如,在空气质量测量数据集中,我们想比较 AQI 如何随特定地点的温度变化。因此,温度和 AQI 是两个不同的变量,我们希望看到一个变量相对于另一个变量的变化。这些是用于此类分析的 3 种主要图表 -
- 箱形图
- 直方图
- 散点图
出于本文的目的,我们将使用 RStudio 提供的默认数据集 (mtcars)。
加载数据
打开 RStudio(或 R 终端)并开始加载数据集。在控制台中键入这些命令。这是一种加载 R 提供的默认数据集的方法。(也可以下载和使用任何其他数据集)
R
library(datasets)
data(mtcars)R
head(mtcars)R
summary(mtcars)R
boxplot(mtcars$mpg, col="green")R
hist(mtcars$mpg, col = "green") ## Plot 1
hist(mtcars$mpg, col = "green", breaks = 25) ## Plot 2
hist(mtcars$mpg, col = "green", breaks = 50) ## Plot 3R
barplot(table(mtcars$carb), col="green")R
boxplot(mpg~gear, data=mtcars, col = "green")R
hist(subset(mtcars, cyl == 4)$mpg, col = "green") ## Plot 1
hist(subset(mtcars, cyl == 8)$mpg, col = "green") ## Plot 2R
with(mtcars, plot(mpg, qsec))要检查数据是否正确加载,我们在控制台上运行以下命令:
R
head(mtcars)
输出:

通过运行此命令,我们还可以了解数据集包含哪些列。在这种情况下,数据集 mtcars 包含 11 列,即 - mpg、cyl、disp、hp、drat、wt、qsec、vs、am、gear 和 carb。请注意,行数比此处显示的要多。 head()函数仅显示数据集的前 6 行。
一维绘图
在一维绘图中,我们基本上一次绘制一个变量。因此,它不与数据集的任何其他变量进行比较。相反,只关注其统计推断的特征。
五点总结
要引用 R 中的特定列名,我们使用“$”符号。例如,如果我们要引用 mtcars 数据集中的“gear”列,我们将其称为 - mtcars$gear。因此,对于数据集的任何特定列,我们可以使用summary()函数生成五点摘要。我们只需将列名(使用 $ 符号表示)作为参数传递给此函数,如下所示:
R
summary(mtcars)
输出:

此摘要列出了特定列的平均值、中值、最小值、最大值和象限值等特征。
箱形图
箱线图生成一个矩形,该矩形覆盖了数据集列所跨越的区域。它可以按如下方式生产:
R
boxplot(mtcars$mpg, col="green")
输出:
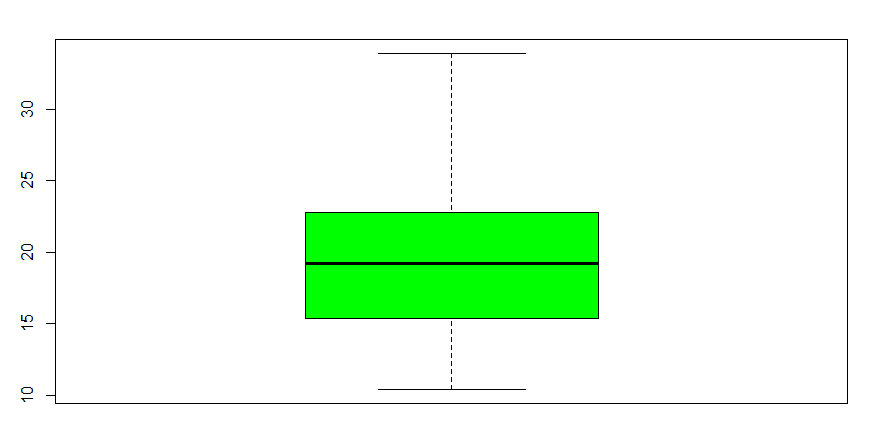
请注意,矩形中的粗线描绘了 mpg 列的中值,即五点摘要中所见的 19.20。 col=”green”只是将绘图着色为绿色。
直方图
直方图是用于分析数据集的最广泛使用的图。以下是我们如何绘制将变量(列名)映射到其频率的直方图:
R
hist(mtcars$mpg, col = "green") ## Plot 1
hist(mtcars$mpg, col = "green", breaks = 25) ## Plot 2
hist(mtcars$mpg, col = "green", breaks = 50) ## Plot 3
'breaks' 参数本质上改变了直方图条的宽度。可以看出,随着我们增加中断值,条形变细。
输出:

条形图
在条形图中,我们得到变量(列)中每个值的离散值频率映射。例如:
R
barplot(table(mtcars$carb), col="green")
输出:
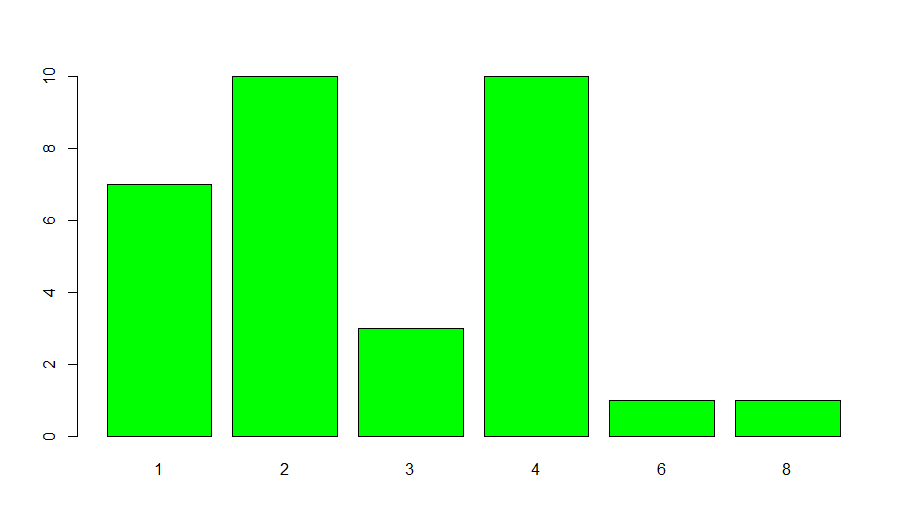
我们看到“carb”列包含 6 个离散值(在其所有行中)。上面的条形图将这 6 个值映射到它们的频率(它们出现的次数)。
二维绘图
在二维绘图中,我们可视化并比较一个变量与另一个变量。
箱形图
假设我们希望根据每辆车的档位数生成多个箱线图。因此,我们希望拥有的箱线图的数量等于“齿轮”列中离散值的数量,即齿轮的每个值对应一个图。这可以通过以下方式实现 -
R
boxplot(mpg~gear, data=mtcars, col = "green")
输出:
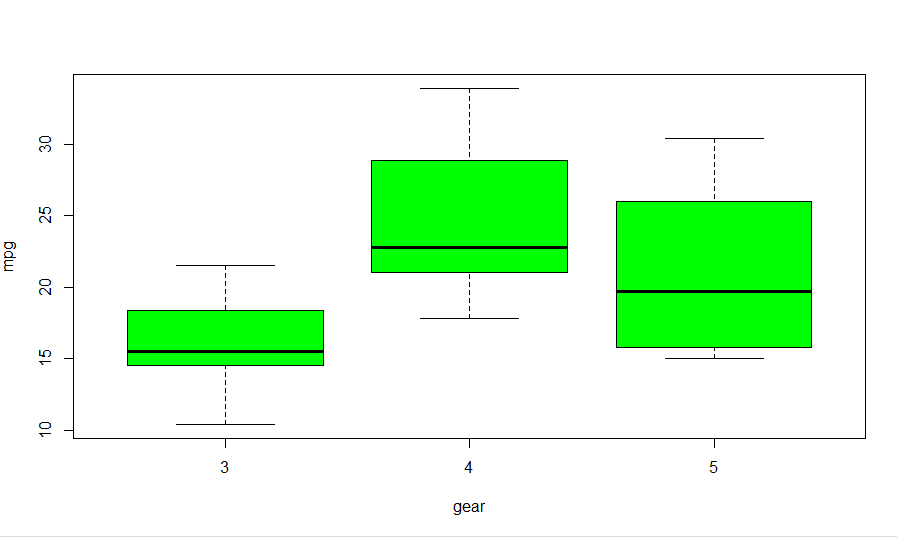
我们看到“齿轮”列中有 3 个齿轮值。因此,绘制了 3 个不同的箱线图,每个齿轮一个。
直方图
现在假设,我们希望为有 4 个汽缸的汽车和有 8 个汽缸的汽车创建单独的直方图。为此,我们对数据集进行了子集化,使得子集数据仅包含具有 4(或 8)个气缸的汽车的数据。然后,我们可以像以前一样使用 hist()函数轻松绘制子集数据。我们可以这样实现:
R
hist(subset(mtcars, cyl == 4)$mpg, col = "green") ## Plot 1
hist(subset(mtcars, cyl == 8)$mpg, col = "green") ## Plot 2

散点图
散点图用于在 x 轴和 y 轴上绘制两个变量的数据点。它们告诉我们数据中的模式,并广泛用于建模 ML 算法。在这里,我们散点图列 qsec 相对于列 mpg。
R
with(mtcars, plot(mpg, qsec))
输出:
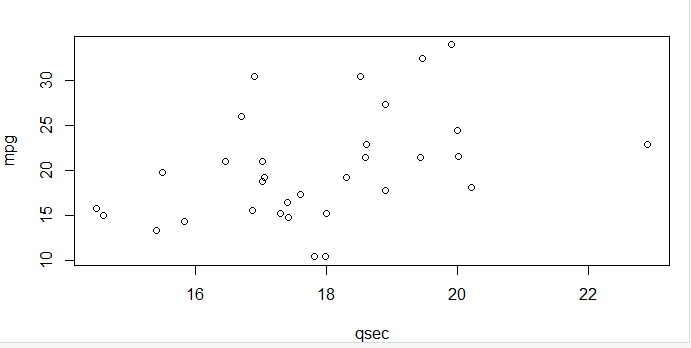
然而,上面的图并没有真正向我们展示数据中的任何模式。这是因为我们在数据集中拥有的行(样本)数量有限。当我们从外部资源获取数据时,它通常至少有 1000+ 行。在散点图上绘制如此广泛的数据集,我们为真正有趣的观察和见解铺平了道路。