毫升 |用于评估聚类性能的 V-Measure
任何聚类技术的主要缺点之一是难以评估其性能。为了解决这个问题,开发了V-Measure 度量。
V-Measure 的计算首先需要计算两项:-
- 同质性:完全同质的聚类是每个聚类具有属于同一类标签的数据点的聚类。同质性描述了聚类算法与这种完美的接近程度。
- 完整性:完全完整的聚类是将属于同一类的所有数据点聚类到同一个聚类中。完整性描述了聚类算法与此完美的接近程度。
平凡同质性:集群的数量等于数据点的数量并且每个点恰好在一个集群中的情况。这是同质性最高而完整性最低的极端情况。

琐碎的完整性:所有数据点都聚集到一个集群中的情况。这是同质性最小而完整性最大的极端情况。

假设上图中的每个数据点都属于平凡同质性和平凡完备性的不同类别标签。
注意:术语同质性不同于完整性,因为在谈论同质性时,基本概念是各个集群的基本概念,我们检查每个集群中的每个数据点是否具有相同的类标签。在谈论完整性时,基本概念是各个类标签,我们检查每个类标签的数据点是否在同一个集群中。
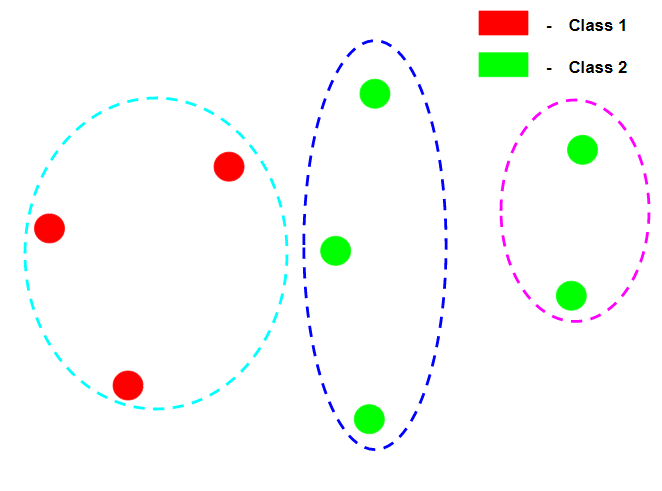
在上图中,聚类是完全同质的,因为在每个聚类中,数据点都属于同一类标签,但它并不完整,因为并非同一类标签的所有数据点都属于同一类标签。

在上图中,由于同一类标签的所有数据点都属于同一个集群,所以聚类是完全完整的,但由于第一个集群包含许多类标签的数据点,所以它不是同质的。
让我们假设有 N 个数据样本、C 个不同的类别标签、K 个聚类和 属于 c 类和集群 k 的数据点的数量。那么同质性 h 由以下给出:-
属于 c 类和集群 k 的数据点的数量。那么同质性 h 由以下给出:-

在哪里

和

完整性 c 由以下给出:-

在哪里

和

因此加权 V-Measure  由以下给出:-
由以下给出:-

因素 可以调整以支持聚类算法的同质性或完整性。
可以调整以支持聚类算法的同质性或完整性。
这个评估指标的主要优点是它独立于类标签的数量、集群的数量、数据的大小和使用的聚类算法,是一个非常可靠的指标。
以下代码将演示如何计算聚类算法的 V-Measure。使用的数据是检测信用卡欺诈,可以从 Kaggle 下载。使用的聚类算法是高斯混合模型的变分贝叶斯推理。
第 1 步:导入所需的库
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import v_measure_score
第 2 步:加载和清理数据
# Changing the working location to the location of the file
cd C:\Users\Dev\Desktop\Kaggle\Credit Card Fraud
# Loading the data
df = pd.read_csv('creditcard.csv')
# Separating the dependent and independent variables
y = df['Class']
X = df.drop('Class', axis = 1)
X.head()

第 3 步:构建不同的聚类模型并比较它们的 V-Measure 分数
在这一步中,将构建 5 个不同的 K-Means 聚类模型,每个模型将数据聚类到不同数量的聚类中。
# List of V-Measure Scores for different models
v_scores = []
# List of different types of covariance parameters
N_Clusters = [2, 3, 4, 5, 6]
a) n_clusters = 2
# Building the clustering model
kmeans2 = KMeans(n_clusters = 2)
# Training the clustering model
kmeans2.fit(X)
# Storing the predicted Clustering labels
labels2 = kmeans2.predict(X)
# Evaluating the performance
v_scores.append(v_measure_score(y, labels2))
b) n_clusters = 3
# Building the clustering model
kmeans3 = KMeans(n_clusters = 3)
# Training the clustering model
kmeans3.fit(X)
# Storing the predicted Clustering labels
labels3 = kmeans3.predict(X)
# Evaluating the performance
v_scores.append(v_measure_score(y, labels3))
c) n_clusters = 4
# Building the clustering model
kmeans4 = KMeans(n_clusters = 4)
# Training the clustering model
kmeans4.fit(X)
# Storing the predicted Clustering labels
labels4 = kmeans4.predict(X)
# Evaluating the performance
v_scores.append(v_measure_score(y, labels4))
d) n_clusters = 5
# Building the clustering model
kmeans5 = KMeans(n_clusters = 5)
# Training the clustering model
kmeans5.fit(X)
# Storing the predicted Clustering labels
labels5 = kmeans5.predict(X)
# Evaluating the performance
v_scores.append(v_measure_score(y, labels5))
e) n_clusters = 6
# Building the clustering model
kmeans6 = KMeans(n_clusters = 6)
# Training the clustering model
kmeans6.fit(X)
# Storing the predicted Clustering labels
labels6 = kmeans6.predict(X)
# Evaluating the performance
v_scores.append(v_measure_score(y, labels6))
第 4 步:可视化结果并比较性能
# Plotting a Bar Graph to compare the models
plt.bar(N_Clusters, v_scores)
plt.xlabel('Number of Clusters')
plt.ylabel('V-Measure Score')
plt.title('Comparison of different Clustering Models')
plt.show()
