分组卷积
与 ANN 相比,卷积神经网络在训练图像数据集时非常有助于减少参数,这使得训练中等大小的图像几乎不可能。用于减少修道院中的参数的方法称为过滤器分组。
分组卷积于 2012 年在 AlexNet 论文中首次引入。这种方法背后的主要思想是使用两个 GPU 的有限内存(每个 1.5 GB)来并行训练模型。顺便说一下,模型训练所需的内存不到 3GB。
首先,让我们讨论需要分组卷积的其他一些原因:
- 为了在各种图像数据集上获得良好的训练和测试精度,我们需要构建一个每层具有多个内核的深度神经网络,从而导致每层有多个通道。这导致了更广泛的神经网络。
- 每个内核过滤器对上一层获得的所有特征图进行卷积,从而产生大量卷积,其中一些可能是冗余的。
- 训练更深的模型会很困难,因为在单个 GPU 上拟合这些模型并不容易。即使有可能,我们也可能不得不使用较小的批量大小,这会使整体收敛变得困难。
从以上几点,我们可以说滤波器分组是降低 CNN 复杂度从而促进更大神经网络训练的一个重要方面。
建筑与工作
下面是代表分组卷积的样本。
在滤波器组中,我们考虑了通道维度,即卷积滤波器的第三个维度,随着我们深入卷积,这个维度增加得非常快,从而增加了复杂性。空间维度对复杂性有一定程度的影响,但在更深的层次中,它们并不是真正值得关注的原因。因此,在更大的神经网络中,过滤器组将占主导地位。
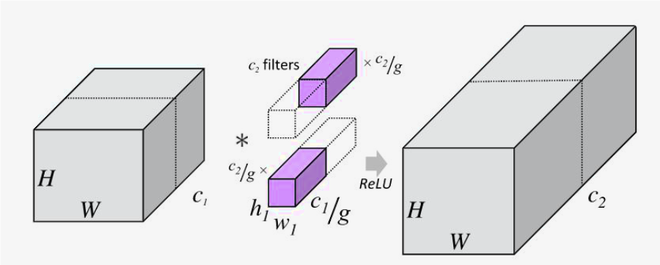
通过将通道数除以一半来描述过滤器分组的图像
在上图中,我们可以看到由一个创建的 2 个过滤器组进行卷积,2 个过滤器组中的每一个都只与前一层的通道维度的一半进行卷积。过滤器组的划分有不同的变体,其中一种变体是对数过滤器分解。
对数分解
这种方法是韩国科学技术院研究人员在题为“Convolution with Logarithmic Filter Groups for Efficient Shallow CNN”的论文中提出的。他们使用非线性对数滤波器分组,并认为它基于滤波器的非线性特性。为了支持他们的主张,他们使用了韦伯-费希纳定律。该定律指出主观感觉的程度与刺激强度的对数成正比,可以用来解释人类的听觉和视觉系统。

对数滤波器卷积
所提出的非线性滤波器分组使用以 2 为底的对数尺度来决定卷积层中每个滤波器组的大小。
让我们考虑一个输入和输出通道深度为 c in和 c out的卷积层。如果滤波器组的数量为 n,则具有对数滤波器分组的卷积层的滤波器形状集将为:
作者还在分组卷积层的输入和输出之间使用了残差身份连接,以构建足够的浅层网络。下面是它的架构:
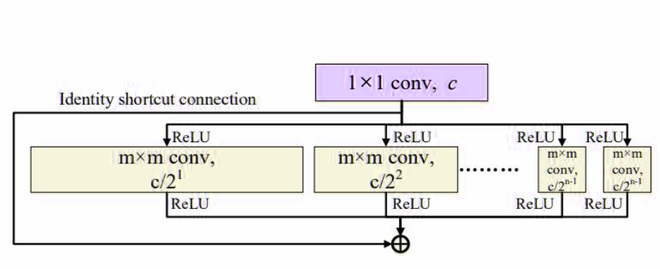
具有残差恒等连接的对数滤波器卷积
结论:
- 提出的滤波器分组方法允许我们通过复制分组卷积来构建足够深和宽的神经网络。
- 如果不是过滤器分组,随着我们进入更深的层次,网络的复杂性会呈指数增长。
- 过滤器分组还有助于促进模型中的并行性。
参考:
- 对数滤波器组论文
- 深网纸