分析:
元素可以向上移动的最大电平为Θ(log n)电平。在每个级别,我们都对O(1)进行简单比较。因此,heapify的总时间为O(log n)。
构建堆:
堆排序算法:
分析:构建最大堆需要O(n)运行时间。堆排序算法调用“ Build Max-Heap”(构建最大堆),这需要O(n)次时间,而每个(n-1)个调用都将调用Max-heap来修复新堆。我们知道“ Max-Heapify”需要时间O(log n)
堆排序的总运行时间为O(n log n)。
示例:说明阵列上BUILD-MAX-HEAP的操作。
A = (5, 3, 17, 10, 84, 19, 6, 22, 9)
解决方案:最初:
Heap-Size (A) =9, so first we call MAX-HEAPIFY (A, 4)
And I = 4.5= 4 to 1

After MAX-HEAPIFY (A, 4) and i=4
L ← 8, r ← 9
l≤ heap-size[A] and A [l] >A [i]
8 ≤9 and 22>10
Then Largest ← 8
If r≤ heap-size [A] and A [r] > A [largest]
9≤9 and 9>22
If largest (8) ≠4
Then exchange A [4] ←→ A [8]
MAX-HEAPIFY (A, 8)

After MAX-HEAPIFY (A, 3) and i=3
l← 6, r ← 7
l≤ heap-size[A] and A [l] >A [i]
6≤ 9 and 19>17
Largest ← 6
If r≤ heap-size [A] and A [r] > A [largest]
7≤9 and 6>19
If largest (6) ≠3
Then Exchange A [3] ←→ A [6]
MAX-HEAPIFY (A, 6)
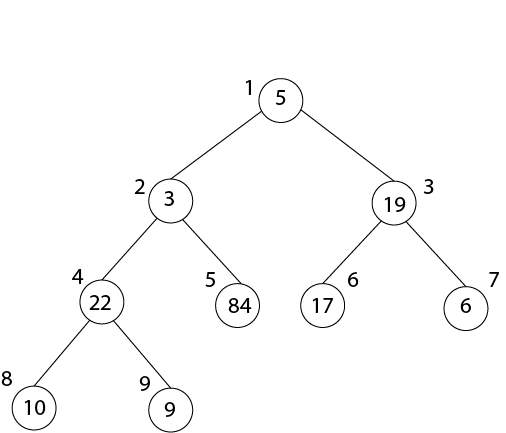
After MAX-HEAPIFY (A, 2) and i=2
l ← 4, r ← 5
l≤ heap-size[A] and A [l] >A [i]
4≤9 and 22>3
Largest ← 4
If r≤ heap-size [A] and A [r] > A [largest]
5≤9 and 84>22
Largest ← 5
If largest (4) ≠2
Then Exchange A [2] ←→ A [5]
MAX-HEAPIFY (A, 5)

After MAX-HEAPIFY (A, 1) and i=1
l ← 2, r ← 3
l≤ heap-size[A] and A [l] >A [i]
2≤9 and 84>5
Largest ← 2
If r≤ heap-size [A] and A [r] > A [largest]
3≤9 and 19<84
If largest (2) ≠1
Then Exchange A [1] ←→ A [2]
MAX-HEAPIFY (A, 2)

优先队列:
与堆一样,优先级队列以两种形式出现:max-priority队列和min-priority队列。
优先级队列是一种数据结构,用于维护元素S的集合,每个元素具有称为键的组合值。最大优先级队列指导以下操作:
INSERT(S,x):将元素x插入到集合S中,与操作S =S∪[x]成比例。
MAXIMUM(S)返回具有最高键的S元素。
EXTRACT-MAX(S)删除并返回具有最高键的S元素。
INCREASE-KEY(S,x,k)将元素x的键值增加到新值k,该值至少与x的当前键值一样大。
让我们讨论如何实现最大优先级队列的操作。过程HEAP-MAXIMUM考虑θ(1)时间的MAXIMUM操作。
最大堆(A)
1.返回A [1]
过程HEAP-EXTRACT-MAX实现EXTRACT-MAX操作。它类似于Heap-Sort过程的for循环。
过程HEAP-INCREASE-KEY实现了INCREASE-KEY操作。数组中的索引i标识了我们希望增加其键的优先级队列元素。
HEAP-INCREASE-KEY在n元素堆上的运行时间为O(日志n),因为从第3行中更新的节点到根的跟踪路径的长度为O(log n)。
MAX-HEAP-INSERT过程实现INSERT操作。它以要插入到最大堆A中的新项目的键作为输入。该过程首先通过将键为-∞的新叶计算到树上来扩展最大堆。然后,它调用HEAP-INCREASE-KEY将此新节点的密钥设置为正确的值并维护max-heap属性
在n元素堆上MAX-HEAP-INSERT的运行时间为O(log n)。
示例:说明堆上的HEAP-EXTRACT-MAX的操作
A= (15,13,9,5,12,8,7,4,0,6,2,1)
图: HEAP-INCREASE-KEY的操作

无花果(a)
在该图中,索引为“ i”的节点的最大堆阴影很大

无花果(b)
在此图中,此节点的密钥已增加到15。

无花果(c)
在第4-6行的while循环的一次迭代之后,该节点及其父节点交换了密钥,索引i移至父节点。

无花果(d)
经过while循环再迭代一次后,最大堆,最大堆属性A [PARENT(i)≥A(i)]成立,过程终止。
堆删除:
堆删除(A,i)是从堆A中删除节点“ i”中的项的过程,堆HEAP-DELETE的运行时间为O(log n),n元素最大堆。



