- 数据仓库模式中的键类型
- 数据仓库模式中的键类型(1)
- 数据仓库 (1)
- 数据仓库(1)
- 数据仓库
- 数据仓库
- 数据仓库架构中的键类型(1)
- 数据仓库架构中的键类型
- 数据仓库组件|数据仓库教程(1)
- 数据仓库组件|数据仓库教程
- 数据仓库的属性(1)
- 数据仓库的属性
- 数据仓库的属性
- 数据仓库 - 任何代码示例
- 数据仓库OLAP的类型(1)
- 数据仓库OLAP的类型
- 数据仓库-测试
- 在数据仓库中测试
- 在数据仓库中测试(1)
- 数据仓库-测试(1)
- 数据仓库-模式(1)
- 数据仓库-模式
- 数据仓库-面试问题(1)
- 数据仓库-面试问题
- 数据仓库教程
- 数据仓库教程(1)
- 数据仓库教程
- 数据仓库实现(1)
- 数据仓库实现
📅 最后修改于: 2020-12-30 00:36:45 🧑 作者: Mango
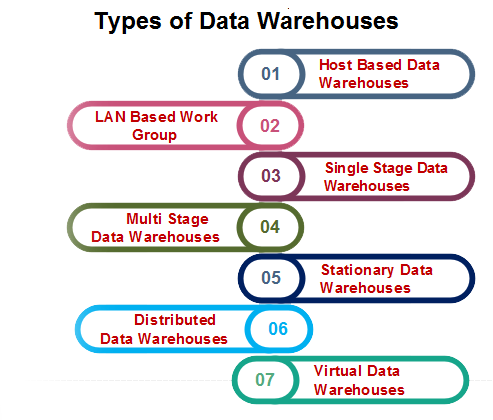
数据仓库的类型
有不同类型的数据仓库,如下所示:
基于主机的数据仓库
可以实现两种类型的基于主机的数据仓库:
- 基于主机的大型机仓库,位于大型数据库上。由诸如IBM System / 390,UNISYS和Data General后续系统之类的强大而可靠的大容量结构以及诸如Sybase,Oracle,Informix和DB2之类的数据库支持。
- 基于主机的LAN数据仓库,可以在中央或从工作组环境中处理数据传递。数据库数据仓库的大小取决于平台。
数据提取和转换工具允许从生产系统中自动提取和清除数据。由于以下原因,不适用于允许查询工具直接访问这些方法类别:
- 大量复杂的仓库查询可能会对面向任务关键事务处理(TP)的应用程序产生太多有害影响。
- 这些TP系统已经在其数据库设计中为交易吞吐量而开发。在所有方法中,数据库都是为最佳查询或事务处理而设计的。复杂的业务查询需要连接许多规范化的表,因此结果性能通常很差,并且查询的构造也很复杂。
- 无法保证两种或两种以上生产方法中的数据将保持一致。
基于主机的(MVS)数据仓库
驻留在MVS上的大容量数据库上的那些数据仓库使用是基于主机的数据仓库类型。 DBMS通常是具有大量旧信息原始资源的DB2,包括VSAM,DB2,平面文件和信息管理系统(IMS)。
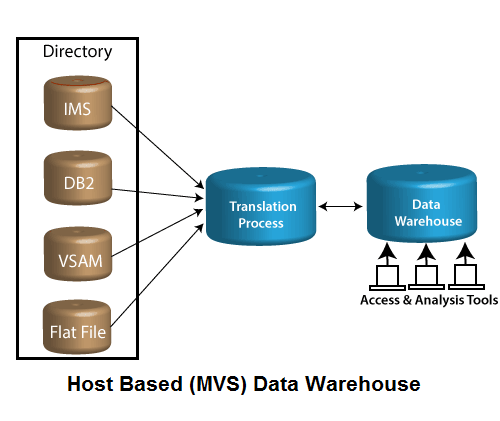
在着手设计,建造和实施这种仓库之前,必须进一步考虑一些因素,因为
- 这样的数据库通常具有非常大的数据存储量。
- 这样的仓库可能需要同时支持MVS和基于客户的报告和查询功能。
- 这些仓库具有复杂的源系统。
- 此类系统需要连续维护,因为它们也必须用于关键任务目标。
为了使此类数据仓库构建成功,通常遵循以下阶段:
- 卸载阶段:它包含选择和清理操作数据。
- 转换阶段:用于将其转换为适当的形式并描述访问和存储它的规则。
- 加载阶段:用于将记录直接移动到DB2表或特定文件中,以将其移动到另一个数据库或非MVS仓库中。
集成的元数据存储库对于任何数据仓库环境都是至关重要的。需要这样的工具才能为仓库记录数据源,数据转换规则和用户区域。它在多个数据源数据库和条件数据仓库的DB2之间提供了动态网络。
元数据存储库是设计,构建和维护数据仓库流程所必需的。它应该能够提供有关数据所在的操作系统和数据仓库中都存在哪些数据的数据。将操作数据映射到仓库字段和最终用户访问技术。查询,报告和维护是此类数据仓库不可或缺的方法。用于DB2的基于MVS的查询和报告工具。
基于主机的(UNIX)数据仓库
Oracle和Informix RDBMS支持此类数据仓库的功能。这两个数据库都可以从基于MVS的数据库以及更多数量的其他基于UNIX的数据库中提取信息。这些类型的仓库与基于主机的MVS数据仓库处于同一阶段。同样,可以创建来自不同网络服务器的数据。由于文件属性一致性在整个网络中很常见。
基于LAN的工作组数据仓库
基于LAN的工作组仓库是用于在LAN环境中构建和维护数据仓库的集成结构。在这个仓库中,我们可以从各种资源中提取信息,并支持多个基于LAN的仓库,通常选择的仓库数据库包括DB2系列,Oracle,Sybase和Informix。 IMS,VSAM,平面文件,MVS和VH也可能很少包含其他数据库。
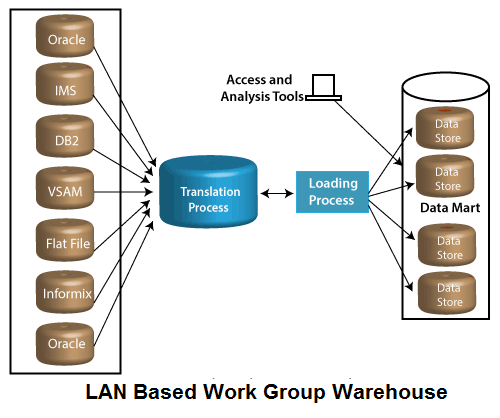
基于LAN的工作组仓库是为工作组环境而设计的,它对于想要建立通常称为数据集市的数据仓库的任何业务组织都是最佳的。这种类型的数据仓库通常需要最少的初始投资和技术培训。
数据交付:使用基于LAN的工作组仓库,客户只需很少的技术知识即可创建和维护自定义供部门,业务部门或工作组使用的数据存储。基于LAN的工作组仓库通过提供对仓库中数据的传输访问权限来确保从公司资源中传递信息。
基于主机的单级(LAN)数据仓库
在基于LAN的数据仓库中,数据交付可以集中处理,也可以从工作组环境进行处理,因此业务组可以满足他们所需的数据处理过程,而不会增加中央IT资源的负担,享受其数据集市的自主权,而无需在其中包含总体数据完整性和安全性企业。
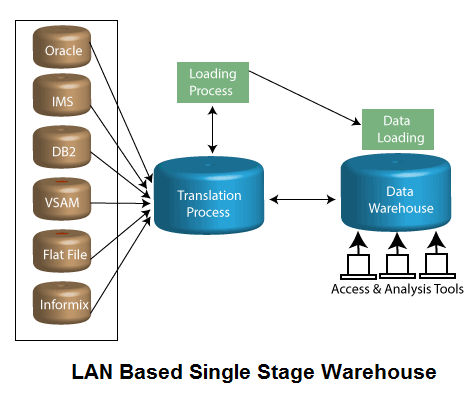
局限性
DBMS和硬件可伸缩性方法通常都限制基于LAN的仓库解决方案。
许多基于LAN的企业尚未实现适当的作业计划,恢复管理,有组织的维护和性能监视方法来提供可靠的仓储解决方案。
通常,这些仓库依赖其他平台进行源记录。建立具有数据完整性,可恢复性和安全性的环境需要仔细的设计,规划和实施。否则,从源到服务器的转换和负载同步可能会导致无数问题。
基于LAN的仓库可提供来自许多资源的数据,这些数据需要最少的初始投资和技术知识。基于LAN的仓库还可以使用复制工具来填充和更新数据仓库。这种类型的仓库可以包括业务视图,历史记录,聚合,版本和异构源支持,例如
- DB2系列
- IMS,VSAM,平面文件[MVS和VM]
单个存储通常会驱动基于LAN的仓库并提供现有的DSS应用程序,从而使业务用户能够在其数据仓库中定位数据。基于LAN的仓库可以为业务用户提供完整的数据到信息解决方案。基于LAN的仓库还可以共享元数据,并具有对业务数据进行分类的功能,并使任何需要它的人都可以使用。
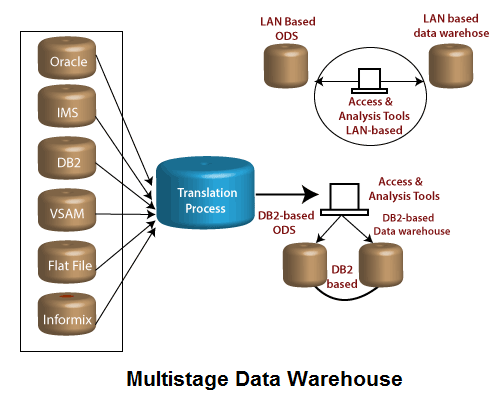
多阶段数据仓库
它指的是通过聚合来分析数据的转换方法的多个阶段。换句话说,在将数据加载到数据仓库之前多次对数据进行分段,首先将数据从源系统中提取到分段区域,然后在更改后被加载到数据仓库,最后再到部门数据集市。
此配置非常适合以下环境,在这些环境中,具有多种能力的最终客户需要访问汇总信息以获取最新的战术决策以及汇总的长期战略决策的可交换记录。取决于数量和自定义要求,运营数据存储(ODS)和数据仓库都可以驻留在基于主机或基于LAN的数据库上。它们包含DB2,Oracle,Informix,IMS,平面文件和Sybase。
通常,ODS仅存储最新记录。数据仓库存储文件的历史计算。首先,两个数据库中的信息将非常相似。例如,新客户的记录将看起来相同。当用户记录发生更改时,OD将被刷新以仅反映最新数据,而数据仓库将包含历史数据和新信息。因此,数据仓库的数量需求将超过ODS加班的数量需求。在实践中达到4:1的比例是不熟悉的。
固定数据仓库
在这种类型的数据仓库中,数据不会从源中更改,如图所示:
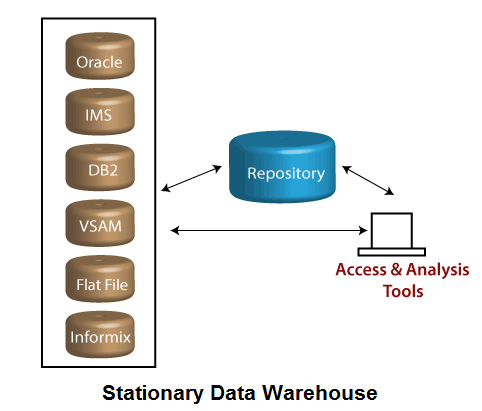
相反,客户可以直接访问数据。对于许多组织而言,访问方式很少,数量问题或公司必需品决定了这种方法。此架构确实会给客户带来一些问题,例如
- 为用户识别信息的位置
- 为客户提供查询不同DBMS的能力,因为它们都是具有单个API的单个DBMS。
- 由于客户将与生产数据存储竞争,因此会影响性能。
这样的仓库可能需要高度专业化和复杂的“中间件”,并且可能需要与客户进行一次交互。这对于设施在生成报告之前为用户显示提取的记录也很重要。在这种环境下,集成的元数据存储库变得绝对必要。
分布式数据仓库
分布式数据仓库的概念表明,存在两种类型的分布式数据仓库及其对本地企业仓库的修改,它们分布在整个企业和全局仓库中,如图所示:
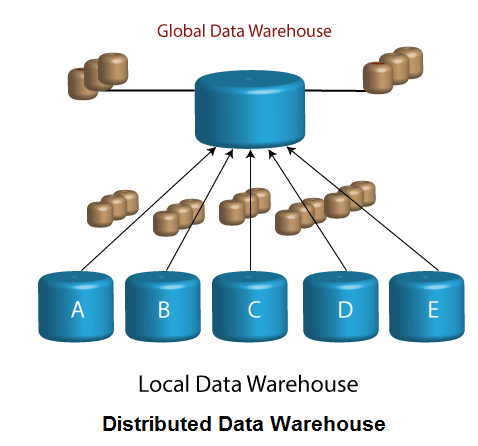
本地数据仓库的特征
- 活动出现在本地级别
- 大量的业务处理
- 本地站点是自治的
- 每个本地数据仓库都有其独特的体系结构和数据内容
- 数据是唯一的,并且仅对本地至关重要
- 记录的多数是本地记录,不能复制
- 本地数据仓库之间的任何数据交集都是偶然的
- 本地仓库服务于不同的技术社区
- 本地数据仓库的范围仅限于本地站点
- 本地仓库还包括历史数据,并且仅在本地站点内集成。
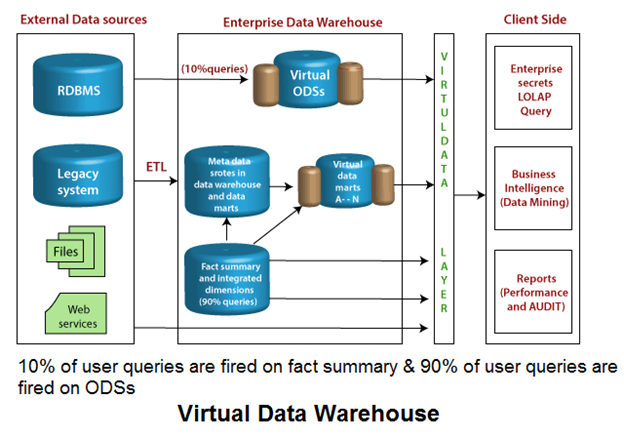
虚拟数据仓库
虚拟数据仓库在以下阶段中创建:
- 安装一组数据方法,数据字典和过程管理工具。
- 培训最终客户。
- 监控DW设施的使用方式
- 根据实际使用情况,物理上创建数据仓库以提供高频结果
该策略定义了允许最终用户使用对数据访问网络实施的任何工具直接访问可操作的数据库。这种方法提供了最大的灵活性,以及必须加载和维护的最少冗余信息。数据仓库是一个好主意,但它很难构建,需要投资。为什么不通过消除元数据和另一个数据库的存储库的转换阶段来使用便宜且快速的方法。这种方法称为“虚拟数据仓库” 。
为此,需要定义四种数据:
- 包含各种数据库定义的数据字典。
- 数据组件之间关系的描述。
- 方法用户的描述将与系统交互。
- 描述做什么和如何做的算法和业务规则。
缺点
- 由于查询与生产记录事务竞争,因此性能可能会下降。
- 没有元数据,没有摘要记录,也没有单独的DSS (决策支持系统)集成或历史记录。必须复制所有查询,这给系统带来了额外的负担。
- 没有刷新过程,导致查询非常复杂。