连续核卷积
连续内核卷积是由阿姆斯特丹 Verije 大学的研究人员与阿姆斯特丹大学合作在一篇题为“ CKConv:Continuous Kernel Convolution For Sequential Data ”的论文中提出的。其背后的动机是提出一个模型,该模型使用卷积神经网络和循环神经网络的特性来处理长序列的图像数据。
卷积运算
设 x ∶R → R N c和 ψ ∶ R → R N c是 R 上的向量值信号和核,使得 x = {x c } Nc和 ψ = {ψ c } N C c=1。卷积操作可以定义为:

然而,实际上输入信号 x 是从采样中收集的。因此,输入信号和卷积可以定义为
- 输入信号:
- 卷积:
以t为中心的方程由下式给出:
现在对于连续核卷积,我们将使用卷积核 ψ 作为参数化在一个名为MLP ψ的小型神经网络上的连续函数。它以(t−τ )作为输入并输出卷积核在那个位置ψ(t−τ ) 的值。连续核可以由以下公式表示:
如果采样因子与训练采样因子不同,那么我们可以通过以下方式进行卷积运算:
经常单位
对于输入序列
.循环单位由下式给出:

其中 U、W、V 是单元的输入到隐藏、隐藏到隐藏和隐藏到输出的连接。 h(τ)、y~(τ) 描述了隐藏表示和时间步长 τ 的输出,σ 表示逐点非线性。
现在,我们将上述方程展开为 t 步:

其中 h(−1) 是隐藏表示的初始状态。 h(t) 也可以用以下方式表示:
上述等式为我们提供了以下结论:
- RNN 中的梯度消失和梯度爆炸问题是由过去的 x(t-τ) τ 项乘以有效卷积权重 ψ(τ)=W τ U 引起的。
- 线性循环单元可以定义为输入和指数卷积函数的卷积。
MLP 连续内核
令 {∆t i =(t − τ i )} N i=0 是一个相对位置序列。卷积核 MLP ψ由传统的 L 层神经网络参数化:
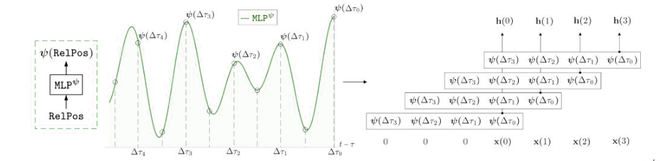
MLP
在哪里,
 用于添加非线性,例如 ReLU。
用于添加非线性,例如 ReLU。
执行
- 在这个实现中,我们将在 sMNIST 数据集上训练 CKconv 模型,对于这个实现,我们将使用谷歌提供给我们的 colaboratory。
Python3
# code credits: https://github.com/dwromero/ckconv
# first, we need to clone the ckconv repository from Github
! git clone https://github.com/dwromero/ckconv
# Now, we need to change the pwd to ckconv directory
cd ckconv
# Before actually train the model,
# we need to first install the required modules and libraries
! pip install -r requirements.txt
# if the above command fails, please make sure that following modules installed using
# command below
pip install ml-collections torchaudio mkl-random sktime wandb
# Now to train the model on sMNIst dataset, run the following commands
! python run_experiment.py --config.batch_size=64 --config.clip=0 \
--config.dataset=MNIST --config.device=cuda --config.dropout=0.1 \
--config.dropout_in=0.1 --config.epochs=200 --config.kernelnet_activation_function=Sine \
--config.kernelnet_no_hidden=32 --config.kernelnet_norm_type=LayerNorm \
--config.kernelnet_omega_0=31.09195739463897 --config.lr=0.001 --config.model=CKCNN \
--config.no_blocks=2 --config.no_hidden=30 --config.optimizer=Adam \
--config.permuted=False --config.sched_decay_factor=5 --config.sched_patience=20 \
--config.scheduler=plateau- 以下是CKCNN在sMNIST数据上的上述训练结果:
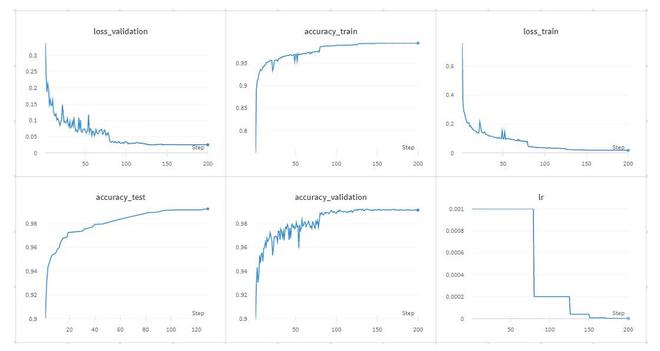
CkConv 训练结果
结论
- Ckconv 能够轻松处理非常复杂的非线性函数。
- 与 RNN 不同,CKConvs 不依赖任何形式的递归来考虑大内存范围,并且具有全局长期依赖性。
- CKCNN 不使用时间反向传播(BPTT)。因此,可以并行训练 CKCNN。
- CKCNN 也可以部署在除训练分辨率以外的分辨率。
参考:
- CKConv 论文