- R时间序列分析(1)
- R中的时间序列分析
- R-时间序列分析
- R时间序列分析
- R中的时间序列分析(1)
- R-时间序列分析(1)
- AI均值端分析
- 大数据分析-时间序列分析(1)
- 大数据分析-时间序列分析
- 时间序列Python库(1)
- 时间序列Python库
- Python时间序列(1)
- Python时间序列
- ai (1)
- 在Python中处理时间序列数据(1)
- 在Python中处理时间序列数据
- 排序列数据框 - Python (1)
- 带Python的AI –数据准备
- Python的时间序列数据可视化(1)
- Python的时间序列数据可视化
- 排序列数据框 - Python 代码示例
- ai - 任何代码示例
- 如何在 pandas 中使用时间序列?(1)
- 如何在 pandas 中使用时间序列?
- 用Python讨论AI
- 用Python讨论AI(1)
- 从字符串到时间 python 数据框 - Python (1)
- 在 R 编程中使用 ARIMA 模型进行时间序列分析(1)
- 在 R 编程中使用 ARIMA 模型进行时间序列分析
📅 最后修改于: 2020-12-11 05:41:48 🧑 作者: Mango
预测给定输入序列中的下一个是机器学习中的另一个重要概念。本章为您提供有关分析时间序列数据的详细说明。
介绍
时间序列数据是指一系列特定时间间隔中的数据。如果我们想在机器学习中建立序列预测,那么我们必须处理顺序数据和时间。系列数据是顺序数据的抽象。数据排序是顺序数据的重要特征。
序列分析或时间序列分析的基本概念
序列分析或时间序列分析是基于先前观察到的预测给定输入序列中的下一个序列。预测可以是接下来可能发生的任何事情:符号,数字,第二天的天气,下一个言语等。序列分析在诸如股票市场分析,天气预报和产品推荐之类的应用中非常方便。
例
考虑以下示例以了解序列预测。在这里, A,B,C,D是给定的值,您必须使用序列预测模型来预测值E。

安装有用的软件包
对于使用Python进行时间序列数据分析,我们需要安装以下软件包-
大熊猫
Pandas是BSD许可的开源库,它为Python提供了高性能,易于使用的数据结构和数据分析工具。您可以在以下命令的帮助下安装Pandas-
pip install pandas
如果您正在使用Anaconda并想使用conda软件包管理器进行安装,则可以使用以下命令-
conda install -c anaconda pandas
学习
它是一个开源的BSD许可库,由简单的算法和模型组成,以学习Python的隐马尔可夫模型(HMM)。您可以在以下命令的帮助下安装它-
pip install hmmlearn
如果您正在使用Anaconda并想使用conda软件包管理器进行安装,则可以使用以下命令-
conda install -c omnia hmmlearn
PyStruct
它是一个结构化的学习和预测库。在PyStruct中实现的学习算法的名称包括条件随机字段(CRF),最大边距马尔可夫随机网络(M3N)或结构支持向量机。您可以在以下命令的帮助下安装它-
pip install pystruct
CVXOPT
它用于基于Python编程语言的凸优化。它也是一个免费软件包。您可以在以下命令的帮助下安装它-
pip install cvxopt
如果您正在使用Anaconda并想使用conda软件包管理器进行安装,则可以使用以下命令-
conda install -c anaconda cvdoxt
熊猫:从时间序列数据中处理,切片和提取统计信息
如果必须使用时间序列数据,Pandas是非常有用的工具。借助Pandas,您可以执行以下操作-
-
通过使用pd.date_range包创建日期范围
-
通过使用pd.Series包为熊猫索引日期
-
使用ts.resample包执行重新采样
-
改变频率
例
以下示例显示了使用Pandas处理和切片时间序列数据的方法。请注意,这里我们使用的是每月北极涛动数据,该数据可以从monthly.ao.index.b50.current.ascii下载,并可以转换为文本格式供我们使用。
处理时间序列数据
为了处理时间序列数据,您将必须执行以下步骤-
第一步涉及导入以下软件包-
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
接下来,定义一个将从输入文件中读取数据的函数,如下面的代码所示-
def read_data(input_file):
input_data = np.loadtxt(input_file, delimiter = None)
现在,将此数据转换为时间序列。为此,请创建我们时间序列的日期范围。在此示例中,我们将一个月作为数据频率。我们的文件包含的数据始于1950年1月。
dates = pd.date_range('1950-01', periods = input_data.shape[0], freq = 'M')
在此步骤中,我们借助Pandas Series创建时间序列数据,如下所示-
output = pd.Series(input_data[:, index], index = dates)
return output
if __name__=='__main__':
输入输入文件的路径,如下所示-
input_file = "/Users/admin/AO.txt"
现在,将列转换为时间序列格式,如下所示:
timeseries = read_data(input_file)
最后,使用所示命令绘制并可视化数据-
plt.figure()
timeseries.plot()
plt.show()
您将观察到如下图所示的图-
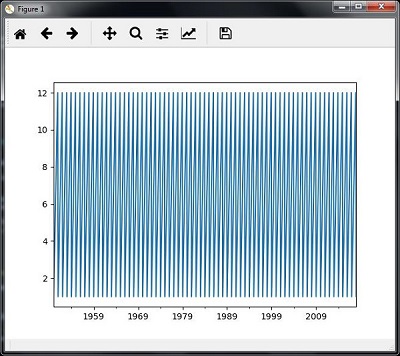
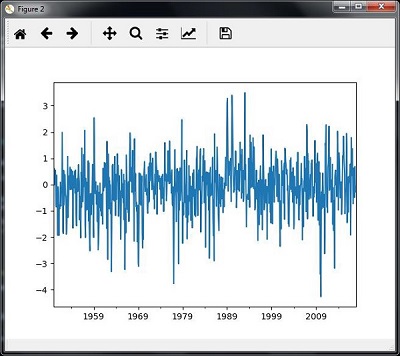
切片时间序列数据
切片涉及仅检索时间序列数据的一部分。作为示例的一部分,我们仅对1980年至1990年的数据进行切片。请观察执行此任务的以下代码-
timeseries['1980':'1990'].plot()
plt.show()
当您运行用于对时间序列数据进行切片的代码时,您可以观察到以下图形,如此处的图像所示:
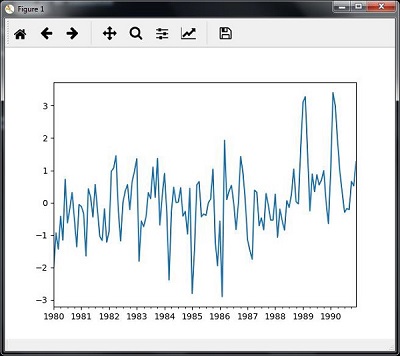
从时间序列数据中提取统计信息
如果需要得出一些重要的结论,则必须从给定的数据中提取一些统计信息。均值,方差,相关性,最大值和最小值就是这样的统计信息。如果要从给定的时间序列数据中提取此类统计信息,则可以使用以下代码-
意思
您可以使用mean()函数来查找均值,如下所示:
timeseries.mean()
那么您将在讨论的示例中观察到的输出是-
-0.11143128165238671
最大值
您可以使用max()函数来查找最大值,如下所示:
timeseries.max()
那么您将在讨论的示例中观察到的输出是-
3.4952999999999999
最低要求
您可以使用min()函数来查找最小值,如下所示:
timeseries.min()
那么您将在讨论的示例中观察到的输出是-
-4.2656999999999998
一次获取所有内容
如果您想一次计算所有统计信息,则可以使用describe()函数,如下所示:
timeseries.describe()
那么您将在讨论的示例中观察到的输出是-
count 817.000000
mean -0.111431
std 1.003151
min -4.265700
25% -0.649430
50% -0.042744
75% 0.475720
max 3.495300
dtype: float64
重采样
您可以将数据重新采样为其他时间频率。用于执行重采样的两个参数是-
- 时间段
- 方法
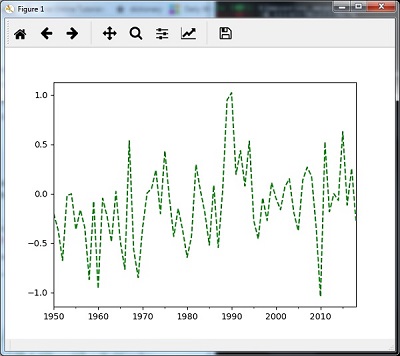
用mean()重新采样
您可以使用以下代码通过mean()方法对数据进行重新采样,这是默认方法-
timeseries_mm = timeseries.resample("A").mean()
timeseries_mm.plot(style = 'g--')
plt.show()
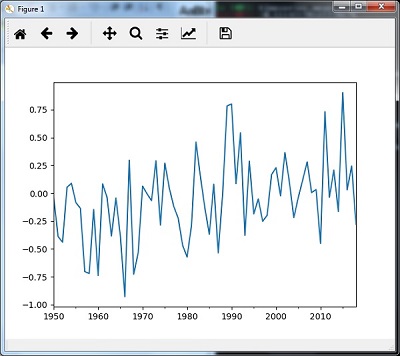
然后,您可以观察下图作为使用mean()重采样的输出-
用中位数()重新采样
您可以使用以下代码通过中位数()方法对数据进行重新采样-
timeseries_mm = timeseries.resample("A").median()
timeseries_mm.plot()
plt.show()
然后,您可以观察到以下图表,作为使用mean()进行重新采样的输出-
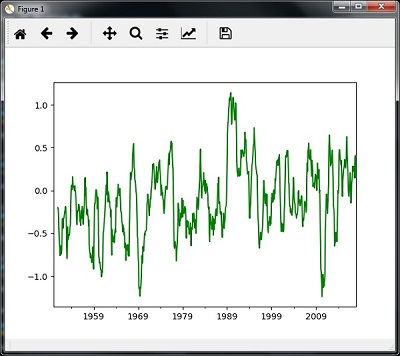
滚动平均值
您可以使用以下代码来计算滚动(移动)均值-
timeseries.rolling(window = 12, center = False).mean().plot(style = '-g')
plt.show()
然后,您可以观察下图作为滚动(移动)平均值的输出:
通过隐马尔可夫模型(HMM)分析顺序数据
HMM是一种统计模型,广泛用于具有连续性和可扩展性的数据,例如时间序列股票市场分析,健康状况检查和语音识别。本节详细介绍使用隐马尔可夫模型(HMM)分析顺序数据。
隐马尔可夫模型(HMM)
HMM是一种基于马尔可夫链概念的随机模型,该模型基于以下假设:未来统计信息的概率仅取决于当前流程状态,而不取决于其之前的任何状态。例如,抛硬币时,我们不能说第五次抛的结果是正面。这是因为硬币没有任何记忆,下一个结果不取决于前一个结果。
从数学上讲,HMM由以下变量组成-
州(S)
它是HMM中存在的一组隐藏或潜在状态。用S表示。
输出符号(O)
它是HMM中存在的一组可能的输出符号。用O表示。
状态转移概率矩阵(A)
这是从一个状态过渡到其他状态的概率。用A表示。
观测排放概率矩阵(B)
它是在特定状态下发射/观察符号的概率。用B表示。
先验概率矩阵(Î)
它是从系统的各种状态开始于特定状态的概率。用表示。
因此,HMM可以定义为ð€=(S,O,A,B,ð…) ,
哪里,
- S = {s 1 ,s 2 ,…,s N }是N个可能状态的集合,
- O = {o 1 ,o 2 ,…,o M }是M个可能的观测符号的集合,
- A是Nð’™N状态转移概率矩阵(TPM),
- B是Nð’™M观测或发射概率矩阵(EPM),
- 是N维初始状态概率分布向量。
示例:股票市场数据分析
在此示例中,我们将逐步分析股票市场数据,以了解HMM如何处理顺序数据或时间序列数据。请注意,我们正在Python中实现此示例。
导入必要的软件包,如下所示:
import datetime
import warnings
现在,使用matpotlib.finance包中的股市数据,如下所示-
import numpy as np
from matplotlib import cm, pyplot as plt
from matplotlib.dates import YearLocator, MonthLocator
try:
from matplotlib.finance import quotes_historical_yahoo_och1
except ImportError:
from matplotlib.finance import (
quotes_historical_yahoo as quotes_historical_yahoo_och1)
from hmmlearn.hmm import GaussianHMM
从开始日期和结束日期(即两个特定日期之间)加载数据,如下所示-
start_date = datetime.date(1995, 10, 10)
end_date = datetime.date(2015, 4, 25)
quotes = quotes_historical_yahoo_och1('INTC', start_date, end_date)
在这一步中,我们将每天提取结束报价。为此,请使用以下命令-
closing_quotes = np.array([quote[2] for quote in quotes])
现在,我们将提取每天交易的股票数量。为此,请使用以下命令-
volumes = np.array([quote[5] for quote in quotes])[1:]
在这里,使用下面显示的代码来计算收盘价的百分比差-
diff_percentages = 100.0 * np.diff(closing_quotes) / closing_quotes[:-]
dates = np.array([quote[0] for quote in quotes], dtype = np.int)[1:]
training_data = np.column_stack([diff_percentages, volumes])
在此步骤中,创建并训练高斯HMM。为此,请使用以下代码-
hmm = GaussianHMM(n_components = 7, covariance_type = 'diag', n_iter = 1000)
with warnings.catch_warnings():
warnings.simplefilter('ignore')
hmm.fit(training_data)
现在,使用所示的命令,使用HMM模型生成数据-
num_samples = 300
samples, _ = hmm.sample(num_samples)
最后,在此步骤中,我们以图表形式绘制并可视化作为输出的交易股票的差异百分比和数量。
使用以下代码来绘制和可视化差异百分比-
plt.figure()
plt.title('Difference percentages')
plt.plot(np.arange(num_samples), samples[:, 0], c = 'black')
使用以下代码来绘制和可视化交易的股票数量-
plt.figure()
plt.title('Volume of shares')
plt.plot(np.arange(num_samples), samples[:, 1], c = 'black')
plt.ylim(ymin = 0)
plt.show()