- 数据仓库教程
- 数据仓库教程
- 数据仓库教程(1)
- 数据仓库 (1)
- 数据仓库
- 数据仓库(1)
- 数据仓库
- 运营数据库与数据仓库数据仓库教程
- 运营数据库与数据仓库数据仓库教程(1)
- 数据仓库的属性
- 数据仓库的属性
- 数据仓库的属性(1)
- 数据仓库 - 任何代码示例
- 数据仓库中的实现和组件(1)
- 数据仓库中的实现和组件
- 数据仓库中的实现和组件(1)
- 数据仓库中的实现和组件
- 数据仓库的类型
- 数据仓库的类型(1)
- 在数据仓库中测试
- 数据仓库-测试(1)
- 在数据仓库中测试(1)
- 数据仓库-测试
- 数据仓库-模式(1)
- 数据仓库-模式
- 数据仓库-面试问题
- 数据仓库-面试问题(1)
- 数据仓库实现
- 数据仓库实现(1)
📅 最后修改于: 2020-12-30 00:30:09 🧑 作者: Mango
数据仓库的组件或构建块
建筑是元素的正确布置。我们建立一个包含软件和硬件组件的数据仓库。为了适应我们组织的要求,我们安排了这些建筑,我们可能希望通过额外的工具和服务来提高其他水平。所有这些都取决于我们的情况。
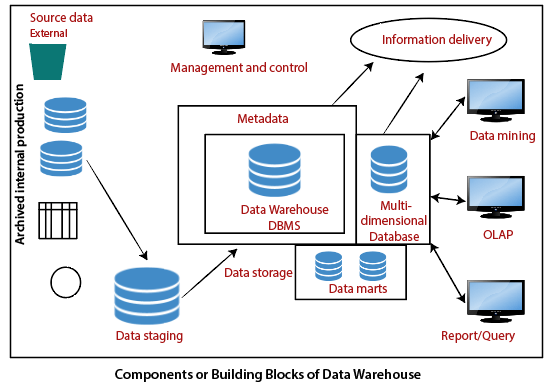
该图显示了典型仓库的基本要素。我们看到“源数据”组件显示在左侧。数据登台元素用作下一个构建块。在中间,我们看到了处理数据仓库数据的数据存储组件。该元素不仅存储和管理数据,而且还存储和管理数据。它还使用元数据存储库跟踪数据。右侧显示的“信息传递”组件包括使数据仓库中的信息可供用户使用的所有不同方式。
源数据组件
进入数据仓库的源数据可以分为四大类:
生产数据:此类数据来自企业的不同操作系统。根据数据仓库中的数据需求,我们从各种操作模式中选择数据段。
内部数据:在每个组织中,客户都保留其“私有”电子表格,报告,客户资料,有时甚至是部门数据库。这是内部数据,其中一部分可能在数据仓库中很有用。
存档数据:操作系统主要用于运行当前业务。在每个操作系统中,我们会定期获取旧数据并将其存储在已实现的文件中。
外部数据:大多数高管依赖于外部来源的信息来使用大部分信息。他们使用与外部部门关联的与其行业相关的统计信息。
数据登台组件
从各种操作系统和外部源提取数据后,我们必须准备文件以存储在数据仓库中。来自多个不同来源的提取数据需要进行更改,转换并准备好相关格式,以便保存以进行查询和分析。
现在,我们将讨论登台区域中发生的三个主要功能。

1)数据提取:此方法必须处理大量数据源。我们必须为每个数据源采用适当的技术。
2)数据转换:众所周知,数据仓库的数据来自许多不同的来源。如果为数据仓库提取数据带来了巨大挑战,那么数据转换甚至会带来巨大挑战。作为数据转换的一部分,我们执行一些单独的任务。
首先,我们清理从每个来源提取的数据。清除可能是纠正拼写错误,或者可能是为缺失的数据元素提供默认值,或者当我们从各种源系统中引入相同数据时消除重复项。
数据组件的标准化是数据转换的很大一部分。数据转换包含多种形式的组合不同来源的数据。我们合并来自单个源记录的数据或来自多个源记录的相关数据部分。
另一方面,数据转换还包含清除无用的源数据并将外包记录分成新的组合。数据分类和合并在数据分级区域中大规模进行。当数据转换函数结束时,我们将收集到一组经过清理,标准化和汇总的集成数据。
3)数据加载:任务的两个不同类别构成了数据加载功能。当我们完成数据仓库的结构和构建并首次投入使用时,我们会将信息初始加载到数据仓库存储中。初始负载会占用大量时间来移动大量数据。
数据存储组件
数据仓库的数据存储是拆分存储库。操作系统的数据存储库通常仅包含当前数据。此外,这些数据存储库还包含高度标准化的结构化数据,以实现快速有效的处理。
信息传递组件
信息传递元素用于启用订阅数据仓库文件并将其根据某些客户指定的调度算法转移到一个或多个目的地的过程。

元数据组件
数据仓库中的元数据等于数据库管理系统中的数据字典或数据目录。在数据字典中,我们保留有关逻辑数据结构的数据,有关记录和地址的数据,有关索引的信息,等等。
数据集市
它包含公司范围内的数据的子集,这些数据对特定的用户组有价值。范围仅限于特定的选定主题。尽管数据仓库行业的发展已使标准和增量数据转储更容易实现,但数据仓库中的数据应该是最新的,但主要不是最新的。数据集市低于数据仓库,通常包含组织。数据仓库的当前趋势是开发具有几个较小的相关数据集市的数据仓库,以用于特定种类的查询和报告。
管理和控制组件
管理和控制元素协调数据仓库内的服务和功能。这些组件控制数据转换以及将数据传输到数据仓库存储中。另一方面,它可简化向客户端的数据传递。它与数据库管理系统配合使用,并授权将数据正确保存在存储库中。它监视信息到暂存方法以及从暂存方法到数据仓库存储本身的移动。
为什么我们需要一个单独的数据仓库?
数据仓库查询很复杂,因为它们涉及汇总级别的大量数据的计算。
它可能需要使用基于多维视图的独特数据组织,访问和实现方法。
在操作数据库中执行OLAP查询会降低功能任务的性能。
数据仓库用于需要大量数据库(包括历史数据)的分析和决策,而这些历史数据库通常不维护。
将操作数据库与数据仓库分开是基于这些系统中数据的不同结构和用途。
由于这两个系统提供不同的功能并且需要不同种类的数据,因此有必要维护单独的数据库。
数据库和数据仓库之间的区别

| Database | Data Warehouse |
|---|---|
| 1. It is used for Online Transactional Processing (OLTP) but can be used for other objectives such as Data Warehousing. This records the data from the clients for history. | 1. It is used for Online Analytical Processing (OLAP). This reads the historical information for the customers for business decisions. |
| 2. The tables and joins are complicated since they are normalized for RDBMS. This is done to reduce redundant files and to save storage space. | 2. The tables and joins are accessible since they are de-normalized. This is done to minimize the response time for analytical queries. |
| 3. Data is dynamic | 3. Data is largely static |
| 4. Entity: Relational modeling procedures are used for RDBMS database design. | 4. Data: Modeling approach are used for the Data Warehouse design. |
| 5. Optimized for write operations. | 5. Optimized for read operations. |
| 6. Performance is low for analysis queries. | 6. High performance for analytical queries. |
| 7. The database is the place where the data is taken as a base and managed to get available fast and efficient access. | 7. Data Warehouse is the place where the application data is handled for analysis and reporting objectives. |