R 编程中的 K-NN 分类器
K-Nearest Neighbor 或 K-NN 是一种监督非线性分类算法。 K-NN 是一种非参数算法,即它不对基础数据或其分布做出任何假设。它是最简单和广泛使用的算法之一,它依赖于它的 k 值(邻居),并发现它在金融行业、医疗保健行业等许多行业中都有应用。
理论
在 KNN 算法中,K 指定了邻居的数量,其算法如下:
- 选择邻居的数量 K。
- 根据距离取未知数据点的K个最近邻。
- 在K-neighbors中,统计每个类别的数据点数。
- 将新数据点分配给一个类别,您在该类别中计算了最多的邻居。
对于最近邻分类器,两点之间的距离以欧几里得距离的形式表示。
例子:
考虑一个包含红色和蓝色两个特征的数据集,我们对它们进行分类。这里 K 是 5,即我们根据欧几里得距离考虑 5 个邻居。
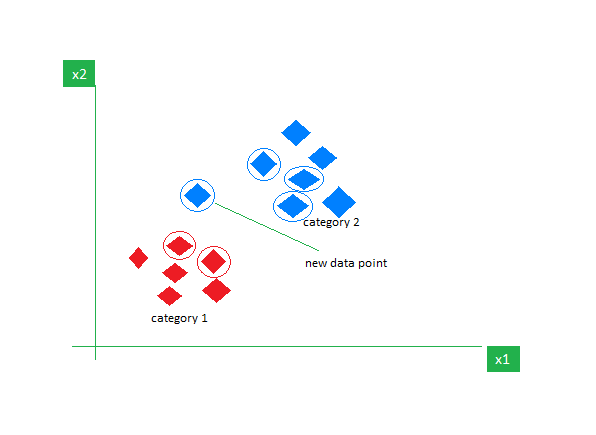
因此,当一个新的数据点进入时,在 5 个邻居中,3 个是蓝色的,2 个是红色的。我们将新数据点分配给具有最多邻居的类别,即蓝色。
数据集
Iris数据集由来自 3 种鸢尾花(Iris setosa、Iris virginica、Iris versicolor)中的每一种的 50 个样本和英国统计学家和生物学家 Ronald Fisher 在其 1936 年论文 The use of multiple measurement in taxonomic questions 中引入的多元数据集组成。从每个样本中测量了四个特征,即萼片和花瓣的长度和宽度,基于这四个特征的组合,Fisher 开发了一个线性判别模型来区分物种。
# Loading data
data(iris)
# Structure
str(iris)
在数据集上执行 K 最近邻
在包含 11 个人和 6 个变量或属性的数据集上使用 K-Nearest Neighbor 算法。
# Installing Packages
install.packages("e1071")
install.packages("caTools")
install.packages("class")
# Loading package
library(e1071)
library(caTools)
library(class)
# Loading data
data(iris)
head(iris)
# Splitting data into train
# and test data
split <- sample.split(iris, SplitRatio = 0.7)
train_cl <- subset(iris, split == "TRUE")
test_cl <- subset(iris, split == "FALSE")
# Feature Scaling
train_scale <- scale(train_cl[, 1:4])
test_scale <- scale(test_cl[, 1:4])
# Fitting KNN Model
# to training dataset
classifier_knn <- knn(train = train_scale,
test = test_scale,
cl = train_cl$Species,
k = 1)
classifier_knn
# Confusiin Matrix
cm <- table(test_cl$Species, classifier_knn)
cm
# Model Evaluation - Choosing K
# Calculate out of Sample error
misClassError <- mean(classifier_knn != test_cl$Species)
print(paste('Accuracy =', 1-misClassError))
# K = 3
classifier_knn <- knn(train = train_scale,
test = test_scale,
cl = train_cl$Species,
k = 3)
misClassError <- mean(classifier_knn != test_cl$Species)
print(paste('Accuracy =', 1-misClassError))
# K = 5
classifier_knn <- knn(train = train_scale,
test = test_scale,
cl = train_cl$Species,
k = 5)
misClassError <- mean(classifier_knn != test_cl$Species)
print(paste('Accuracy =', 1-misClassError))
# K = 7
classifier_knn <- knn(train = train_scale,
test = test_scale,
cl = train_cl$Species,
k = 7)
misClassError <- mean(classifier_knn != test_cl$Species)
print(paste('Accuracy =', 1-misClassError))
# K = 15
classifier_knn <- knn(train = train_scale,
test = test_scale,
cl = train_cl$Species,
k = 15)
misClassError <- mean(classifier_knn != test_cl$Species)
print(paste('Accuracy =', 1-misClassError))
# K = 19
classifier_knn <- knn(train = train_scale,
test = test_scale,
cl = train_cl$Species,
k = 19)
misClassError <- mean(classifier_knn != test_cl$Species)
print(paste('Accuracy =', 1-misClassError))
输出:
- 模型分类器_knn(k=1):
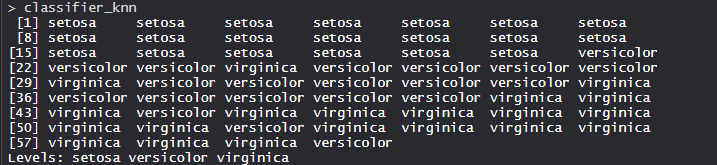
KNN 模型配有训练、测试和 k 值。此外,模型中还安装了分类器物种特征。
- 混淆矩阵:
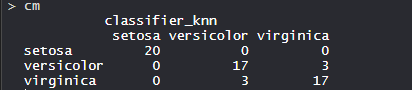
因此,20 个 Setosa 被正确归类为 Setosa。在 20 个 Versicolor 中,17 个 Versicolor 被正确归类为 Versicolor,3 个被归类为Virginica。在 20 个Virginica 中,17 个 virginica 被正确归类为 virginica,3 个被归类为 Versicolor。
- 模型评估:
(k=1)
该模型在 k 为 1 时达到了 90% 的准确率。
(K=3)

该模型在 k 为 3 时达到了 88.33% 的准确率,低于 k 为 1 时的准确率。
(K=5)

该模型在 k 为 5 时达到了 91.66% 的准确率,高于 k 为 1 和 3 时的准确率。
(K=7)

该模型在 k 为 7 时达到了 93.33% 的准确率,高于 k 为 1、3 和 5 时的准确率。
(K=15)

该模型在 k 为 15 时达到了 95% 的准确率,高于 k 为 1、3、5 和 7 时的准确率。
(K=19)

该模型在 k 为 19 时达到了 95% 的准确度,比 k 为 1、3、5 和 7 时的准确率更高。当 k 为 15 时,它的准确度相同,这意味着现在增加 k 值不会影响准确度。
因此,K 最近邻算法在业界被广泛使用。