- Teradata-体系结构
- Teradata-体系结构(1)
- Teradata表
- Teradata宏
- Teradata
- Teradata-表
- Teradata(1)
- Teradata-宏
- Teradata-宏(1)
- Teradata
- Teradata
- Teradata-表(1)
- Teradata宏(1)
- Teradata(1)
- Teradata表(1)
- Teradata子字符串(1)
- Teradata子字符串
- Teradata-安装
- Teradata-安装(1)
- Teradata安装(1)
- Teradata安装
- MySQL的体系结构
- MySQL的体系结构(1)
- Teradata-表类型(1)
- Teradata表类型(1)
- Teradata-表类型
- Teradata表类型
- Teradata主索引(1)
- Teradata-主索引(1)
📅 最后修改于: 2021-01-11 11:11:40 🧑 作者: Mango
Teradata架构
Teradata的体系结构是大规模并行处理体系结构。 Teradata系统具有四个组件。
- 解析引擎
- 网络
- 功放
- 磁碟

根据Teradata系统的主要函数,可以将体系结构分为两部分,例如:
- 储存架构
- 检索架构
储存架构
存储体系结构由Teradata体系结构的以上两个组件组成。当客户端运行查询以插入记录时,解析引擎会将文件发送到BYNET。 BYNET检索文件并将行发送到目标AMP。 AMP将这些记录存储在其磁盘上。
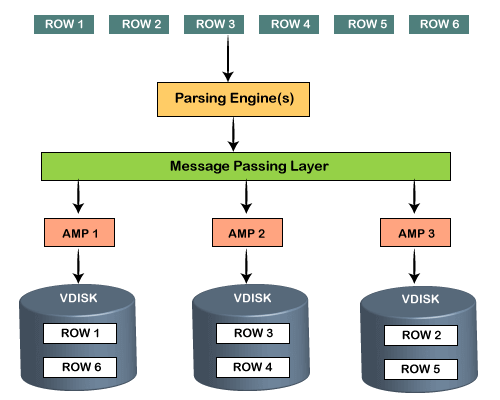
1.解析引擎
当用户触发SQL查询时,它首先连接到解析引擎。在这里完成了诸如计划数据并将数据分发到AMPS的过程。它为查询执行找到了最佳的最佳计划。解析引擎执行以下过程,例如:
- 解析器:解析器检查语法,如果为true,则将查询转发到会话处理程序。
- 会话处理程序:它将执行所有安全检查,例如检查日志凭证以及用户是否具有执行查询的权限。
- 优化器:它找出执行查询的最佳方案。
- 分派器:分派器将查询转发给AMP。
2. AMP
访问模块处理器是通过BYNET连接到PE的虚拟处理器。每个AMP都有其磁盘,并允许在其磁盘中进行读写。这被称为“共享架构”。
触发查询后, Teradata会在所有AMP上分配表的行。 AMP通过以下步骤执行所有SQL请求,例如:
- 锁定桌子。
- 执行请求的操作。
- 结束交易。
检索架构
该体系结构部分包括扩孔Teradata体系结构的两个组件。当客户端运行查询以检索记录时,解析引擎会将请求发送到BYNET。 BYNET将检索请求发送到适当的AMP。然后,AMP并行搜索其磁盘,并确定所需的记录并转发到BYNET。 BYNET将记录发送到解析引擎,解析引擎再将其发送到客户端。
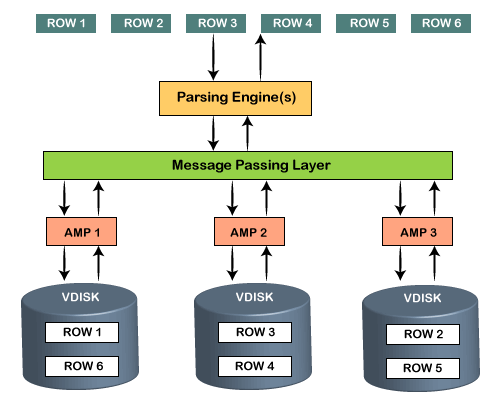
1. BYNET
BYNET充当PE和AMP之间的通道。 Teradata中的“ BYNET 0”和“ BYNET 1”中有两个BYNET。
- 如果一个BYNET失败,则第二个BYNET可以代替它。
- 当数据很大时,两个BYNET都可以正常工作,从而改善了PE和AMP之间的通信,从而简化了过程。
2.磁盘
Teradata为每个AMP提供了一组虚拟磁盘。每个AMP的存储区域称为虚拟磁盘或虚拟磁盘。以下是执行查询的以下步骤,例如:
步骤1:用户提出要发送到PE的问题。
步骤2: PE检查安全性和语法,并找出执行查询的最佳方案。
步骤3:表行分布在AMP上,并且从磁盘中检索数据。
步骤4: AMP通过BYNET将数据发送回PE。
步骤5: PE将数据返回给用户。