- 差异度量和分析(1)
- 差异度量和分析
- 软件度量验证(1)
- 软件度量验证
- 软件度量标准(1)
- 软件度量标准
- 软件测量和度量
- 软件测量和度量(1)
- 软件质量中的目标问题度量方法
- 软件质量中的目标问题度量方法(1)
- 软件工程|软件度量的案例工具(1)
- 软件工程|软件度量的案例工具
- 软件和数据的区别
- 软件分析和设计工具(1)
- 软件分析和设计工具
- CSS-度量单位(1)
- CSS-度量单位
- 算法分析|大O分析(1)
- 算法分析|大O分析
- 算法分析|大O分析
- 软件组成分析概述(1)
- 软件组成分析概述
- 大数据中的实时分析(1)
- 大数据中的实时分析
- 大数据实时分析
- Python|字符串的相似度度量(1)
- Python|字符串的相似度度量
- 软件
- 软件(1)
📅 最后修改于: 2020-12-04 08:01:46 🧑 作者: Mango
收集相关数据后,我们必须以适当的方式对其进行分析。选择分析技术时要考虑三个主要项目。
- 数据的性质
- 实验目的
- 设计注意事项
数据的本质
要分析数据,我们还必须查看由数据代表的较大人群以及该数据的分布。
抽样,总体和数据分配
抽样是从大量人口中选择一组数据的过程。样本统计数据描述和总结了从一组实验对象中获得的度量。
人口参数表示如果测量了所有可能的受试者将获得的值。
总体或样本可以通过集中趋势的度量(例如均值,中位数和众数)以及离散程度(例如方差和标准偏差)来描述。如下图所示,正常分布了许多数据集。
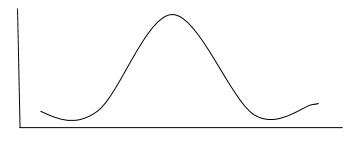
如上所示,数据将围绕均值均匀分布。这是正态分布的显着特征。
在数据偏斜的地方也存在其他分布,因此均值一侧的数据点多于另一侧。例如:如果大多数数据位于均值的左侧,则可以说分布偏向左侧。
实验目的
通常情况下,进行实验-
- 确认理论
- 探索关系
为了实现这些目标,应该以假设形式正式表达目标,并且分析必须直接解决假设。
确认理论
必须将调查设计为探索理论的真相。该理论通常指出,使用某种方法,工具或技术会对受试者产生特殊影响,使其在某种程度上比另一种更好。
有两种情况需要考虑的数据:正常数据和非正常数据。
如果数据来自正态分布,并且有两组要进行比较,则可以使用学生的t检验进行分析。如果要比较的组多于两个,则可以使用称为F统计量的方差检验的一般分析。
如果数据不正常,则可以使用Kruskal-Wallis检验对数据进行排名来对其进行分析。
探索关系
研究旨在确定描述一个或多个变量的数据点之间的关系。
有三种技术可以回答有关关系的问题:箱形图,散点图和相关性分析。
-
箱形图可以表示一组数据范围的摘要。
-
散点图表示两个变量之间的关系。
-
相关分析使用统计方法来确认两个属性之间是否存在真实关系。
-
对于正态分布的值,请使用Pearson相关系数来检查两个变量是否高度相关。
-
对于非正常数据,请对数据进行排名,并使用Spearman排名相关系数作为关联的度量。针对非正常数据的另一种度量是Kendall鲁棒相关系数,它研究了成对的数据点之间的关系并可以识别出部分相关。
-
如果该排名包含大量绑定值,则可以使用列联表上的卡方检验来测试变量之间的关联。类似地,线性回归可用于生成方程来描述变量之间的关系。
对于两个以上的变量,可以使用多元回归。
设计注意事项
选择分析技术时,必须考虑调查的设计。同时,分析的复杂性会影响所选的设计。多个组使用F统计量,而不是使用两组的Student T检验。
对于具有两个以上因素的复杂因子设计,需要进行更复杂的关联和重要性测试。
统计技术可用于说明一组变量对其他变量的影响,或补偿时间安排或学习效果。