- 关系代数中的查询优化
- 关系代数中的查询优化(1)
- 关系代数的示例查询
- 关系代数查询示例
- 关系代数查询示例
- 关系代数查询示例(1)
- 关系代数的示例查询(1)
- 关系代数查询示例(1)
- 关系代数(1)
- 关系代数
- DBMS关系代数(1)
- DBMS关系代数
- 关系代数中的除法 (1)
- 关系代数中的扩展运算符
- 关系代数中的基本运算符
- 关系代数中的基本运算符(1)
- 代数
- 代数(1)
- 代数 |组 2
- 代数 |组 2(1)
- 代数
- 关系代数中的 SELECT 操作(1)
- 关系代数中的 SELECT 操作
- 关系代数中的 SELECT 操作(1)
- 关系代数中的 SELECT 操作
- 关系代数中的项目运算(1)
- 关系代数中的项目运算
- 关系代数中的项目运算
- 关系代数中的项目运算
📅 最后修改于: 2021-01-07 05:26:10 🧑 作者: Mango
放置查询后,首先会对其进行扫描,解析和验证。然后创建查询的内部表示形式,例如查询树或查询图。然后设计替代的执行策略,以从数据库表中检索结果。为查询处理选择最合适的执行策略的过程称为查询优化。
DDBMS中的查询优化问题
在DDBMS中,查询优化是一项至关重要的任务。由于以下因素,替代策略的数量可能成倍增加,因此复杂性很高:
- 存在许多碎片。
- 片段或表在各个站点中的分布。
- 通讯链接的速度。
- 本地处理能力方面的差异。
因此,在分布式系统中,目标通常是找到一种用于查询处理的良好执行策略,而不是最佳策略。执行查询的时间是以下各项的总和-
- 是时候将查询传达给数据库了。
- 是时候执行本地查询片段了。
- 是时候收集来自不同站点的数据了。
- 是时候向应用程序显示结果了。
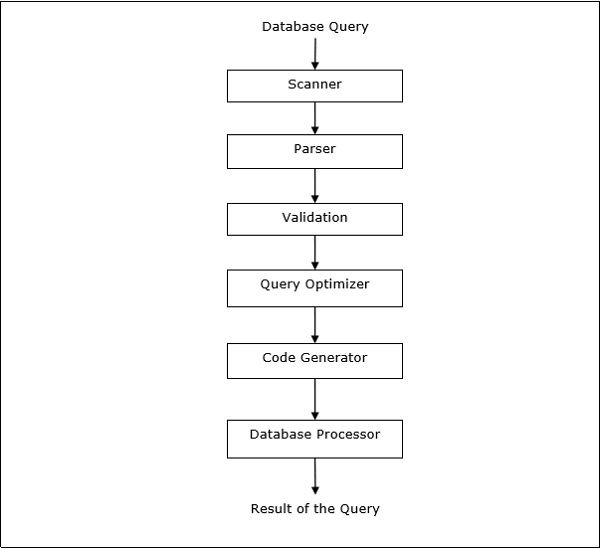
查询处理
查询处理是从查询放置到显示查询结果的所有活动的集合。步骤如下图所示-
关系代数
关系代数定义了关系数据库模型的基本操作集。关系代数运算的序列形成一个关系代数表达式。该表达式的结果表示数据库查询的结果。
基本操作是-
- 投影
- 选拔
- 联盟
- 路口
- 减去
- 加入
投影
投影操作显示表中字段的子集。这给出了表的垂直分区。
关系代数中的语法
$$ \ pi _ {} {()} $$
例如,让我们考虑以下学生数据库-
| Roll_No | Name | Course | Semester | Gender |
| 2 | Amit Prasad | BCA | 1 | Male |
| 4 | Varsha Tiwari | BCA | 1 | Female |
| 5 | Asif Ali | MCA | 2 | Male |
| 6 | Joe Wallace | MCA | 1 | Male |
| 8 | Shivani Iyengar | BCA | 1 | Female |
如果我们想显示所有学生的姓名和课程,我们将使用以下关系代数表达式-
$$ \ pi_ {姓名,课程} {(学生)} $$
选拔
选择操作显示满足某些条件的表的元组的子集。这给出了表的水平分区。
关系代数中的语法
$$ \ sigma _ {} {()} $$
例如,在“学生”表中,如果我们想显示所有选择了MCA课程的学生的详细信息,我们将使用以下关系代数表达式-
$$ \ sigma_ {Course} = {\ small“ BCA”} ^ {(STUDENT)} $$
投影和选择操作的结合
对于大多数查询,我们需要组合投影和选择操作。编写这些表达式有两种方法-
- 使用顺序的投影和选择操作。
- 使用重命名操作生成中间结果。
例如,要显示BCA课程的所有女学生的姓名-
- 使用投影和选择操作序列的关系代数表达式
$$ \ pi_ {名称}(\ sigma_ {性别= \小“女性” AND \:课程= \小“ BCA”} {(学生)})$$
- 使用重命名操作生成中间结果的关系代数表达式
$$ FemaleBCAS学生\ leftarrow \ sigma_ {性别= \ small“女性” AND \:课程= \ small“ BCA”} {(学生)} $$
$$ Result \ leftarrow \ pi_ {Name} {(FemaleBCAStudent)} $$
联盟
如果P是一个运算的结果,而Q是另一个运算的结果,则P和Q的并集($ p \ cup Q $)是P中或Q中或两者中都没有重复的所有元组的集合。
例如,要显示所有在第一学期或在BCA课程中的学生-
$$ Sem1学生\ leftarrow \ sigma_ {Semester = 1} {(STUDENT)} $$
$$ BCAS学生\ leftarrow \ sigma_ {课程= \ small“ BCA”} {(学生)} $$
$$结果\ leftarrow Sem1学生\ cup BCAS学生$$
路口
如果P是一个运算的结果,而Q是另一个运算的结果,则P与Q的交集($ p \ cap Q $)是同时位于P和Q中的所有元组的集合。
例如,给定以下两个模式-
雇员
| EmpID | Name | City | Department | Salary |
项目
| PId | City | Department | Status |
要显示项目所在的所有城市的名称以及一名雇员所在的城市,请执行以下操作:
$$ CityEmp \ leftarrow \ pi_ {City} {(EMPLOYEE)} $$
$$ CityProject \ leftarrow \ pi_ {City} {(PROJECT)} $$
$$结果\ leftarrow CityEmp \ cap CityProject $$
减去
如果P是一个运算的结果,而Q是另一个运算的结果,则P-Q是在P中而不在Q中的所有元组的集合。
例如,列出所有没有正在进行的项目的部门(状态为正在进行的项目)-
$$ AllDept \ leftarrow \ pi_ {部门} {(员工)} $$
$$ ProjectDept \ leftarrow \ pi_ {部门}(\ sigma_ {状态= \ small“进行中”} {(项目)})$$
$$ Result \ leftarrow AllDept-ProjectDept $$
加入
连接操作将两个不同表的相关元组(查询结果)组合到一个表中。
例如,在银行数据库中考虑两个模式,客户模式和分支机构,如下所示:
顾客
| CustID | AccNo | TypeOfAc | BranchID | DateOfOpening |
科
| BranchID | BranchName | IFSCcode | Address |
列出员工详细信息以及分支机构详细信息-
$$ Result \ leftarrow客户\ bowtie_ {Customer.BranchID = Branch.BranchID} {BRANCH} $$
将SQL查询转换为关系代数
在优化之前,SQL查询会转换为等效的关系代数表达式。首先将查询分解为较小的查询块。这些块被转换为等效的关系代数表达式。优化包括每个块的优化,然后是整个查询的优化。
例子
让我们考虑以下架构-
雇员
| EmpID | Name | City | Department | Salary |
项目
| PId | City | Department | Status |
作品
| EmpID | PID | Hours |
例子1
为了显示所有薪水少于平均工资的雇员的详细信息,我们编写SQL查询-
SELECT * FROM EMPLOYEE
WHERE SALARY < ( SELECT AVERAGE(SALARY) FROM EMPLOYEE ) ;
此查询包含一个嵌套的子查询。因此,这可以分为两个部分。
内块是-
SELECT AVERAGE(SALARY)FROM EMPLOYEE ;
如果此查询的结果为AvgSal,则外部块为-
SELECT * FROM EMPLOYEE WHERE SALARY < AvgSal;
内部块的关系代数表达式-
$$ AvgSal \ leftarrow \ Im_ {AVERAGE(Salary)} {EMPLOYEE} $$
外块的关系代数表达式-
$$ \ sigma_ {Salary} {EMPLOYEE} $$
例子2
为了显示员工’Arun Kumar’的所有项目的项目ID和状态,我们编写SQL查询-
SELECT PID, STATUS FROM PROJECT
WHERE PID = ( SELECT FROM WORKS WHERE EMPID = ( SELECT EMPID FROM EMPLOYEE
WHERE NAME = 'ARUN KUMAR'));
该查询包含两个嵌套的子查询。因此,可以分为以下三个部分:
SELECT EMPID FROM EMPLOYEE WHERE NAME = 'ARUN KUMAR';
SELECT PID FROM WORKS WHERE EMPID = ArunEmpID;
SELECT PID, STATUS FROM PROJECT WHERE PID = ArunPID;
(这里ArunEmpID和ArunPID是内部查询的结果)
三个块的关系代数表达式为-
$$ ArunEmpID \ leftarrow \ pi_ {EmpID}(\ sigma_ {Name = \ small“ Arun Kumar”} {(EMPLOYEE)})$$
$$ ArunPID \ leftarrow \ pi_ {PID}(\ sigma_ {EmpID = \ small“ ArunEmpID”} {(WORKS)})$$
$$ Result \ leftarrow \ pi_ {PID,Status}(\ sigma_ {PID = \ small“ ArunPID”} {(PROJECT)})$$
关系代数算子的计算
关系代数运算符的计算可以用许多不同的方式来完成,每种选择都称为访问路径。
计算选择取决于三个主要因素-
- 操作员类型
- 有效内存
- 磁盘结构
执行关系代数运算的时间为-
- 是时候处理元组了。
- 是时候从磁盘到内存获取表的元组了。
由于处理元组的时间比从存储中获取元组的时间小得多,尤其是在分布式系统中,因此磁盘访问通常被视为计算关系表达式成本的度量。
选择计算
选择操作的计算取决于选择条件的复杂性以及表属性上索引的可用性。
以下是取决于索引的计算替代方案-
-
无索引-如果表未排序且没有索引,则选择过程涉及扫描表的所有磁盘块。将每个块放入存储器,并检查该块中的每个元组,以查看其是否满足选择条件。如果满足条件,则显示为输出。这是最昂贵的方法,因为每个元组都被放入内存中,并且每个元组都经过处理。
-
B +树索引-大多数数据库系统都基于B +树索引。如果选择条件是基于字段的,而字段是此B +树索引的关键,则该索引将用于检索结果。但是,处理条件复杂的选择语句可能涉及大量的磁盘块访问,并且在某些情况下会完全扫描表。
-
哈希索引-如果在选择条件下使用哈希索引并且使用其键字段,则使用哈希索引检索元组将变得很简单。哈希索引使用哈希函数来查找存储与该哈希值相对应的键值的存储桶的地址。为了在索引中找到键值,执行哈希函数并找到存储桶地址。搜索存储桶中的键值。如果找到匹配项,则将实际的元组从磁盘块中提取到内存中。
联接计算
当我们要连接两个表(例如P和Q)时,必须将P中的每个元组与Q中的每个元组进行比较,以测试连接条件是否得到满足。如果满足条件,则将相应的元组连接起来,从而消除重复的字段并附加到结果关系中。因此,这是最昂贵的操作。
计算联接的常见方法是-
嵌套循环法
这是常规的连接方法。可以通过以下伪代码(表P和Q,具有元组tuple_p和tuple_q以及连接属性a)进行说明-
For each tuple_p in P
For each tuple_q in Q
If tuple_p.a = tuple_q.a Then
Concatenate tuple_p and tuple_q and append to Result
End If
Next tuple_q
Next tuple-p
排序合并方法
在这种方法中,将根据联接属性对两个表进行单独排序,然后将排序后的表合并。由于记录的数量非常多并且无法容纳在内存中,因此采用了外部排序技术。对各个表进行排序后,将每个排序后的表的一页带到内存中,并根据连接属性进行合并,并写入连接的元组。
哈希联接方法
该方法包括两个阶段:划分阶段和探测阶段。在分区阶段,表P和Q分为两组不相交的分区。确定通用哈希函数。此哈希函数用于将元组分配给分区。在探测阶段,将P分区中的元组与Q对应分区的元组进行比较。如果它们匹配,则将它们写出。